写在前面: 我是
「nicedays」,一枚喜爱做特效,听音乐,分享技术的大数据开发猿。这名字是来自world order乐队的一首HAVE A NICE DAY。如今,走到现在很多坎坷和不顺,如今终于明白nice day是需要自己赋予的。
白驹过隙,时光荏苒,珍惜当下~~
写博客一方面是对自己学习的一点点总结及记录,另一方面则是希望能够帮助更多对大数据感兴趣的朋友。如果你也对大数据与机器学习感兴趣,可以关注我的动态https://blog.csdn.net/qq_35050438,让我们一起挖掘数据与人工智能的价值~
文章目录
一:MapReduce?Map and Reduce?
前言: 对于MapReduce,每次刷一遍都会感慨,究竟是谁想出如此巧妙的处理数据的方式,虽然现在它的使用不如以前那么广泛了,但是它的核心思想永远不会被淘汰,真的是非常的巧妙。
不仅运用了“分而治之”,也巧妙的运用了映射和函数处理的思想,03年解决了我们大数据集处理的困扰。
二:MapReduce究竟是什么?:
分治
对,我觉着它的本质就是分治, MapReduce源于Google一篇论文,它充分借鉴了分而治之的思想,将一个数据处理过程拆分为主要的Map(映射)与Reduce(化简)两步
如果用表达式表示,其过程如下式所示 :
{Keyl,Value1}——>{Key2, List}——>{Key3, Value3}
HDFS机制–VS–B+树机制:
我们了解了它的基本思想,很显然我们需要分布式存储系统来契合它,
为什么我们 不用传统的RDBMS数据库集群对大数据进行批量分析呢?
我们先了解一下MapReduce的特点:
MapReduce的天然特点:
- MapReduce比较适合以批处理的方式处理需要分析整个数据集的问题。
- MapReduce 适合一次写入、多次读取数据的应用。
- 同时Mapreduce很适合处理非结构化的数据,因为它是等到数据在进行处理的时候才将其结构进行解释分析,而且不是数据固有的属性关系,而是一种抽象的关系,不像关系性数据库为了存储数据把关系和完整性做到规范。
- 而且MapReduce由于基于分布式,它的上限很高,当集群数量增大,它的运算速度就会有提升。
HDFS对于MapRedcue的契合:
- 天然分布式的架构
- 可以存入非结构化数据
- 对于批存储友好,对于持续更新读写,并不友好。
传统RDBMS的局限性:
因为磁盘的发展趋势:寻址时间的提高 远远慢于传输速率的提高。寻址是将磁头移动到特定磁盘位置进行读写操作的过程。它是导致磁盘操作延迟的主要原因,而传输速率取决于磁盘的带宽。
而作为关系型数据库的代表mysql,由于底层是B+树,在面对大量数据集的时候包含着大量磁盘寻址的时间(相较于流式数据读取),同时,数据库系统每次都需要更新大量数据记录时,B+树的(排序/合并)操作相较于mapreduce会浪费大量的时间(如果只是小部分更新,B+树更有优势)。
- 而RDBMS适用于 “点查询”(point query)和 更新,数据集被索引后,数据库系统能够提供低延迟的数据检索和快速的少量数据更新,
- 因此关系型数据库更适合持续更新的数据集。
三:MapReduce怎么工作呢?:
抛开硬件其实就做了两件事:
- 将数据
处理成适合我统计的样子 统计得出结果
1.MapReduce处理流程的简单概括:
先简单的大致概括一下mapreduce的流程,之后会再细分

是不是有点模糊?我们看看具体的它在干什么?
2.MapReduce完整详细全流程:
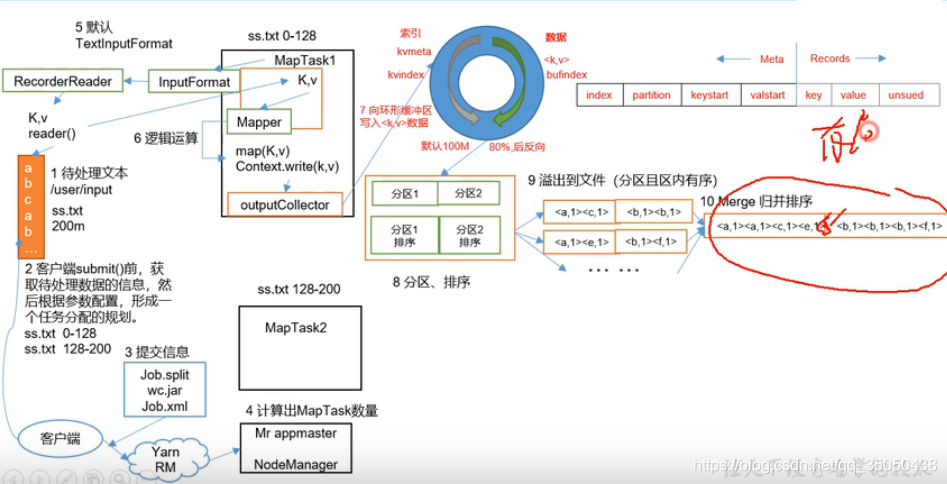
第一步: 我们假设有一个待处理的文本260M——>我们首先客户端submit提交流程,获取已经写好的处理数据用到的jar包,一些执行任务的默认的配置文件xml,和分片信息。
针对分片信息如何获取:调用getSplit(),形成一个按照HDFS块大小的(切片)方法,并将其逻辑分片,所谓逻辑分片,它内部根本没分,它只是调取了文件的大小路径等信息,判断我需要的分片数量,和我应该分片的文件路径,给出分片大小的一些信息后, 将其数组排序后发给yarn。
一般的分片规则是按块大小分,同时也会考虑到回车符划分的方式,并且分的文件只有大于对应块大小的1.1倍,则最后的剩余的小文件才会独立存在。
第二步: YARN(RM)拿到切片信息nodemanager计算出maptask数量,(一个split生成一个maptask任务),maptask拿到appmaster分发下来的代码块进行工作。
第三步: maptask调用inputformat生成一个recorderReader,recordreader负责把maptask的一个切片处理成k,v值,交给maptask的mapper,
第四步: mapper里的逻辑处理完后,context.write(k,v),写给outputCollector,然后它传给环形缓冲区,
第五步: 缓冲区总有一天会满,达到它的80%,开始不断进行溢写,到那时在溢写前会先在内存进行分区来确定最后被传到几个对应的reduce服务器上,再进行快排使其有序,满了之后溢写到磁盘上,形成文件。
第六步: 当数据全部拿到后,因为数据量较大,不能在内存里排序,在磁盘对key归并排序,然后变成了按key有序,与此同时自然而然就完成了分组。
第七步: 现在多个maptask都进行各自的归并有序得到一组数据后,分别去迁移到对应的reducetask去进行任务,由于reducetask收到的数据可能是多个maptask传过来的,所以以此再次进行一次归并排序,得到了有序的相同key不同values,交给redeucer,开发人员编写统计的逻辑处理后。
第八步: reducer通过context write(k,v)交给outputformat,opf生成recordwriter,然后write输出结果。
3.MapReduce的时候Yarn在做什么?:
MapReduce的数据是从HDFS上来的,处理数据计算时,也是在HDFS上的,我们需要
通过yarn资源调度器,来让MapReduce在HDFS上更好的完成任务。
同时yarn也是2.0从mapReduce中分离出来的,了解它可以更好地了解mapReduce
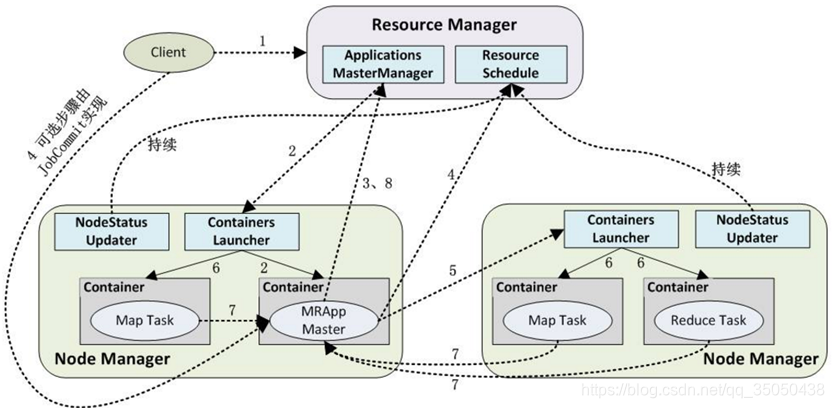
第一步: 用户向yarn提交已经写好的MapReduce程序,yarn的RM与多个NM保持心跳----------在每个DN上的NM定时传递自己的当前节点状态数据给RM管理。Client会拿到
第二步: RM收到Client的 Job提交请求,寻找空闲的DN,将任务给其中一个DN,设为主DN,主DN在Container处开启MRAppMaster程序,进行管理计算操作。
第三步: 但是由于HDFS的数据是根据分块来存储的,毫无规律。当我们需要使用其他节点的块的数据时,需要MRAppMaster程序,通过RPC向RM以 轮询 的方式对对应的task申请拉取资源的权限,得到权限后,
第四步: AM得到资源权限后,AppMaster将对应任务的启动信息和资源和代码块放在 ContainerLaunchContext ,与对应的NM的ContainersLauncher通信传递数据,并通知它让它启动对应的任务。
第五步: 任务计算过程中,每个任务也会通过rpc协议向AM汇报自己的状态和进度,让AM随时掌握各个任务的运行状态,从而在任务失败时重新启动任务。AM最后获得所有节点传回的结果后,传给RM。
到reduceTask时,有的时候数据往往需要其他的container的maptask的数据,就需要通知appmaster进行拉取操作,这就是shuffle操作。
4.从执行源码中更进一步去理解:
Job任务提交做了些啥:
任务启动后按照以下方法顺序执行,我对重要的部分加了自己的注释:
可以更深刻的去理解它到底在做什么
waitforcompletion()
public boolean waitForCompletion(boolean verbose
) throws IOException, InterruptedException,
ClassNotFoundException {
// 定义过job后就是define状态
if (state == JobState.DEFINE) {
// 提交的方法
submit();
}
if (verbose) {
monitorAndPrintJob();
} else {
// get the completion poll interval from the client.
int completionPollIntervalMillis =
Job.getCompletionPollInterval(cluster.getConf());
while (!isComplete()) {
try {
Thread.sleep(completionPollIntervalMillis);
} catch (InterruptedException ie) {
}
}
}
return isSuccessful();
}
submit()
// submit具体方法
public void submit()
throws IOException, InterruptedException, ClassNotFoundException {
// 再次确认job状态
ensureState(JobState.DEFINE);
// 将旧的api封装成新的api,兼容旧代码
setUseNewAPI();
// 连接集群
connect();
// 拿到任务提交人,进行提交任务
final JobSubmitter submitter =
getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
return submitter.submitJobInternal(Job.this, cluster);
}
});
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
}
// connect具体方法
private synchronized void connect()
throws IOException, InterruptedException, ClassNotFoundException {
// 没有集群时生成集群
if (cluster == null) {
// 做判断究竟是本地的还是yarn的集群,来新建对应的集群
cluster =
ugi.doAs(new PrivilegedExceptionAction<Cluster>() {
public Cluster run()
throws IOException, InterruptedException,
ClassNotFoundException {
return new Cluster(getConfiguration());
}
});
}
}
submitJobInternal()
// 通过任务提交人提交状态,内部提交job
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException {
// validate the jobs output specs
// 检查
checkSpecs(job);
Configuration conf = job.getConfiguration();
addMRFrameworkToDistributedCache(conf);
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
//configure the command line options correctly on the submitting dfs
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
submitHostAddress = ip.getHostAddress();
submitHostName = ip.getHostName();
conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);
conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress);
}
// 让yarn集群给job获取身份证编号
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
// 有了jobid,yarn就会准备一个临时文件夹,要运行job的必要文件提交到job文件夹下面
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
JobStatus status = null;
try {
conf.set(MRJobConfig.USER_NAME,
UserGroupInformation.getCurrentUser().getShortUserName());
conf.set("hadoop.http.filter.initializers",
"org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");
conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString());
LOG.debug("Configuring job " + jobId + " with " + submitJobDir
+ " as the submit dir");
// get delegation token for the dir
TokenCache.obtainTokensForNamenodes(job.getCredentials(),
new Path[] { submitJobDir }, conf);
populateTokenCache(conf, job.getCredentials());
// generate a secret to authenticate shuffle transfers 给了一个可信的shuffle令牌
if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) {
KeyGenerator keyGen;
try {
int keyLen = CryptoUtils.isShuffleEncrypted(conf)
? conf.getInt(MRJobConfig.MR_ENCRYPTED_INTERMEDIATE_DATA_KEY_SIZE_BITS,
MRJobConfig.DEFAULT_MR_ENCRYPTED_INTERMEDIATE_DATA_KEY_SIZE_BITS)
: SHUFFLE_KEY_LENGTH;
keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM);
keyGen.init(keyLen);
} catch (NoSuchAlgorithmException e) {
throw new IOException("Error generating shuffle secret key", e);
}
SecretKey shuffleKey = keyGen.generateKey();
TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(),
job.getCredentials());
}
copyAndConfigureFiles(job, submitJobDir);
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
// Create the splits for the job
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
// 切片规则的方法
int maps = writeSplits(job, submitJobDir);
// 把切片的数量设置成maps的数量
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);
// write "queue admins of the queue to which job is being submitted"
// to job file.
String queue = conf.get(MRJobConfig.QUEUE_NAME,
JobConf.DEFAULT_QUEUE_NAME);
AccessControlList acl = submitClient.getQueueAdmins(queue);
conf.set(toFullPropertyName(queue,
QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());
// removing jobtoken referrals before copying the jobconf to HDFS
// as the tasks don't need this setting, actually they may break
// because of it if present as the referral will point to a
// different job.
TokenCache.cleanUpTokenReferral(conf);
if (conf.getBoolean(
MRJobConfig.JOB_TOKEN_TRACKING_IDS_ENABLED,
MRJobConfig.DEFAULT_JOB_TOKEN_TRACKING_IDS_ENABLED)) {
// Add HDFS tracking ids
ArrayList<String> trackingIds = new ArrayList<String>();
for (Token<? extends TokenIdentifier> t :
job.getCredentials().getAllTokens()) {
trackingIds.add(t.decodeIdentifier().getTrackingId());
}
conf.setStrings(MRJobConfig.JOB_TOKEN_TRACKING_IDS,
trackingIds.toArray(new String[trackingIds.size()]));
}
// Set reservation info if it exists
ReservationId reservationId = job.getReservationId();
if (reservationId != null) {
conf.set(MRJobConfig.RESERVATION_ID, reservationId.toString());
}
// Write job file to submit dir
// core-default hdfs-default
// mapred-default yarn-default 4个xml配置
// 还有切片和切片元信息和校验文件都在这个文件夹下
// 把配置文件写在job临时文件夹下
writeConf(conf, submitJobFile);
//
// Now, actually submit the job (using the submit name)
//
printTokens(jobId, job.getCredentials());
status = submitClient.submitJob(
jobId, submitJobDir.toString(), job.getCredentials());
if (status != null) {
return status;
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (jtFs != null && submitJobDir != null)
jtFs.delete(submitJobDir, true);
}
}
}
writeSplits()
private int writeSplits(org.apache.hadoop.mapreduce.JobContext job,
Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
JobConf jConf = (JobConf)job.getConfiguration();
int maps;
if (jConf.getUseNewMapper()) {
maps = writeNewSplits(job, jobSubmitDir);
} else {
maps = writeOldSplits(jConf, jobSubmitDir);
}
return maps;
}
writeNewSplits()
private <T extends InputSplit>
int writeNewSplits(JobContext job, Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
Configuration conf = job.getConfiguration();
// inputformat的一个实例
InputFormat<?, ?> input =
ReflectionUtils.newInstance(job.getInputFormatClass(), conf);
// inputformat进行切片
List<InputSplit> splits = input.getSplits(job);
T[] array = (T[]) splits.toArray(new InputSplit[splits.size()]);
// sort the splits into order based on size, so that the biggest
// go first
// 根据大小将分割的部分排序,以便最大的先走
Arrays.sort(array, new SplitComparator());
JobSplitWriter.createSplitFiles(jobSubmitDir, conf,
jobSubmitDir.getFileSystem(conf), array);
return array.length;
}
getSplits()
public List<InputSplit> getSplits(JobContext job) throws IOException {
Stopwatch sw = new Stopwatch().start();
// minSize=1
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
// maxSize = long
long maxSize = getMaxSplitSize(job);
// generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
// 获取job文件集的列表
List<FileStatus> files = listStatus(job);
// 先遍历文件,
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
// 判断文件可不可以切,不可切分的压缩文件就不可以切
if (isSplitable(job, path)) {
// 获取文件块大小--128M
long blockSize = file.getBlockSize();
// 基本上每次都会取到128m
// 假设我们不想按照128M分,想取maxsize就让max比128m小,想取minsize就让minsize比128m大
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
// 当前文件的剩余的大小
long bytesRemaining = length;
// 如果当前文件剩余大小大于我切片大小的1.1倍我才会切
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
// 把切片的规则写在splits里面
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.elapsedMillis());
}
return splits;
}
InputFormat是把文件变为切片,每个切片之后再变成(k,v)对
- 默认的TextInputFormat
- 切片方法:直接用的FileInputFormat的切片方法
- k,v方法:自己重写
getRecordReader()
public RecordReader<LongWritable, Text> getRecordReader(
InputSplit genericSplit, JobConf job,
Reporter reporter)
throws IOException {
reporter.setStatus(genericSplit.toString());
// 分隔符
String delimiter = job.get("textinputformat.record.delimiter");
byte[] recordDelimiterBytes = null;
if (null != delimiter) {
recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);
}
return new LineRecordReader(job, (FileSplit) genericSplit,
recordDelimiterBytes);
}
LineRecordReader()
public LineRecordReader(Configuration job, FileSplit split,
byte[] recordDelimiter) throws IOException {
this.maxLineLength = job.getInt(org.apache.hadoop.mapreduce.lib.input.
LineRecordReader.MAX_LINE_LENGTH, Integer.MAX_VALUE);
start = split.getStart();
end = start + split.getLength();
final Path file = split.getPath();
compressionCodecs = new CompressionCodecFactory(job);
codec = compressionCodecs.getCodec(file);
// open the file and seek to the start of the split
final FileSystem fs = file.getFileSystem(job);
fileIn = fs.open(file);
if (isCompressedInput()) {
decompressor = CodecPool.getDecompressor(codec);
if (codec instanceof SplittableCompressionCodec) {
final SplitCompressionInputStream cIn =
((SplittableCompressionCodec)codec).createInputStream(
fileIn, decompressor, start, end,
SplittableCompressionCodec.READ_MODE.BYBLOCK);
in = new CompressedSplitLineReader(cIn, job, recordDelimiter);
start = cIn.getAdjustedStart();
end = cIn.getAdjustedEnd();
filePosition = cIn; // take pos from compressed stream
} else {
in = new SplitLineReader(codec.createInputStream(fileIn,
decompressor), job, recordDelimiter);
filePosition = fileIn;
}
} else {
fileIn.seek(start);
in = new SplitLineReader(fileIn, job, recordDelimiter);
filePosition = fileIn;
}
// If this is not the first split, we always throw away first record
// because we always (except the last split) read one extra line in
// next() method.
if (start != 0) {
start += in.readLine(new Text(), 0, maxBytesToConsume(start));
}
this.pos = start;
}
即实现一个指定的Map映射函数,用来把一组键值对映射成新的键值对,再把新的键值对发送个Reduce规约函数,用来保证所有映射的键值对中的每一个共享相同的键组
四:MapReduce一些小细节与优化:

之后的一些剩余我会后续继续更新。