-
MapReduce on Yarn运行原理
-
Job提交
-
yarn由两个重要的jvm进程组成:ResourceManager、NodeManager。在客户端运行MapReduce Job之后,会首先向ResourceManager申请一个唯一的applicationID
-
判断Job的输出路径是否存在,如果存在则报错退出。这里之所以这样设计必须要求要一个新的输出路径的原因可以参考博文:https://www.cnblogs.com/sharpxiajun/p/3151395.html
-
根据输入文件计算input splits
-
将Job需要的依赖资源上传到HDFS,资源包括程序的jar包、计算好的splits(包括input splits数量、位置)等
-
向ResourceManager提交MapReduce Job
-
-
Job初始化
-
ResourceManager根据提交的资源请求在NodeManager上启动一个Container(yarn对资源的一个封装,就是包含一定cpu和内存的jvm)运行ApplicationMaster(MRAppMaster)。在这里需要说明两点,第一,可以在程序内部添加代码实现内存和cpu的配置(相对于在mapred-site.xml中配置较为灵活),ResourceManager根据资源情况选择合适的NodeManager启动一个Container来运行MRAppMaster。第二,之所以要在NodeManager上运行MRAppmaster是为了分散ResourceManager所在主机的运行压力。
-
MRAppmaste初始化job(多少MapTask、ReduceTask、都在哪些机器上跑)
-
读取inputsplits信息,为每个inputsplits创建MmapTask,根据程序里的配置确定需要创建多少个ReduceTask,MRAppmaste就是负责管理Task运行的
-
-
Task分配
-
MRAppmaste为每一个MapTask、ReduceTask向ResourceManager申请资源
-
-
Task执行
-
在申请完资源之后在数据所在的节点启动一个Container,在其中运行一个YarnChild
-
MapTask、ReduceTask都是运行在YarnChild上的,运行过程中会给MRAppmaste发送运行状态信息
-
以上基本描述了MapReduce on Yarn的一个基本运行过程,可以参考以下的图示进行理解。


-
-
MapReduce 的运行机制
宏观角度来看,整个MapReduce 程序运行的核心是MapTask和ReduceTask,分阶段来看主要分为三个阶段:map阶段、shuffle阶段、reduce阶段,这其中shuffle是核心。
-
map阶段:实际上是运行编写好的map方法就可以,一般会在相应的splits节点机器上本地运行。
-
shuffle阶段:shuffle阶段的操作横跨MapTask和ReduceTask
-
在经过map方法之后数据会以key-value的形式保存在内存中,如果在程序中设置了要用多个ReduceTask的话,接下来MapReduce提供Partitioner接口进行分区,也就是决定哪些数据会最终在哪一个ReduceTask上跑。默认情况下是HashPartitioner,也可以自定义。之后,需要将数据写入内存缓冲区中,缓冲区的作用是批量收集map结果。我们的key-value对以及Partition的结果都会被写入缓冲区。当然写入之前,key与value值都会被序列化成字节数组。缓冲区是一个环形数据结构中,使用环形数据结构是为了更有效地使用内存空间,在内存中放置尽可能多的数据。
-
这个缓冲区的默认大小是100MB,那么当数据量较大的时候,缓冲区就不够用了,这个时候就需要向磁盘中写入,但是这里不是说完全达到100MB才会触发向磁盘写的操作,默认情况下会有一个0.8的阈值系数,也就是说当占用了80MB的空间之后,就会触发向磁盘写的操作,称为spill。当溢写线程触发之后,需要对这80MB空间内的key做排序(Sort),在spill的过程中还可以利用剩余的20MB空间继续向缓存区存入数据,这两个过程之间互不影响。如果client设置过Combiner,那么现在就是使用Combiner的时候了,将有相同key的key/value对的value加起来,减少溢写到磁盘的数据量,但是combiner要慎用,使用它的原则是combiner的输入不会影响到reduce计算的最终输入,例如:如果计算只是求总数,最大值,最小值可以使用combiner,但是做平均值计算使用combiner的话,最终的reduce计算结果就会出错。每次spill操作也就是写入磁盘操作时候就会写一个溢出文件,也就是说在做map输出有几次spill就会产生多少个溢出文件。
-
由于最终的输出文件只有一个,所以需要将这些溢写文件归并到一起,这个过程就叫做Merge。这里可能也会出现多个相同key的情况,设置过combiner的话这里也会进行合并。
以上就是MapTask阶段的shuffle操作。
-
拉取MapTask的输出文件,主要通过HTTP的方式请求数据
-
merge和sort,数据拉取过来之后会先放在内存缓冲区中,与map端的spill类似也会向磁盘写如溢出文件,同时进行排序,最后在硬盘中合并为一个最终文件
-
-
reduce阶段:生成的最终文件作为reduce的输入,然后调用编写的reduce方法最终完成ReduceTask阶段。
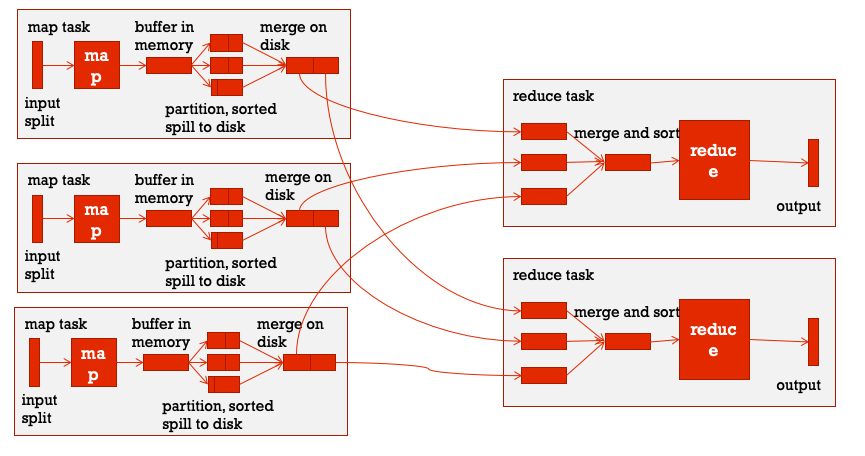

通过上述分析可以发现,在整个环节中shuffle的操作最为复杂真正涉及到内存以及磁盘的读写,所以shuffle阶段是一个主要系统调优的点。
参考:
【1】https://www.cnblogs.com/sharpxiajun/p/3151395.html
【2】https://blog.csdn.net/sunshingheavy/article/details/75849554
【3】https://langyu.iteye.com/blog/992916
-