1 MapReduce核心原理
“分而治之,并行计算”是MapReduce的核心原理,其实也是大数据处理的中心思想。
1.1 分而治之
在MapReduce中,分而治之,就是,
一个任务分成多个小的子任务(map),并行执行后,合并结果(reduce)。
1.2 并行计算
在任务分配完之后,每个子任务平行执行,彼此之间是互不影响的,也就是并行计算,具体的子任务可以按照具体的标准进行。在每一个子任务都完成之后再按照统一的标准进行合并计算即可。
2 实例讲解
下面以一个实际例子展开讲解,增强理解。
2.1 问题
现在有若干张(数量足够多)杂乱无绪的、而且数目残缺不全的纸牌,一共有2~A共计14种纸牌(不计花色),需要统计出来每种纸牌各有多少(不计花色)。
2.2 问题解决步骤
大体可分为以下步骤,如下图。
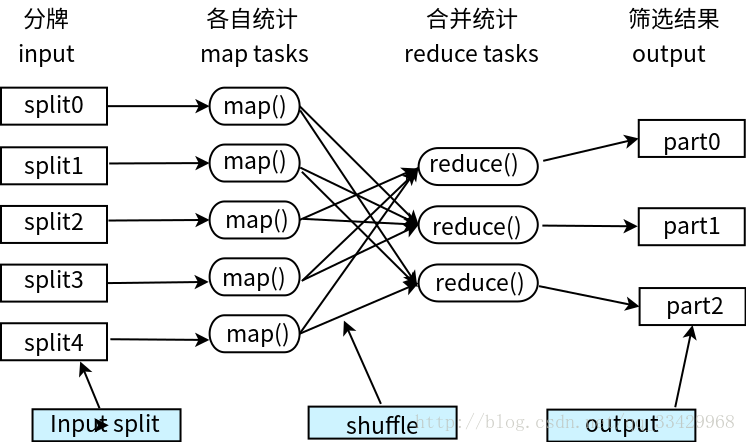
1.分牌--分配任务
假设一共有1000张纸牌,现在将它们平均分配改5个人来统计处理。
那么每个人处理200张纸牌。
2.各自统计--并行计算Map
每个人将手中各种类型的纸牌的数量统计出来。
例如:
小红:(J,11) (Q,36) (K,3) … …
小蓝:(J,36) (Q,2) (K,25) … …
小绿:(J,1) (Q,3) (K,69) … …
小黄:(J,96) (Q,14) (K,64) … …
小青:(J,55) (Q,26) (K,88) … …
3.合并统计Reduce
然后,汇总。
每个人将各自统计的不同类型的纸牌的数量展示出来。
然后再将相同类型的纸牌的数量加和即可。
则如下:
(J,11+36+1+96+55) -> (J,199)
(Q,36+2+3+14+26) -> (Q,179)
(K,3+25+69+64+88) ->(K,185)
4.筛选结果
最终,所有的纸牌类型都按照这样的标准计算即可得出所有的结果。
3 构建抽象模型
以上“分而治之,并行计算”的数据处理思想,是典型的流式大数据问题的特征。
Map和Reduce为我们提供了一个清晰的操作接口。
4 统一框架
MapReduce提供一个统一的计算框架,可完成:
—计算任务的划分和调度
数据的分布存储和划分
—处理数据与计算任务的同步
结果数据的收集整理(sorting, combining, partitioning,…)
—系统通信、负载平衡、计算性能优化处理
处理系统节点出错检测和失效恢复