一、文献梳理
1、文献背景
1)生成模型
生成问题(图像,文本,语音)是人工智能领域的重要分支,其模型可以用:
- 模拟未来(规划、仿真)
- 处理缺失数据
- 多模态输出
- 解决真实的数据生成问题
2)传统生成模型(概率生成模型)
- 变分自动编码模型(VAE):优点是允许带隐变量的概率图模型学习和贝叶斯推断,缺点是生成样本模糊
- 自回归模型:优点是简单,训练过程稳定,缺点是采用效率低
2、研究成果
1)模型意义
- 首次提出了生成对抗网络的概念及结构
- 给出GAN的通用训练策略
- 通过实验证明了GAN的能力和特性
- 开创性的工作,第一次提出双网络训练,并给出完整数学证明
- 在图像生成,语音生成,超分辨率重构,图像翻译,风格迁移,图像域变化,图像修复,视频预测等方面取得显著成效
2)实验结果
二、基础知识补充
1、判别模型
- 模型学习的是后验概率P(Y/X)
- 任务是从属性X(特征)预测标记Y(类别)
2、生成模型
- 模型学习的是后验概率P(X,Y)
- 每一类都会求出一个分布。看样本更符合哪个
补充:
下图我们输入一个高斯分布,那模型所学习到的就是高斯分布到真实样本分布的映射。与判别模型不同,判别模型得到的是数据的决策超平面,输出的是数据为某一类别的概率。

在一维情况下就如下图

在二维情况下,更为直观。判别模型学习的是外围边界,而生成模型是一个符合某一分布的样本集合。之所以生成样本可以用于分类,往往是通过联合概率求解后验概率。

之所以生成模型可以通过“随意”输入噪音就可以生成图片,是因为模型学习的就是噪音到真实样本映射分布。其本质是从噪音中采样,即从噪音中采集数据,并由这些数据构成真实样本。如果更换噪音的分布其结果就会大打折扣,所以噪音也不是随便就行。

三、文献重点
1、网络结构
结构有判别器与生成器组合而成,生成模型负责生成假样本欺骗判别器,判别模型负责分辨真假样本。两个模型交替训练,类似对抗博弈的过程,两个模型都使用反向传播进行参数更新。

2、训练过程
1)训练判别器,固定生成器,使用反向传播。

补充:所谓固定生成器只是将生成器中的参数固定并非不使用生成器。此时,判别器中的输入仍来自真实样本与生成样本两部分,只是此时得到的损失值只用于更新判别器。
2) 训练生成器,固定判别器,使用反向传播

补充:此时训练不再使用真实样本,并使用新的噪音生成新的假样本。将新产生的假样本输入判别器并得到损失值,此时得到的损失值只用于更新生成器
3)训练过程示意图
(a)为网络的初始状态,(b)为训练判别器,(c)为训练生成器,反复进行(b、c)得到最终结果(d)。离散点是真样本,绿线为生成样本,蓝点为决策界面。

补充:为什么判别器是那样的呢?因为咱们的分类器是softmax,所以初始的分类界面类似逻辑函数,但是有抖动。经过简单的参数更新会使分类器逐渐趋于稳定,并在之后逐渐变化,最终当真实样本与生成样本一致时,判别器已经失去作用,真实还是虚假一半一半变成d图。
2、推导
1)传统的生成方法(本质是使用最大似然估计进行模型的参数估计)
- 先得到一批样本,真实分布是
。
- 我们假设定义一个分布
,(假设符合高斯分布,参数就是均值与方差)
- 我们希望确定
使
- 先有已知样本x1,...,xm,利用这些样本通过最大似然估计求解出参数,就可以估计出
- 换言之,需要找到一组参数来最大化这个似然函数

寻找一组参数来最大化这个似然,等价于最大化log似然。因为此时这m个数据,是从真实分布中取的,是离散的所以也就约等于真实分布中的所有x在分布中的log似然的期望。 正常如果知道
的概率分布公式直接求偏导即可。
2)如果不知道的公式,可以用神经网络代替表示呢?
是可以的,神经网络只要有非线性激活函数,就可以去拟合任意的函数,那么分布也是一样,所以可以用一直正态分布,或者高斯分布,取样去训练一个神经网络,学习到一个很复杂的分布。
3)如果用神经网络代替,损失函数应该是是什么呢?
(1)输入为真实数据,损失函数为真实数据与预测数据的几何距离。
看似合理,但会这是压缩啊?神经网络的最优结果是没有神经网络,开玩笑一样,所以是不行的。
(2)输入为随机噪音,损失函数为真实数据与预测数据的几何距离。
同样看似合理,但是此情况会默认你的噪音跟真实数据一一对应。我们希望模型具有泛化能力,应该是这两个分布直接的差距最小。如果默认噪音跟真实数据一一对应,即便是同一个分布产生的噪音输入(换一个对应关系)也必须重新训练网络,这种没有泛化能力的网络毫无意义。顺便说一下KL散度定义:

4)如何求得一个更加一般化的生成模型呢?
- G是一个函数,输入是某个分布z,输出是x。预测的分布
可以通过G来表示
- D也是一个函数,输入是样本x,输出是概率。作用是判别
- 通过生成器和判别器可以定义一个总函数V(G,D)
![]()
5)目标
首先,我们知道最大化的似然函数等价与缩小和
的差距。因此,其优化目标为

咱们将其转化为下式,为什么可以如此转化见推导

即固定 G,maxV(G,D) 就表示和
之间的差异最大,然后要找一个最好的 G,让这个最大值最小,也就是两个分布之间的差异最小。
6)求解
(1)固定G,求最优的D*使V最大:

等价于找一个D,使下面的式子最大
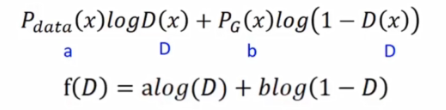
求导=0

化简,最后得得D*=a/(a+b)

(2)把最优的D带回目标函数,求解G

分支分母同时除以1/2,在将分子上的1/2提出来

KL散度表示两个分布的距离,优化函数的最优解与优化目标一致,得证。
3、算法
注意的是,在一次整体训练中,它包括k次判别器训练,一次生成器训练。

四、优缺点
优点:
- 更新参数时可以使用反向梯度传播,而不再需要马尔科夫链
- 不需要对隐变量进行求解
- 任何可微函数都可以当做G,D。
缺点:
- 训练难度大