专栏——深度学习入门笔记
推荐文章
——————————————————————————————————————————————————————
上一个笔记我们学习了感知机。对于复杂的函数,感知机也隐含着能够表示它的可能性。上一章已经介绍过,即便是计算机进行的复杂处理,感知机(理论上)也可以将其表示出来。坏消息是,设定权重的工作,即确定合适的、能符合预期的输人与输出的权重,现在还是由 人工进行的。上一章中,我们结合与门、或门的真值表人工决定了合适的权重。
神经网络的出现就是为了解决刚才的坏消息。具体地讲,神经网络的一个重要性质是它可以自动地从数据中学习到合适的权重参数。本章中,我们会先介绍神经网络的概要,然后重点关注神经网络进行识别时的处理。在下一章中,我们将了解如何从数据中学习权重参数。
1. 从感知机到神经网络
神经网络和上一章介绍的感知机有很多共同点。这里,我们主要以两者的差异为中心,来介绍神经网络的结构。
1.1 神经网络示例
用图来表示神经网络的话,如图3-1所示。我们把最左边的一列称为输入层,最右边的一列称为输出层,中间的一列称为中间层。中间层有时也称为隐藏层。“隐藏”一词的意思是,隐藏层的神经元(和输人层、输出层不同)肉眼看不见。另外,我们把输人层到输出层依次称为第0层、第1层、第2层(层号之所以从0开始,是为了方便后面基于Python进行实现)。图3-1中,第0层对应输入层,第1层对应中间层,第2层对应输出层。

只看图3-1的话,神经网络的形状类似上一节的感知机。实际上,就神经元的连接方式而言,与上一章的感知机并没有任何差异。那么,神经网络中信号是如何传递的呢?
1.2 回忆感知机

如上图,感知机接收 和 俩个输入信号,输出y,数学公式如下(式3.1):
b是被称为 偏置的参数,用于控制神经元被激活的容易程度;而 和 是表示各个信号的权重的参数,用于控制各个信号的重要性。
顺便提一下,在图3-2的网络中,偏置b并没有被画出来。如果要明确地表示出b,可以像图3-3那样做。图3-3中添加了权重为b的输人信号1。这个感知机将 三个信号作为神经元的输人,将其和各自的权重相乘后,传送至下一个神经元。在下一个神经元中,计算这些加权信号的总和。如果这个总和超过0,则输出1,否则输出0。另外,由于偏置的输人信号一直是1,所以为了区别于其他神经元,我们在图中把这个神经元整个涂成灰色。

现在将式(3.1)改写成更加简洁的形式。为了简化式(3.1),我们用一个函数来表示这种分情况的动作(超过0则输出1,否则输出0)。引人新函数h(x),将式(3.1)改写成下面的式(3.2)和式(3.3)。
3.1 激活函数
刚才登场的h(x)函数会将 输人信号的总和转换为输出信号,这种函数一般称为 激活函数(activation function)。 如“激活”一词所示,激活函数的作用在于决定如何来激活输入信号的总和。
现在来进一步改写式(3.2)。式(3.2) 分两个阶段进行处理,先计算输入信号的加权总和,然后用激活函数转换这一总和。因此,如果将式(3.2)写得详细一点,则可以分成下面两个式子。
首先,式(3.4)计算加权输入信号和偏置的总和,记为a。然后,式(3.5)用 h() 函数将 a 转换为输出 y。
之前的神经元都是用一个O表示的,如果要在图中明确表示出式(3.4)和式(3.5),则可以像图3-4这样做。

如图3-4所示,表示神经元的O中明确显示了激活函数的计算过程,即信号的加权总和为节点a,然后节点 a 被激活函数 h() 转换成节点 y。注意,“神经元"和“节点"两个术语的含义相同。这里,我们称 a 和 y 为“节点",其实它和之前所说的“神经元”含义相同。
下面,我们将仔细介绍激活函数。激活函数是连接感知机和神经网络的桥梁。
2. 激活函数
式(3.3)表示的激活函数以阈值为界,一旦输入超过阈值,就切换输出。这样的函数称为 “阶跃函数”。因此,可以说感知机中使用了阶跃函数作为激活函数。也就是说,在激活函数的众多候选函数中,感知机使用了阶跃函数。那么,如果感知机使用其他函数作为激活函数的话会怎么样呢?实际上,如果将激活函数从阶跃函数换成其他函数,就可以进人神经网络的世界了。下面我们就来介绍一下神经网络使用的激活函数。
2.1 sigmoid函数
神经网络中经常使用的一个激活函数就是式(3.6)表示的 sigmoid函数(sigmoid function)。
式(3.6)中的 表示 ”的意思。式(3.6) 表示的sigmoid函数看上去有些复杂,但它也仅仅是个函数而已。而函数就是给定某个输人后,会返回某个输出的转换器。比如,向sigmoid函数输人1.0或2.0后,就会有某个值被输出,类似h(1.0) = 0.731… h(2.0) = 0.88…这样。神经网络中用sigmoid函数作为激活函数,进行信号的转换,转换后的信号被传送给下一个神经兀。实际上,上一章介绍的感知机和接下来要介绍的神经网络的主要区别就在于这个激活函数。其他方面,比如神经元的多层连接的构造、信号的传递方法等,基本上和感知机是一样的。下面,让我们通过和阶跃函数的比较来详细学习作为激活函数的sigmoid函数。
2.2 阶跃函数的代码实现
这里我们试着用Python画出阶跃函数的图(从视觉上确认函数的形状对理解函数而言很重要)。阶跃函数如式(3.3)所示,当输人超过0时,输出1,否则输出0。可以像下面这样简单地实现阶跃函数。
def step_ function(x):
if x > 0:
return 1
else:
return 0
这个实现简单、易于理解,但是参数 x 只能接受实数(浮点数)。也就是说,允许形如step_ function(3.0) 的调用,但不允许参数取NumPy数组,例如step. function(np.array([1.0, 2.0])。 为了便于后面的操作,我们把它修改为支持NumPy数组的实现。为此,可以考虑下述实现。
def step_ function(x):
y = x > θ
return y.astype (np.int)
对NumPy数组进行不等号运算后,数组的各个元系都会进行不等号运算,生成一个布尔型数组。这里,数组x中大于0的元素被转换为True,小于等于0的元素被转换为False,从而生成一个新的数组y。数组 y 是一个布尔型数组,但是我们想要的阶跃函数是会输出int型的0或1的函数。因此,需要把数组 y 的元素类型从布尔型转换为int型。astype()方法会将数值转化为指定的数据类型。
2.3 阶跃函数的图形
下面我们]就用图来表示上面定义的阶跃丽数,为此需要使用matplotlib库。
import numpy as np
import matplotlib.pylab as plt
def step_ function(x):
return np.array(x > 0,dtype=np.int)
x = np.arange(-5.0, 5.0, 0.1)
y = step_ function(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1) #指定y轴的范围
plt.show()
在 -5.0 到 5.0 的范围内,以 0.1 为单位,生成NumPy数组([-5.0, -4.9, … 4.9])。step_ function() 以该NumPy数组为参数,对数组的各个元素执行阶跃函数运算,并以数组形式返回运算结果。对数组x、y进行绘图,结果如图3-6所示。

如图3-6所示,阶跃函数以0为界,输出从0切换为1(或者从1切换为0)。它的值呈阶梯式变化,所以称为阶跃函数。
2.4 sigmoid函数的代码实现
python实现sigmoid:
def sigmoid(x):
return 1 / (1 + np.exp(-x))
下面我们把sigmoid函数画在图上。画图的代码和刚才的阶跃函数的代码几乎是一样的,唯一不同的地方是把输出 y 的函数换成了sigmoid函数。
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1) #指定y轴的范围
plt.show()
运行上面的代码,可以得到图3-7。

2.5 sigmoid函数与阶跃函数的比较
sigmoid 函数是一条平滑的曲线,输出随着输人发生连续性的变化。而阶跃函数以0为界,输出发生急剧性的变化。sigmoid 函数的连续性对神经网络的学习具有重要意义。
另一个不同点是,相对于阶跃兩数只能返回 0 或1, sigmoid兩数可以返回0.731…0.880… 等实数(这一点和刚才的平滑性有关)。也就是说,感知机中神经元之间流动的是0或1的二元信号,而神经网络中流动的是连续的实数值信号。
接着说一下阶跃丽数和sigmoid函数的共同性质。阶跃丽数和sigmoid函数虽然在平滑性上有差异,但是它们具有相似的形状。实际上,两者的结构均是“输人小时,输出接近0(为0);随着输人增大,输出向1靠近(变成1)”。也就是说,当输入信号为重要信息时,阶跃函数和sigmoid丽数都会输出较大的值;当输入信号为不重要的信息时,两者都输出较小的值。还有一个共同点是,不管输入信号有多小,或者有多大,输出信号的值都在0到1之间。
2.6 ReLU函数
到目前为止,我们介绍了作为激活函数的阶跃函数和sigmoid函数。在神经网络发展的历史上,sigmoid函数很早就开始被使用了,而最近则主要使用 ReLU( Rectified Linear Unit )函数。ReLU函数在输入大于0时,直接输出该值;在输人小于等于0时,输出0(图3-9)。

ReLU函数可以表示为下面的式(3.7)。
ReLU函数代码实现:
def relu(x):
return np.maximum(0,x)
这里使用了NumPy的maximum函数。maximum函数会从输入的数值中选择较大的那个值进行输出。
3. 多维数组运算
如果掌握了NumPy多维数组的运算,就可以高效地实现神经网络。因此,本节将介绍NumPy多维数组的运算,然后再进行神经网络的实现。
3.1 多维数组
简单地讲,多维数组就是 “数字的集合”,数字排成一列的集合、排成长方形的集合、排成三维状或者(更加一般化的) N维状的集合都称为多维数组。下面我们就用NumPy来生成多维数组,先从前面介绍过的一维数组开始。
>>> import numpy as np
>>> A = np.array([1, 2, 3, 4])
>>> print(A)
[1234]
>>> np. ndim(A)
>>> A.shape
(4,)
>>> A.shape[0]
4
如上所示, 数组的维数可以通过np.ndim()函数获得。此外,数组的形状可以通过实例变量shape获得。在上面的例子中,A是一维数组,由4个元素构成。注意,这里的A.shape的结果是个元组(tuple)。这是因为一维数组的情况下也要返回和多维数组的情况下一致的结果。例如,二维数组时返回的是元组(4,3),三维数组时返回的是元组(4,3,2),因此一维数组时也同样以元组的形式返回结果。下 面我们来生成一个二维数组。
>>> B = np.array([[1,2], [3,4], [5,6]])
>>> print(B)
[[1 2]
[3 4]
[5 6]]
>>> np.ndim(B)
>>> B.shape
(3,2)
这里生成了一个3 x 2的数组B。3 x 2的数组表示第一个维度有3 个元素,第二个维度有2个元素。另外,第一个维度对应第0维,第二个维度对应第1维( Python的索引从0开始)。二维数组也称为矩阵(matrix)。如图3- 10所示,数组的横向排列称为行(row),纵向排列称为列(column)。
3.2 矩阵乘法

如本例所示,矩阵的乘积是通过 左边矩阵的行(横向)和右边矩阵的列(纵向)以对应元素的方式相乘后再求和而得到的。并且,运算的结果保存为新的多维数组的元素。比如,A的第1行和B的第1列的乘积结果是新数组的第1行第1列的元素,A的第2行和B的第1列的结果是新数组的第2行第1列的元素。另外,在本书的数学标记中,矩阵将用黑斜体表示(比如,矩阵A),以区别于单个元素的标量(比如,a或b)。这个运算在Python中可以用如下代码实现。
>> A = np.array([[1,2], [3,4]])
>>> A.shape
(2, 2)
>>> B = np.array([[5,6], [7,8]])
>>> B.shape
(2, 2)
>>> np.dot(A, B)
array([[19,22],
[43,50]])
这里,A和B都是 2 x 2 的矩阵,它们的乘积可以通过 NumPy 的 np. dot() 函数计算(乘积也称为点积)。np. dot()接收两个NumPy数组作为参数,并返回数组的乘积。这里要注意的是,np.dot(A, B) 和np.dot(B, A) 的值可能不一样。和一般的运算(+或*等)不同,矩阵的乘积运算中,操作数(A,B)的顺序不同,结果也会不同。
这里介绍的是计算2 x 2形状的矩阵的乘积的例子,其他形状的矩阵的乘积也可以用相同的方法来计算。比如,2 x 3的矩阵和3 x 2的矩阵的乘积.可按如下形式用Python来实现。
>>> A = np.array([[1,2,3], [4,5,6]])
>>> A.shape
(2, 3)
>>> B = np.array([[1,2], [3,4], [5,6]])
>>> B.shape
(3,2)
>>> np.dot(A, B)
array([[22,28],
[49, 64]])
矩阵A的第1维的元素个数(列数)必须和矩阵B的第0维的元素个数(行数)相等。在上面的例子中,矩阵A的形状是2x 3,矩阵B的形状是3x2,矩阵A的第1维的元素个数(3)和矩阵B的第0维的元素个数(3)相等。如果这两个值不相等,则无法计算矩阵的乘积。
3.3 神经网络的内积
下面我们使用NumPy矩阵来实现神经网络。这里我们以图3- 14中的简单神经网络为对象。这个神经网络省略了偏置和激活函数,只有权重。

实现该神经网络时,要注意 的形状,特别是 X 和 W 的对应维度的元素个数是否一致,这一点很重要。
>>> X = np.array([1, 2])
>>> X.shape
(2,)
>> W = np.array([[1, 3, 5], [2, 4, 6])
>>> print(W)
[[1 3 5]
[2 4 6]]
>>> W.shape
>(2, 3)
>>> Y = np.dot(X, W)
>>> print(Y)
[5 11 17]
如上所示,使用np.dot(多维数组的点积),可以一次性计算出Y的结果。这意味着,即便Y的元素个数为100或1000,也可以通过一次运算就计算出结果!如果不使用np.dot,就必须单独计算Y的每一个元素(或者说必须使用for语句),非常麻烦。因此,通过矩阵的乘积一次性完成计算的技巧,在实现的层面上可以说是非常重要的。
4. 3层神经网络的实现
现在我们来进行神经网络的实现。这里我们以图3- 15的3层神经网络为对象,实现从输入到输出的(前向)处理。在代码实现方面,使用上一节介绍的NumPy多维数组。巧妙地使用NumPy数组,可以用很少的代码完成神经网络的前向处理。

4.1 符号含义
如图3- 16所示,权重和隐藏层的神经元的右上角有一个“(1)”,它表示权重和神经元的 层号(即第1层的权重、第1层的神经元)。此外,权重的右下角有两个数字,它们是后一层的神经元和前一层的神经元的索引号。比如, 表示前一层的第2个神经元 到后一层的第1个神经元 的权重。权重右下角按照“后一层的索引号、前一层的索引号”的顺序排列。

4.2 各层间信号传递的实现

图3-17中增加了表示偏置的神经元“1”。请注意,偏置的右下角的索引号只有一个。这是因为前一层的偏置神经元(神经元“1”)只有一个。为了确认前面的内容,现在用数学式表示
。
通过加权信号和偏置的和按如下方式进行计算。
此外,如果使用矩阵的乘法运算,则可以将第1层的加权和表示成下面的式(3.9)。
下面我们用NumPy多维数组来实现式(3.9),这里将输入信号、权重、偏置设置成任意值。
X = np.array([1.0, 0.5])
W1 = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
B1 = np.array([0.1, 0.2,0.3])
print (Wl.shape) # (2, 3)
print(X. shape) # (2,)
print(B1.shape) # (3,)
A1 = np.dot(X,W1) + B1
如图3-18所示,隐藏层的加权和(加权信号和偏置的总和)用a表示,被激活函数转换后的信号用z表示。此外,图中h()表示激活函数,这里我们使用的是sigmoid函数。用Python来实现,代码如下所示。
Z1 = sigmoid(A1)
print(A1) # [0.3, 0.7, 1.1]
print(Z1) # [0.57444252, 0. 66818777, 0. 75026011]

这个sigmoid()函数就是之前定义的那个函数。它会接收NumPy数组,并返回元素个数相同的NumPy数组。
下面,我们来实现第1层到第2层的信号传递(图3-19)。
W2 = np.array([[0.1, 0.4],[0.2, 0.5],[0.3, 0.6]1)
B2 = np.array([0.1, 0.2])
print(Z1.shape) # (3,)
print (W2.shape) # (3, 2)
print (B2.shape) # (2,)
A2 = np.dot(Z1, W2) + B2
Z2 = sigmoid(A2)
最后是第2层到输出层的信号传递(图3-20)。输出层的实现也和之前的实现基本相同。不过,最后的激活丽数和之前的隐藏层有所不同。
def identity_ function(x):
return X
W3 = np.array([[0.1, 0.3],[0.2, 0.4]])
B3 = np.array([0.1, 0.2])
A3 = np.dot(Z2, W3) + B3
Y = identity_ _function(A3) #或者Y = A3
这里我们定义了identity_ function()函数(也称为 “恒等函数”),并将其作为输出层的激活函数。恒等函数会将输人按原样输出,因此,这个例子中没有必要特意定义identity_ function()。这里这样实现只是为了和之前的流程保持统一。另外,图3-20中,输出层的激活函数用σ()表示,不同于隐藏层的激活函数h()(σ读作sigma)。

4.3 代码小结
至此,我们已经介绍完了3层神经网络的实现。现在我们把之前的代码实现全部整理一下。这里,我们按照神经网络的实现惯例,只把权重记为大写字母 W1,其他的(偏置或中间结果等)都用小写字母表示。
def init_ network():
network = {}
network['W1'] = np.array([[0.1, 0.3,0.5],[0.2, 0.4,0.6]])
network['bl'] = np.array([0.1, 0.2,0.3])
network['W2'] = np.array([[0.1, 0.4], [0.2,0.5], [0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([[0.1, 0.3],[0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
def forward(network, x):
W1, W2, W3 = network[ 'Wl'],network['W2'], network[ 'W3']
bl, b2, b3 = network['b1'], network['b2'], network['b3']
al = np.dot(x, W1) + bl
z1 = sigmoid(a1)
a2 = np.dot(zl, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = identity_ function(a3)
return y
network = init_ network()
x = np.array([1.0, 0.5])
y = forward(network, x)
print(y) # [ 0.31682708 0.69627909 ]
这里定义了init_ network() 和forward()函数。init_ network() 函数会进行权重和偏置的初始化,并将它们保存在字典变量network中。这个字典变量network中保存了每一层所需的参数(权重和偏置)。forward() 函数中则封装了将输入信号转换为输出信号的处理过程。
另外,这里出现了forward(前向一词,它表示的是从输人到输出方向的传递处理。后面在进行神经网络的训练时,我们将介绍后向(backward,从输出到输入方向)的处理。
至此,神经网络的前向处理的实现就完成了。通过巧妙地使用NumPy多维数组,我们高效地实现了神经网络。
5.输出层的设计
神经网络可以用在分类问题和回归问题上,不过需要根据情况改变输出层的激活函数。一般而言,回问题用恒等函数,分类问题用softmax函数。
5.1 恒等函数和softmax函数
恒等函数会将输人按原样输出,对于输人的信息,不加以任何改动地直接输出。因此,在输出层使用恒等函数时,输人信号会原封不动地被输出。另外,将恒等函数的处理过程用之前的神经网络图来表示的话,则如图3-21所示。和前面介绍的隐藏层的激活函数一样,恒等函数进行的转换处理可以用一根箭头来表示。

分类问题中使用的softmax函数可以用下面的式(3.10)表示。
式(3.10) 假设输出层共有n个神经元,计算第k个神经元的输出 。如式(3.10)所示,softmax函数的分子是输人信号 的指数函数,分母是所有输入信号的指数函数的和。
用图表示softmax丽数的话,如图3-22 所示。图3-22中,softmax函数的输出通过箭头与所有的输人信号相连。这是因为,从式(3.10)可以看出,输出层的各个神经元都受到所有输入信号的影响。

现在我们来实现softmax函数。在这个过程中,我们将使用Python解释器逐一确认结果。
>>> a = np.array([0.3, 2.9, 4.0])
>>>
>>> exp_a = np.exp(a) #指数函数
>>> print(exp_a)
[ 1. 34985881 18. 17414537 54. 59815003]
>>>
>>> sum_exp_a = np.sum(exp_a) #指数函数的和
>>> print(sum_exp_a)
74.1221542102
>>>
>>> y = exp_a/sum_exp_a
>>> print(y)
[ 0.01821127 0.24519181 0.73659691]
我们把它定义为函数:
def softmax(a):
exp_a = np.exp(a)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum exp_a
return y
5.2 softmax函数注意事项
上面的softmax函数的实现虽然正确描述了式(3.10),但在计算机的运算上有一定的缺陷。这个缺陷就是溢出问题。softmax函数的实现中要进行指数函数的运算,但是此时指数函数的值很容易变得非常大。比如, 的值会超过20000, 会变成一个后面有40多个0的超大值, 的结果会返回一个表示无穷大的inf。如果在这些超大值之间进行除法运算,结果会出现“确定”的情况。

首先,式(3.11)在分子和分母上都乘上C这个任意的常数(因为同时对分母和分子乘以相同的常数,所以计算结果不变)。然后,把这个C移动到指数函数(exp)中,记为logC。最后,把logC 替换为另一个符号C’。
式(3.11)说明,在进行softmax的指数函数的运算时,加上(或者减去)某个常数并不会改变运算的结果。这里的C’可以使用任何值,但是为了防止溢出,一般会使用输入信号中的最大值。我们来看一个 具体的例子。
>>> a = np.array([1010, 1000, 990] )
>>> np.exp(a) / np.sum(np.exp(a)) # softmax 丽数的运算
array([ nan, nan, nan] )
#没有被正确计算
>>>
>>> C = np.max(a) # 1010.
>>> a-C
array([0, -10, -20])
>>>
>>> np.exp(a - c) / np.sum(np.exp(a - c))
array([ 9.99954600e-01, 4.53978686e - 05, 2.06106005e - 09])
如该例所示,通过减去输入信号中的最大值(上例中的c),我们发现原本为nan(not a number,不确定)的地方,现在被正确计算了。综上,我们可以像下面这样实现softmax函数。
def softmax(a):
C = np.max(a)
exp_a = np.exp(a - c) #溢出对策
sum_exp_a = np.sum(exp_a)
y=exp_a / sum_exp_a
return y
5.3 softmax函数的特征
使用softmax()函数,可以按如下方式计算神经网络的输出。
>>> a = np.array([0.3, 2.9, 4.0])
>>> y = softmax(a )
>>> print(y)
[ 0.01821127 0.24519181 0.73659691 ]
>>> np.sum(y)
1.0
如_上所示,softmax 函数的输出是 0.0 到 1.0 之间的实数。并且,softmax函数的输出值的总和是1。输出总和为1是softmax函数的一个重要性质。正因为有了这个性质,我们才可以把softmax函数的输出解释为 “概率”。
这里需要注意的是,即便使用了softmax函数,各个元素之间的大小关系也不会改变。这是因为指数函数(y=exp(x))是单调递增函数。实际上,上例中a的各元素的大小关系和y的各元素的大小关系并没有改变。比如,a的最大值是第2个元素,y的最大值也仍是第2个元素。
一般而言, 神经网络只把输出值最大的神经元所对应的类别作为识别结果。并且,即便使用softmax函数,输出值最大的神经元的位置也不会变。因此,神经网络在进行分类时,输出层的softmax函数可以省略。在实际的问题中,由于指数函数的运算需要一定的计算机运算量,因此输出层的softmax函数一般会被省略。
6. 手写数字识别
介绍完神经网络的结构之后,现在我们来试着解决实际问题。这里我们来进行手写数字图像的分类。假设学习已经全部结束,我们使用学习到的参数,先实现神经网络的“推理处理”。这个推理处理也称为神经网络的 前向传播( forward propagation)。
6.1 MNIST数据集
这里使用的数据集是MNIST手写数字图像集。MNIST是机器学习领域最有名的数据集之一,被应用于从简单的实验到发表的论文研究等各种场合。实际上,在阅读图像识别或机器学习的论文时,MNIST数据集经常作为实验用的数据出现。
MNIST数据集是由0到9的数字图像构成的(图3-24)。训练图像有6万张,测试图像有1万张,这些图像可以用于学习和推理。MNIST数据集的一般使用方法是,先用训练图像进行学习,再用学习到的模型度量能在多大程度上对测试图像进行正确的分类。
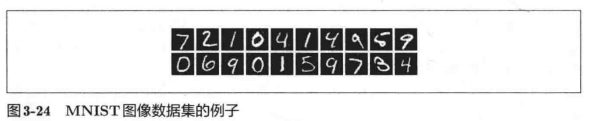
MNIST的图像数据是28像素x 28像素的灰度图像(1通道),各个像素的取值在0到255之间。每个图像数据都相应地标有“7” “2" “1"等标签。
现在我们获取MNIST数据,通过调用dataset文件下的mnist.py,使用其中的load_mnist()函数就可以轻松读入MNIST数据。
import sys, os
sys.path.append(os.pardir) #为了导人父目录中的文件而进行的设定
from dataset.mnist import load_mnist
#第一次调用会花费几分钟..... .
(x_train, t_train), (x_test, t_test) = load_ mnist(flatten=True ,normalize=False)
#输出各个数据的形状
print(x_train.shape) # (60000,784)
print(t_train.shape) # (60000, )
print(x_test.shape) # (10000,784)
print(t_test.shape ) # (10000,)
首先,为了导人父目录中的文件,进行相应的设定”。然后,导人dataset/mnist. py中的load mnist 函数。最后,使用 load_mnist函数,读人MNIST数据集。第一次调用load mnist函数时,因为要下载MNIST数据集,所以需要接入网络。第2次及以后的调用只需读人保存在本地的文件(pickle文件)即可,因此处理所需的时间非常短。
load_ mnist 函数以“(训练图像,训练标签),( 测试图像,测试标签)”的形式返回读入的MNIST数据。此外,还可以像 load mnist (normalize=True,flatten=True,one_ hot_ label=False) 这 样,设置3个参数。第1个参数normalize设置 是否将输人图像正规化为0.0 ~ 10的值。如果将该参数设置为False,则输人图像的像素会保持原来的0~255。第2个参数flatten设置是否展开输入图像(变成一维数组)。如果将该参数设置为False,则输人图像为1 x 28x 28的三维数组;若设置为True,则输人图像会保存为由784个元素构成的一维数组。第3个参数one_hot_label设置是否将标签保存为one-hot表示(one-hot representation)。one-hot 表示是仅正确解标签为1,其余皆为0的数组,就像 [0,0,1,0,0,0,0,0,0,0] 这样。当one_ hot_ label 为False时,只是像7、2这样简单保存正确解标签;当one_hot_label为True时,标签则保存为one-hot表示。
现在,我们试着显示MNIST图像,同时也确认一下数据。图像的显示使用PIL(Python Image Library)模块。执行下述代码后,训练图像的第一张就会显示出来,保存文件为mnist_ show.py。
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
from dataset.mnist import load_mnist
from PIL import Image
def img_show(img):
pil_img = Image.fromarray(np.uint8(img))
pil_img.show()
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
img = x_train[0]
label = t_train[0]
print(label) # 5
print(img.shape) # (784,)
img = img.reshape(28, 28) # 把图像的形状变为原来的尺寸
print(img.shape) # (28, 28)
img_show(img)
这里需要注意的是,flatten=True时读 入的图像是以一列(一维) NumPy数组的形式保存的。因此,显示图像时,需要把它变为原来的28像素x 28像素的形状。可以通过reshape()方法的参数指定期望的形状,更改NumPy数组的形状。此外,还需要把保存为NumPy数组的图像数据转换为PIL用的数据对象,这个转换处理由Image. fromarray()来完成。
6.2 神经网络的推理处理
下面,我们对这个MNIST数据集实现神经网络的推理处理。神经网络的输人层有784个神经元,输出层有10个神经元。输入层的784这个数字来源于图像大小的28 x 28= 784,输出层的10这个数字来源于10类别分类(数字0到9,共10类别)。此外,这个神经网络有2个隐藏层,第1个隐藏层有50个神经元,第2个隐藏层有100个神经元。这个50和100可以设置为任何值。下面我们先定义get_ data()、 init_ network()、 predict() 这3个函数(代码保存在neuralnet_ mnist .py中)。
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import pickle
from dataset.mnist import load_mnist
from common.functions import sigmoid, softmax
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)
return x_test, t_test
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y
init_ network()会读人保存在pickle文件sample_ weight .pkl中的学习到的 权重参数”。这个文件中以字典变量的形式保存了权重和偏置参数。剩余的2个函数,和前面介绍的代码实现基本相同,无需再解释。现在,我们用这3个函数来实现神经网络的推理处理。然后,评价它的识别精度(accuracy),即能在多大程度上正确分类。
x, t = get_data()
network = init_network()
accuracy_cnt = 0
for i in range(len(x)):
y = predict(network, x[i])
p= np.argmax(y) # 获取概率最高的元素的索引
if p == t[i]:
accuracy_cnt += 1
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
首先获得MNIST数据集,生成网络。接着,用for语句逐一取出保存在 x 中的图像数据,用predict()函数进行分类。predict() 函数以NumPy数组的形式输出各个标签对应的概率。比如输出[0.1, 0.3, 0.2, … 0.04] 的数组,该数组表示“0”的概率为0.1,“1” 的概率为0.3,等等。然后,我们取出这个概率列表中的最大值的索引(第几个元素的概率最高),作为预测结果。可以用np.argmax(x)函数取出数组中的最大值的索引,np.argmax(x) 将获取被赋给参数x的数组中的最大值元素的索引。最后,比较神经网络所预测的答案和正确解标签,将回答正确的概率作为识别精度。
执行上面的代码后,会显示“Accuracy:0.9352”。这表示有93.52 %的数据被正确分类了。目前我们的目标是运行学习到的神经网络,所以不讨论识别精度本身,不过以后我们会花精力在神经网络的结构和学习方法上,思考如何进一步提高这个精度。实际上,我们打算把精度提高到99 %以上。另外,在这个例子中,我们把load_ mnist 函数的参数normalize设置成了True。将normalize设置成True后,函数内部会进行转换,将图像的各个像素值除以255,使得数据的值在0.0~1.0的范围内。像这样把数据限定到某个范围内的处理称为正规化(normalization)。 此外,对神经网络的输入数据进行某种既定的转换称为预处理( pre processing)。 这里,作为对输入图像的种预处理,我们进行了正规化。
6.3 批处理
下面我们使用Python解释器,输出刚才的神经网络的各层的权重的形状。
>>> x, _ = get_ data()
>>> network = init_network()
>>> W1, W2, W3 = network['W1'], network[ 'W2'], network[ 'W3']
>>>
>>> X.shape
(10000,784)
>>> x[0].shape
(784,)
>>> W1.shape
>(784,50)
>>> W2.shape
(50,100)
>>> W3.shape
(100, 10)
我们通过上述结果来确认一下多维数组的对应维度的元素个数是否一致(省略了偏置)。用图表示的话,如图3-26所示。可以发现,多维数组的对应维度的元素个数确实是一致的。此外,我们还可以确认最终的结果是输出了元素个数为10的一维数组。
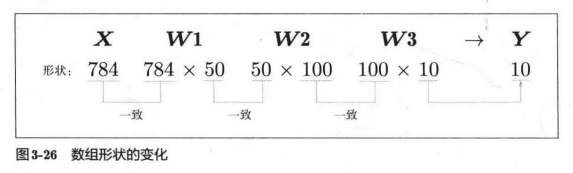
从整体的处理流程来看,图3-26中,输人一个由784个元素(原本是一个28 x 28的二维数组)构成的一维数组后,输出一个有10个元素的一维数组。这是只输人一张图像数据时的处理流程。
现在我们来考虑打包输人多张图像的情形。比如,我们想用predict()函数一次性打包处理100张图像。为此,可以把x的形状改为100x 784,将100张图像打包作为输人数据。用图表示的话,如图3-27所示。
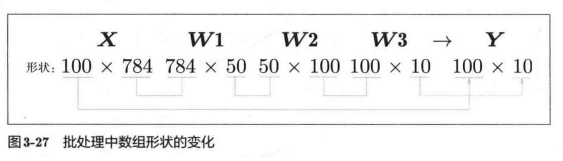
如图3-27所示,输人数据的形状为100x 784,输出数据的形状为100x10。这表示输人的100张图像的结果被–次性输出了。比如,x[0]和y[0]中保存了第0张图像及其推理结果,x[1] 和y[1]中保存了第1张图像及其推理结果,等等。
这种打包式的输人数据称为 批(batch)。批有“捆”的意思,图像就如同纸币一样扎成一捆。
下面我们进行基于批处理的代码实现。这里用粗体显示与之前的实现的不同之外。
x, t = get_data()
network = init_ network()
batch_size = 100 #批数量
accuracy_ cnt = 0
for i in range(0, len(x), batch_size):
x_batch = x[i:i+batch_size]
y_batch = predict(network, x_batch)
p = np.argmax(y_ batch, axis=1)
accuracy_cnt += np.sum(p == t[i:i+batch_size])
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
我们来逐个解释粗体的代码部分。首先是range()函数。range() 函数若指定为range(start, end), 则会生成一个由start到end-1之间的整数构成的列表。若像range(start,end,step)这样指定3个整数,则生成的列表中的下一个元素会增加step指定的值。
在range()函数生成的列表的基础上,通过 x[i : i+batch_ size] 从输人数据中抽出批数据。x[i : i+batch n] 会取出从第i个到第 i+batch_ n 个之间的数据。本例中是像 x[0 : 100]、x[100 : 200]…这样,从头开始以100为单位将数据提取为批数据。
然后,通过argmax()获取值最大的元素的索引。不过这里需要注意的是,我们给定了参数axis=1。这指定了在100 x 10的数组中,沿着第1维方向(以第1维为轴)找到值最大的元素的索引(第0维对应第1个维度)”。我们来看一个例子:
>>> x = np.array([[0.1, 0.8, 0.1],[0.3, 0.1, 0.6],
>>> [0.2, 0.5,0.3], [0.8, 0.1, 0.1]])
>>> y = np.argmax(x, axis=1)
>>> print(y)
[1 2 1 0]
最后,我们比较一下以批为单位进行分类的结果相实际的答案。为此,需要在NumPy数组之间使用比较运算符(==)生成由True/False构成的布尔型数组,并计算True的个数。我们]通过下面的例子进行确认。
>>> y = np,array([1, 2, 1, 0])
>>> t = np.array([1, 2,0,0])
>>> print(y==t)
[True True False True ]
>>> np. sum(y==t)
3
7. 小结
本章所学的内容
- 神经网络中的激活函数使用平滑变化的sigmoid函数或ReLU函数。
- 通过巧妙地使用NumPy多维数组,可以高效地实现神经网络。
- 机器学习的问题大体.上可以分为回归问题和分类问题
- 关于输出层的激活函数,回归问题中一般用恒等函数,分类问题中一般用softmax函数。
- 分类问题中,输出层的神经元的数量设置为要分类的类别数。
- 输入数据的集合称为批。通过以批为单位进行推理处理,能够实现高速的运算,