California Housing Prices Dataset(1990 sensus)
数据集:housing price
download:housing price
点击下载,然后出现网页,save as到desktop
打开jupyter notebook
导入预先需要的库,需要啥导入啥:
import matplotlib
import matplotlib.pyplot as plt # 用来画图
import pandas as pd # 专门处理数据
import numpy as np
import sklearn #专门用来机器学习
from sklearn.model_selection import train_test_split #一种方式用来,分离测试集和验证集
- 导入数据:csv文件(Comma-separated Value逗号分隔值)
#我下载在桌面
housing = pd.read_csv(r"C:\Users\richa\Desktop\housing.csv")
housing
- 查看前几行数据和后几行数据大致了解
housing.head(10)
housing.tail(10)
- 看看quick describe信息
housing.info()
- 发现最后一列ocean_proximity数据是对象(object),所以看看统计数值:
housing['ocean_proximity'].value_counts()
- 然后看看统一描述(显示平均值啊,方差啊,百分数之类):
housing.describe()
- 可视化看看(柱状图)
housing.hist(bins=50, figsize=(20,15)
# figsize=() 调整图的大小
- 简单浏览数据后,开始操作:先分出训练集和测试集
注意:(这是基于随机抽样,分成8:2)数据很大的时候,这么分还行。如果数据不够多,那么就会有抽样偏差(sample bias),思考人口中的分层抽样就明白了(stratified sampling:按比例抽样)
from sklearn.model_selection import train_test_split
np.random.seed(42) # 控制输出不变
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
# 20%测试,80%训练
test_set.head() #看看前5行
- 分层抽样,怎么抽?
比如你要选区median_income那列,由于是连续值,肯定要分成区间计算个数,然后计算占比(回忆人口)。那么问题来了,怎么分???
# Divide by 1.5 to limit the number of income categories
housing["income_cat"] = np.ceil(housing["median_income"] / 1.5)
# Label those above 5 as 5
housing["income_cat"].where(housing["income_cat"] < 5, 5.0, inplace=True)
或者
housing["income_cat"] = pd.cut(housing["median_income"],
bins=[0., 1.5, 3.0, 4.5, 6., np.inf],
labels=[1, 2, 3, 4, 5])
housing["income_cat"].value_counts()
housing["income_cat"].hist()
结果是由:
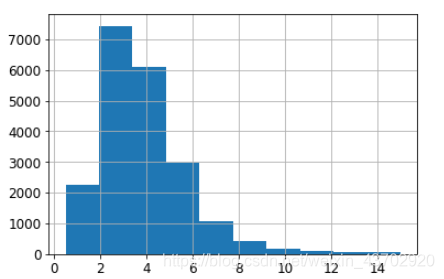
去掉大于5的,集中统计0到5:

这样就可以看出构造出比例了,然后再按照比例抽样 stratified sampling
- 分层采样:
由于 stratifiedshufflesplit这个验证方法调用后,把他叫做split,然后用它的split方法,按照分层比例分层抽样所有数据,函数返回的只是indices索引,所以有后面的语句。
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
- 验证一下,分层抽样好,还是直接随机好:
#计算分层的比例
def income_cat_proportions(data):
return data["income_cat"].value_counts() / len(data)
# 随机split得到的测试集和训练集
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
# 对比两种方法:
compare_props = pd.DataFrame({
"Overall": income_cat_proportions(housing),
"Stratified": income_cat_proportions(strat_test_set),
"Random": income_cat_proportions(test_set),
}).sort_index()
compare_props["Rand. %error"] = 100 * compare_props["Random"] / compare_props["Overall"] - 100
compare_props["Strat. %error"] = 100 * compare_props["Stratified"] / compare_props["Overall"] - 100
compare_props
结果如图:

行吧,想都不要想肯定是分层抽样更好…stratified sampling