总体架构

with open() as f
python open
r: 就是默认的 读
w: 写之前,清除文件内内容。
b: 二进制Bytes。 未解码成str
t: str 已经解码过,可阅读文字
+: 用于更新。
a: 尾+

pickle
模块 pickle 实现了对一个 Python 对象结构的二进制序列化和反序列化。 “pickling” 是将 Python 对象及其所拥有的层次结构转化为一个字节流的过程,而 “unpickling” 是相反的操作,会将(来自一个 binary file 或者 bytes-like object 的)字节流转化回一个对象层次结构。 pickling(和 unpickling)也被称为“序列化”, “编组” 1 或者 “平面化”。而为了避免混乱,此处采用术语 “封存 (pickling)” 和 “解封 (unpickling)”。
python doc for “pickle”


matplotlib.pyplot
Reference:
简单的理解fig axes
matplotlib.pyplot
matlab-like way of plotting
# 调用方式
subplot(nrows, ncols, index, **kwargs)
subplot(pos, **kwargs)
subplot(**kwargs)
subplot(ax)
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(0, 5, 0.1)
y = np.sin(x)
plt.plot(x, y)
plt.subplot(221)
# equivalent but more general
ax1=plt.subplot(2, 2, 1)
# add a subplot with no frame
ax2=plt.subplot(222, frameon=False)
# add a polar subplot
plt.subplot(223, projection='polar')
# add a red subplot that shares the x-axis with ax1
plt.subplot(224, sharex=ax1, facecolor='red')
# delete ax2 from the figure
plt.delaxes(ax2)
# add ax2 to the figure again
plt.subplot(ax2)
pytorch 的tensor.nonzero() 和 numpy中的array.nonzero()
1. pytorch中返回一个包含输入Input中非0元素索引的张量(以张量的形式返回非0索引)
我们可以看到,返回的tensor里,每个list中的元素是Lable张量中补位0的元素的坐标值!
 2. numpy中的nonzero()返回的是,分开的维度的坐标值!
2. numpy中的nonzero()返回的是,分开的维度的坐标值!
# find bounds
nz_r,nz_c = fg.nonzero() #return non zeros r= row c = colunm
l,r = max(0,min(nz_c)-1),min(n_c-1,max(nz_c)+1)+1 # left and right boundary for characters
t,b = max(0,min(nz_r)-1),min(n_r-1,max(nz_r)+1)+1 # top and bottom
# extract window
win = fg[t:b,l:r]

2种修改图片大小的库函数
1.PIL的Image.resize()
from PIL import Image
#transfer from np.arary to image format
win_img = Image.fromarray(win.astype(np.uint8)*255)
resize_img = win_img.resize((new_c,new_r))
- skimage 的 transform.resize()
全称[scikit - image],联想scikit-learn: sklearn [滑稽脸]
more materials
new_img=skimage.transform.resize(img,(32,32), mode='constant',anti_aliasing=False)

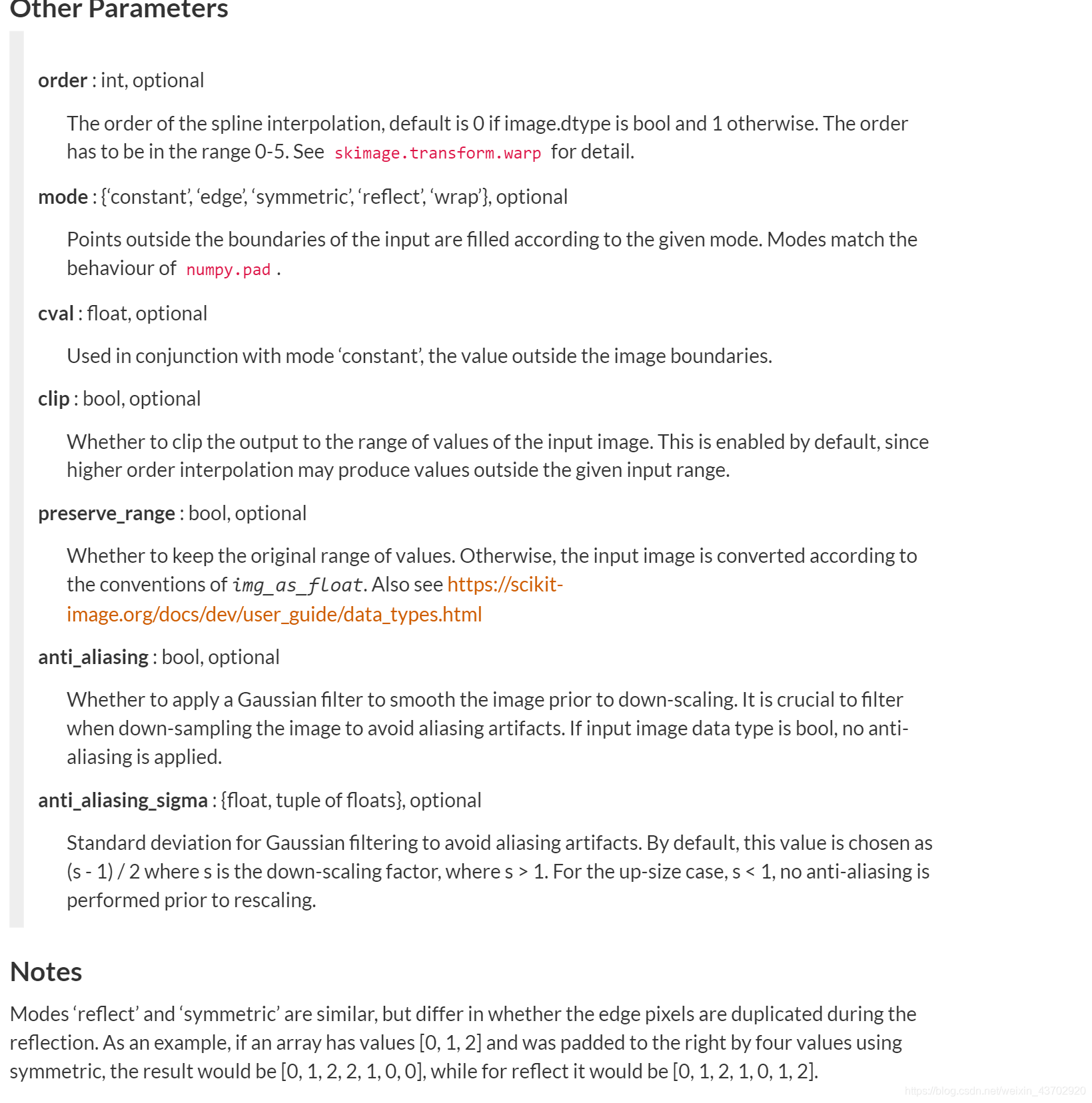
skimage.filters
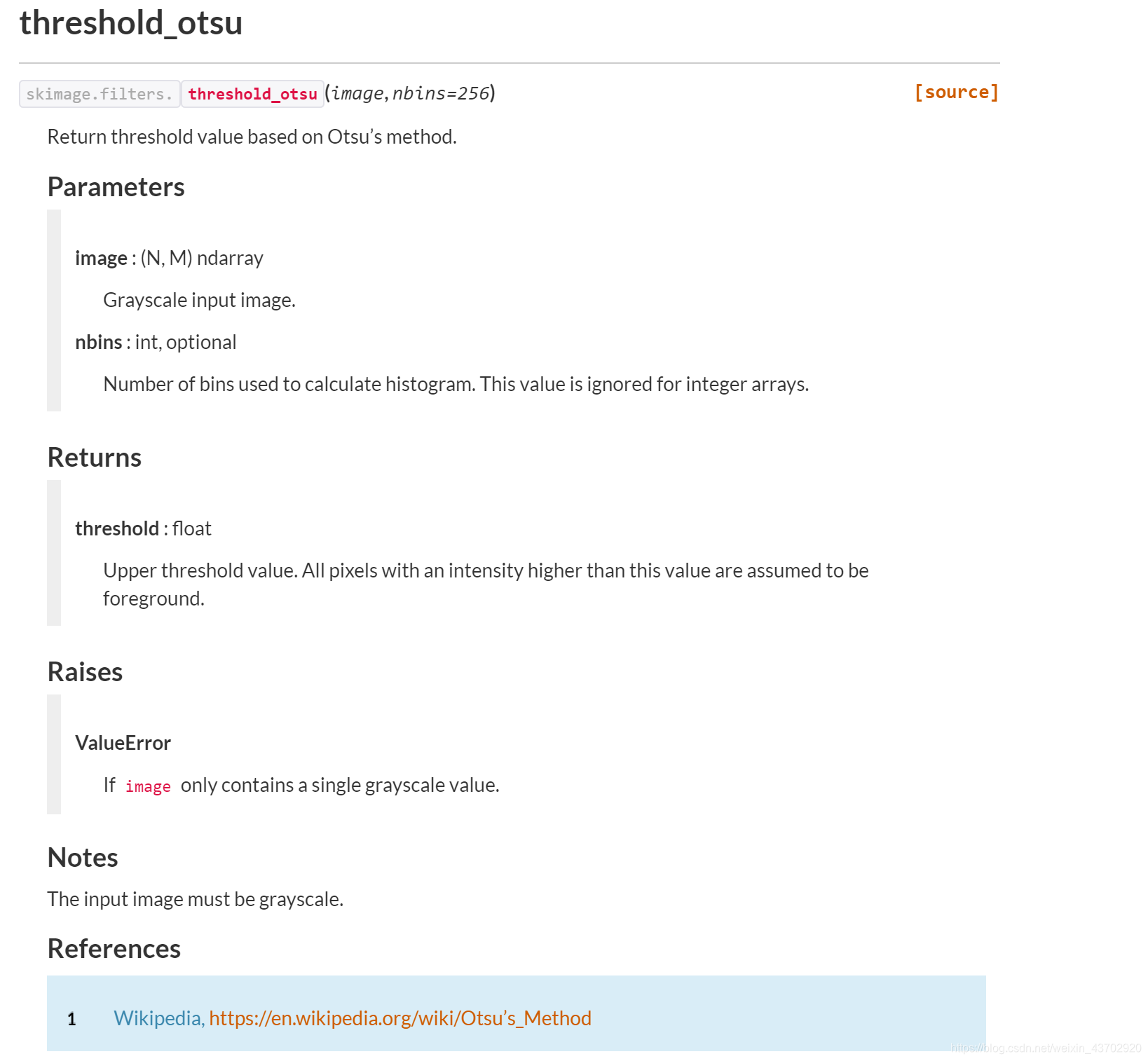
thresh = filt.threshold_otsu(new_img)
bi_img = new_img > thresh
Early stopping 早停防止过拟合
# Early stopping class
class EarlyStopping:
"""Early stops the training if validation loss doesn't improve after a given patience."""
def __init__(self, patience=7, verbose=False, delta=0):
self.patience = patience # 可以忍受的高于保存的最低loss的epoch数目
self.verbose = verbose # 是否显示验证集损失变化的具体内容,见self.save_checkpoint()
self.counter = 0
self.best_score = None # 最好的score == 最小的loss
self.early_stop = False # 早停标志
self.val_loss_min = np.Inf # 初始化最低的验证集损失
self.delta = delta # 允许的波动
def __call__(self, val_loss, model): # private
score = -val_loss # loss的负数表示分数
if self.best_score is None: # 初始化肯定没有,所以先这样判断
self.best_score = score
self.save_checkpoint(val_loss, model)
elif score < self.best_score + self.delta:
self.counter += 1 # 计数
print(f'EarlyStopping counter: {self.counter} out of {self.patience}')
if self.counter >= self.patience: # 超出了patience就早停
self.early_stop = True
else:
self.best_score = score # 新的loss历史最低==score分数历史最高
self.save_checkpoint(val_loss, model) # 保存参数文件
self.counter = 0 # 重新计数
def save_checkpoint(self, val_loss, model): # 保存参数
'''Saves model when validation loss decrease.'''
if self.verbose: # 是否打印具体loss参数
print(f'Validation loss decreased ({self.val_loss_min:.6f} --> {val_loss:.6f}). Saving model ...','\n')
torch.save(model.state_dict(), 'checkpoint.pt') # 存储模型的参数字典
self.val_loss_min = val_loss
输入神经网络层后的大小计算
int((in_size - kernel_size + 2(padding)) / stride) + 1*
# convert image to tensor that fits into CNN
def outputSize(in_size, kernel_size, stride, padding):
output = int((in_size - kernel_size + 2*(padding)) / stride) + 1
return(output)
def show_batch(epoches,loader):
for epoch in range(epoches): # train 对每一个epoch, 枚举dataloader中的批次
for step, (batch_x, batch_y) in enumerate(loader): # for each training step
# train your data...
print('Epoch: ', epoch, '| Step: ', step, '| batch x: ',
batch_x.numpy(), '| batch y: ', batch_y.numpy())
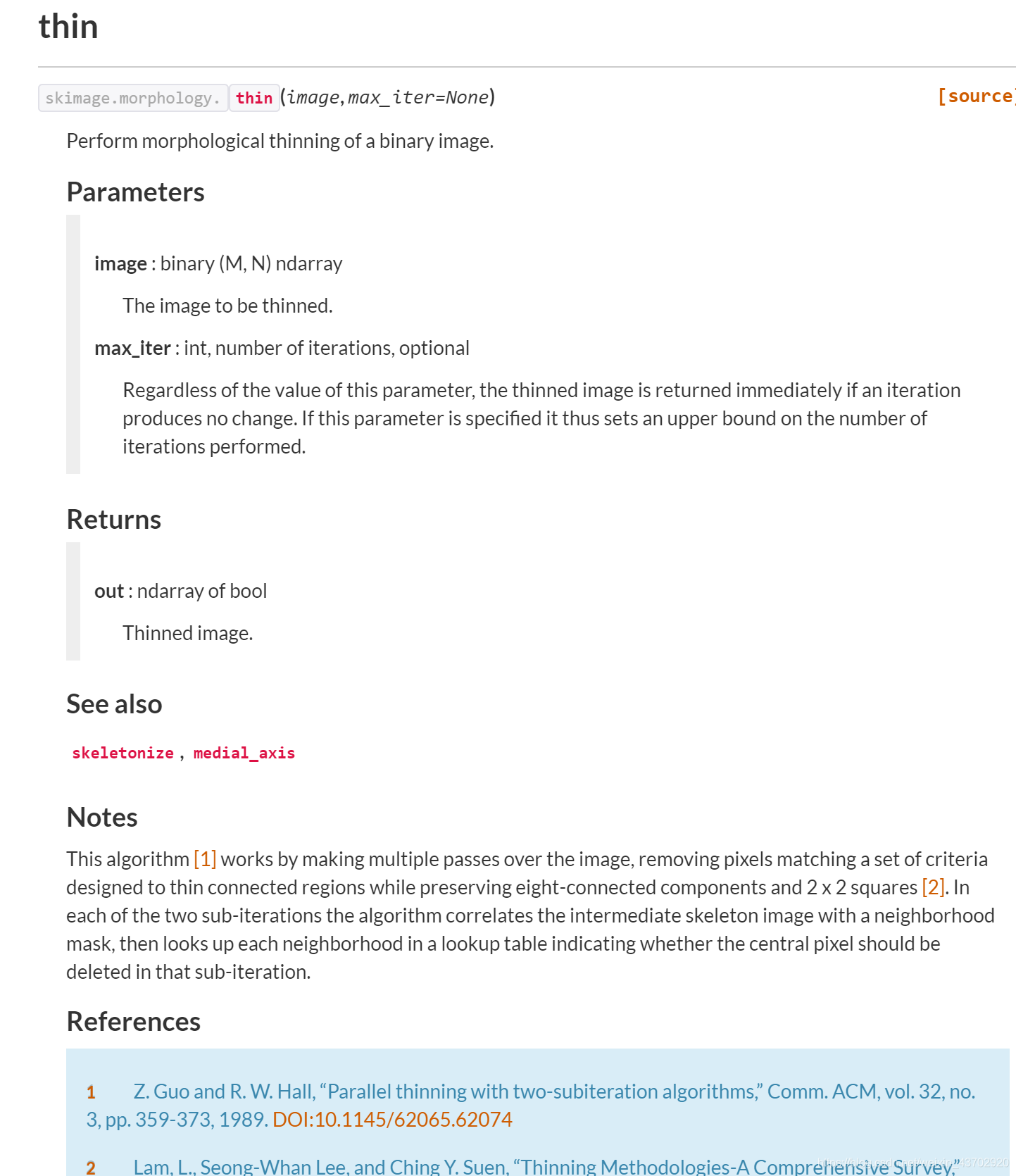
thin
from skimage.morphology import thin
模型Class with 初始化
- 一定要在进入激活函数前进入 BatchNorm2d or BatchNorm1d
- (1,32,32)-> (16, 32,32) ->( 32, 32,32) -> (3288, 64) ->(64, 8 )
# model
# model
class LetterCNN(nn.Module):
def __init__(self):
super(LetterCNN,self).__init__() # super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=1, # only 1 channel
out_channels=16,
kernel_size=5,
stride=1,
padding=2
), # shape 16,32,32 (channels,size)
nn.BatchNorm2d(16), # 批次归一化
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)# shape (16,16,16) # 最大池化
)
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=16,
out_channels=32,
kernel_size=5,
stride=1,
padding=2
),#(32,16,16)
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2) #(32,8,8)
)
self.fc1=nn.Linear(32*8*8,64) # fc1 full-connected layer 1
self.bn = nn.BatchNorm1d(64) # batch normalization
self.relu = nn.ReLU() # relu
self.fc2=nn.Linear(64,8) # full connected layer 2
def forward(self,x):
x=self.conv1(x)
x=self.conv2(x)
x=x.view(x.size(0),-1) # flatten the output to (batch_size, 32 * 8 * 8)
x = self.fc1(x)
x = self.bn(x)
x = self.relu(x)
# x = F.relu(x)
x = self.fc2(x) #
return x # return x this is unormalizaed x
# Initialize weights and bias
def Init_weights(self):
for m in self.modules(): # 遍历每一个子模块
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n)) # if it is convolution layer for Relu activation
if m.bias is not None: # applying "He initializaiton"
m.bias.data.zero_() # and set bias to 0 #所有带有_ 的都是 inplaced的方法
elif isinstance(m, nn.BatchNorm2d): # set BN layer to w=1,b=0
m.weight.data.fill_(1) #所有带有_ 的都是 inplaced的方法
m.bias.data.zero_() #所有带有_ 的都是 inplaced的方法
elif isinstance(m, nn.Linear): # set full connected layer to b=0, w belongs to nomal distibution
m.weight.data.normal_(0, 0.01) #所有带有_ 的都是 inplaced的方法
m.bias.data.zero_() #所有带有_ 的都是 inplaced的方法
elif isinstance(m, nn.BatchNorm1d): # set BN layer to w=1,b=0
m.weight.data.fill_(1) #所有带有_ 的都是 inplaced的方法
m.bias.data.zero_()
开始训练
- 初始化model = LetterCNN()
- 权重初始化
model.apply(Init_weights)
model.Init_weights()
- 初始化损失函数Loss ,交叉熵函数。
import torch.nn as nn
lossCriterion = nn.CrossEntropyLoss(weight=torch.FloatTensor([1.4,1.4,0.8,0.8,1,0.9,0.9,1])) # we use crossentropy loss criterio
- 初始化优化器optimizer
import torch.optim as optim
optimizer = optim.SGD(model.parameters(), lr=learningRate, momentum=momentum) # momentum method /lr=0.01 before
- 初始化 学习率布局函数
from torch.optim.lr_scheduler import MultiStepLR
scheduler = MultiStepLR(optimizer, milestones=[6,15,20,30], gamma=0.7)
- 初始化早停类
early_stopping = EarlyStopping(patience=patience, verbose=True)
- 开始epoch iteration 循环训练
可以参考
import torch.nn.functional as F
for epoch in range(epoches): # epoches
model.train()
for iteration,(images,labels) in enumerate(train_loader): # for each step/block for training loader
#批次数据输入后输出标签
outputs = model(images)
# 得到输出标签后,可以计算loss损失
loss = lossCriterion(outputs,labels) # get loss for every step
#在loss反向传播之前要清空之前的梯度累计
optimizer.zero_grad() # To avoid gradient sums
# 然后再进行反向传播
loss.backward() # back propagation
# 传播过程中。优化器进行梯度下降优化
optimizer.step() #All optimizers implement a step() method, that updates the parameters.
pro8=F.softmax(outputs,dim=1).data # 注意这里的维度dim=1
_,predicted = torch.max(pro8,1) # 反回最大的概率标签
#注意在一个epoch后要进行validate验证
model.eval() #开启测试模式,关闭批次归一化的tracking
for j,(images,labels) in enumerate(validation_loader): # loader with all the data
# 输出output概率
outputs = model(images)
#预测标签
_,predicted = torch.max(F.softmax(outputs,dim=1),1)
correct_val = (predicted == labels).sum().item()
# 在验证数据集输入完毕后,计算验证集合的损失,进行是否早停的判断
early_stopping.__call__(val_loss, model)
#
scheduler.step()
Loss, Accuracy 画图
接着上面,每次验证完毕都画avg_loss, 准确率的图形
# checkpoint
model.load_state_dict(torch.load('checkpoint.pt'))
# plot the accuracy and loss
fig = plt.figure(num=2, figsize=(15, 8),dpi=80)
ax1 = fig.add_subplot(2,1,1)
ax2 = fig.add_subplot(2,1,2)
ax1.plot(range(len(accuracy_list)),accuracy_list,color='g',label='Train_Accuracy')
ax1.plot(range(len(val_accuracy_list)),val_accuracy_list,color='r',label='Validation_Accuracy')
ax2.plot(range(len(loss_list)),avg_loss_per_epoch_list,color='g',label='Train_Loss')
ax2.plot(range(len(val_avg_loss)),val_avg_loss,color='r',label='validation_Loss')
ax1.set_xlabel('Epochs')
ax2.set_xlabel('Epochs')
ax1.set_ylabel('Accuracy')
ax2.set_ylabel('Loss')
ax1.set_title('Accuracy')
ax2.set_title('Loss')
ax1.legend()
ax2.legend()
载入训练集和验证集
from torch.utils import Data
from troch.utils.Data import Dataset
epoches = 50 #fix
batch_size = 80 # fix
############
# 训练集和验证集进行预处理
train_data_tensor=preprocessing(train_data_)
validation_data_tensor=preprocessing(validation_data_)
# 转变为dataset格式(数据,标签),然后变成Dataloader用来枚举index,(images,labels)
train_dataset = Data.TensorDataset(train_data_tensor,torch.LongTensor(np.asarray(train_labels_)-1)) # we have to modify the label to [0,7] due to cross-entropy loss function
train_loader = Data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# validation loader
validation_dataset = Data.TensorDataset(validation_data_tensor,torch.LongTensor(np.asarray(validation_labels_)-1))
validation_loader = Data.DataLoader(validation_dataset, batch_size=len(validation_dataset))
##########################################
# train and validate
train_validate(0.02,patience=4)
-1类别
from sklearn.ensemble import IsolationForest
from sklearn.svm import OneClassSVM
# 初始化模型然后载入参数字典
model=LetterCNN()
model.load_state_dict(torch.load('checkpoint.pt'))
# evaluate评估
model.eval()
image_tensor=preprocessing(train_data)
output=model(image_tensor)
prob8=F.softmax(output,dim=1).data
# 隔离森林
clf=IsolationForest(n_estimators=140,behaviour='new',max_samples='auto',contamination=0.001,max_features=5)
clf.fit(prob8)
# 单类SVM
clf1 = OneClassSVM(kernel='rbf',tol=0.01,nu=0.001)
clf1.fit(prob8)
# 存储模型
with open('iso_train.pickle', 'wb') as f:
pickle.dump(clf,f)
with open('svm_train.pickle', 'wb') as f:
pickle.dump(clf1,f)
杂碎
- numpy array 的 ravel() 和 flatten()效果一样

- plt的颜色map
import matplotlib.pyplot as plt
plt.imshow(bi_img,cmap=plt.cm.gray)