数据集介绍:
mnist数据集使用tensorflow封装好的数据(包含6000张训练数据,1000张测试数据),图片大小为28x28。
在神经网络的结构上,一方面需要使用激活函数去线性化。另一方面需要增加网络的层数以解决更加复杂的问题。
关于tensorflow中的几个函数:
1. tf.Variable()和 tf.get_variable()中的区别:
tf.Variable(): 创建一个变量,
tf.get_variable(): 创建或者获取一个变量,在用来创建变量时,和 tf.Variable()功能基本相同。
这两个函数不同的地方是,tf.Variable()函数,变量名称时可选的参数。tf.get_variable()变量名称是必填的参数,它会根据这个名称去创建或者获取变量。
(引用自:https://blog.csdn.net/weixin_38698649/article/details/80099822)
变量共享主要涉及两个函数:tf.variable() 和tf.get_variable();即就是必须要在tf.variable_scope的作用域下使用tf.get_variable()函数。这里用tf.get_variable( ) 而不用tf.Variable( ),是因为tf.get_variable( ) 拥有一个变量检查机制,会检测已经存在的变量是否设置为共享变量,如果已经存在的变量没有设置为共享变量,TensorFlow 运行到第二个拥有相同名字的变量的时候,就会报错。
两个创建变量的方式。如果使用tf.Variable() 的话每次都会新建变量。但是大多数时候我们是希望重用一些变量,所以就用到了get_variable(),它会去搜索变量名,有就直接用,没有再新建。
既然用到变量名了,就涉及到了名字域的概念。通过不同的域来区别变量名,毕竟让我们给所有变量都取不同名字还是很辛苦。这就是为什么会有scope 的概念。name_scope 作用于操作,variable_scope 可以通过设置reuse 标志以及初始化方式来影响域下的变量,因为想要达到变量共享的效果, 就要在 tf.variable_scope()的作用域下使用 tf.get_variable() 这种方式产生和提取变量. 不像 tf.Variable() 每次都会产生新的变量, tf.get_variable() 如果遇到了已经存在名字的变量时, 它会单纯的提取这个同样名字的变量,如果不存在名字的变量再创建.。
2. name_scope和variable_scope的区别
TF中有两种作用域类型
命名域 (name scope),通过tf.name_scope 或 tf.op_scope创建;
变量域 (variable scope),通过tf.variable_scope 或 tf.variable_op_scope创建;
这两种作用域,对于使用tf.Variable()方式创建的变量,具有相同的效果,都会在变量名称前面,加上域名称。
对于通过tf.get_variable()方式创建的变量,只有variable scope名称会加到变量名称前面,而name scope不会作为前缀。例如 print(v1.name) # var1:0
网络的结构如图所示:
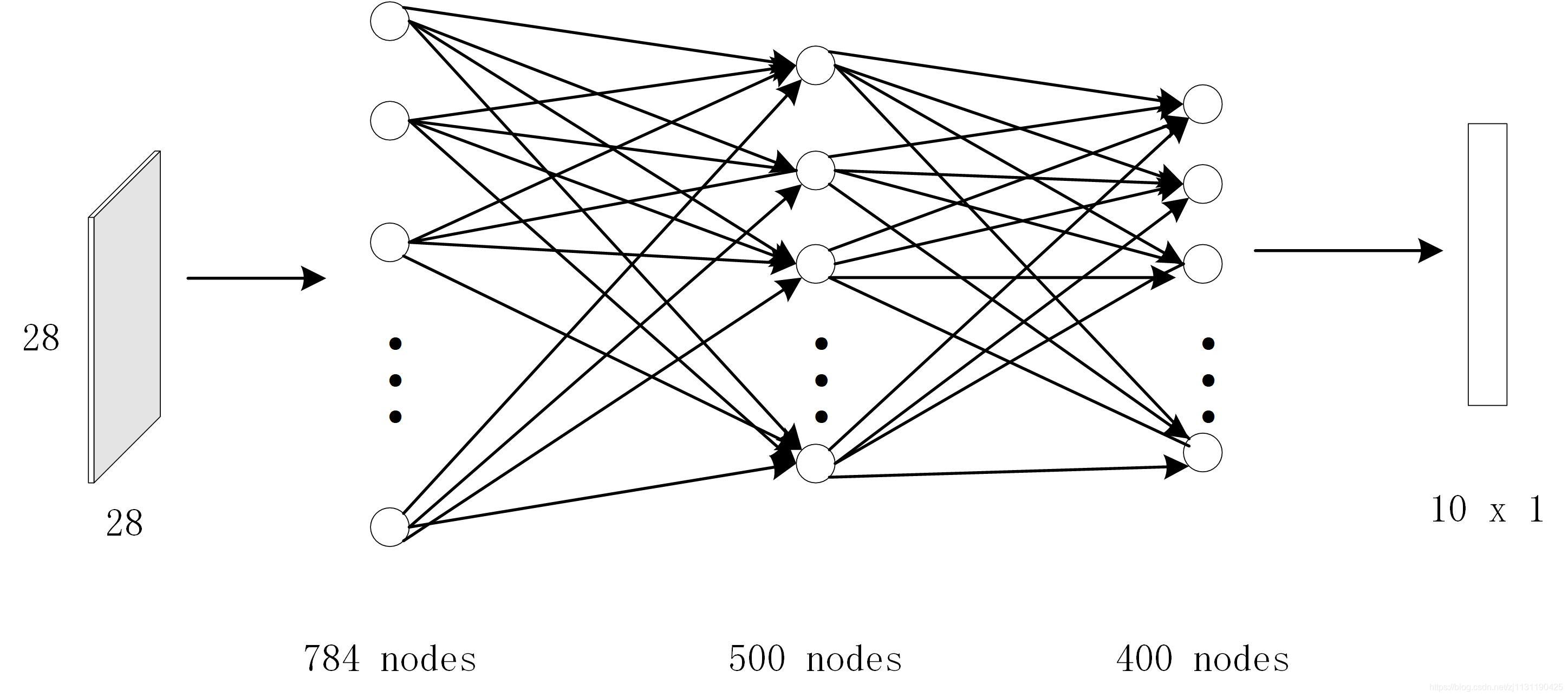
tensorflow实现:
# encoding: utf-8
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
class TrainData:
def __init__(self, data_path, batch_size=100):
"""
:param data_path: 训练数据路径
"""
self.batch_size = batch_size
self.mnist = input_data.read_data_sets(train_dir=data_path, one_hot=True)
def display_data_info(self):
"""
输出数据集的信息
:return:
"""
print("-"*40)
print("training data size: {}".format(self.mnist.train.num_examples))
print("test data size: {}".format(self.mnist.test.num_examples))
print("validation data size: {}".format(self.mnist.validation.num_examples))
print("-"*40)
def next_batch(self):
"""
获取下一个batch的数据 经过处理后的图片为(28x28=784)的一维数组
:return:
"""
xs, ys = self.mnist.train.next_batch(self.batch_size) # 返回训练数据和标签 xs: [batch_size, 784]
return xs, ys
def validation_data(self):
"""
返回验证集
:return:
"""
images, labels = self.mnist.validation.images, self.mnist.validation.labels
return images, labels
def test_data(self):
"""
返回测试集
:return:
"""
images, labels = self.mnist.test.images, self.mnist.test.labels
return images, labels
class Model:
def __init__(self, input_node, output_node, layer1_node, layer2_node, regularizer=False, moving_average=False):
"""
:param input_node: 输入数据的维度
:param output_node: 输出数据的维度
:param layer1_node: 隐藏层
:param layer2_node: 隐藏层
:param regularizer: L2正则化
:param moving_average: 滑动平均模型
"""
self.input_node = input_node
self.output_node = output_node
self.layer1_node = layer1_node
self.layer2_node = layer2_node
# self.train_step = train_step
self.regularizer = regularizer
self.moving_average = moving_average
self.moving_average_decay = 0.99 # 滑动平均衰减率
# self.batch_size = batch_size
"""
关于滑动平均模型:
实际的原理是对参数的更新进行一阶之后滤波
对每一个参数会维护一个影子变量shadow_variable
shadow_variable = shadow_variable * decay + (1 - decay) * variable
decay 决定了模型的更心速度
num_updates参数来动态设置参数的大小
decay = min{decay, (1+num_updates)/(10+num_up_dates)}
"""
self.learning_rate_base = 0.0001 # 初始学习率
self.learning_rate_decay = 0.98 # 学习率的衰减速度
self.regularizer_rate = 0.001 # 正则化lambda
with tf.name_scope("placeholder"): # 变量名
self.x = tf.placeholder(dtype=tf.float32, shape=[None, self.input_node], name='x-input')
self.y_ = tf.placeholder(dtype=tf.float32, shape=[None, self.output_node], name='y-input')
with tf.name_scope("weights"):
# 网络第一层
self.weight1 = tf.get_variable(initializer=tf.random_normal(dtype=tf.float32,
shape=[self.input_node, self.layer1_node],
mean=0, stddev=1),
name='weight1')
self.biases1 = tf.get_variable(initializer=tf.constant_initializer(0.0), shape=[self.layer1_node],
dtype=tf.float32, name='biases1')
self.layer1 = tf.nn.relu(tf.matmul(self.x, self.weight1) + self.biases1) # 第一层
# 正则化
if self.regularizer:
tf.add_to_collection(name='loss', value=tf.contrib.layers.l2_regularizer(self.regularizer_rate)(self.weight1))
# 网络第二层
self.weight2 = tf.get_variable(initializer=tf.random_normal(dtype=tf.float32,
shape=[self.layer1_node, self.layer2_node],
mean=0, stddev=1),
name='weight2')
self.biases2 = tf.get_variable(initializer=tf.constant_initializer(0.0), shape=[self.layer2_node],
dtype=tf.float32, name='biases2')
self.layer2 = tf.nn.relu(tf.matmul(self.layer1, self.weight2) + self.biases2)
# 正则化
if self.regularizer:
tf.add_to_collection(name='loss', value=tf.contrib.layers.l2_regularizer(self.regularizer_rate)(self.weight2))
# 网络第三层 全连接层
self.weight3 = tf.get_variable(initializer=tf.random_normal(dtype=tf.float32, shape=[self.layer2_node, self.output_node],
mean=0, stddev=1),
name='weight3')
self.biases3 = tf.get_variable(initializer=tf.constant_initializer(0.0), shape=[self.output_node],
dtype=tf.float32, name='biases3')
self.y = tf.matmul(self.layer2, self.weight3) + self.biases3 # 网络输出
# 定义损失函数
with tf.name_scope('create_loss'):
# 计算交叉熵损失函数
# 问题只有一个正确答案的时候,可以使用sparse_softmax_cross_entropy_with_logits来计算交叉熵
# 这个函数可以加速交叉熵的计算
# 但是这个函数需要提供的正确答案是一个数字,而不是one-hot向量
self.cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=self.y, labels=tf.argmax(self.y_, 1))
self.cross_entropy_mean = tf.reduce_mean(self.cross_entropy)
tf.add_to_collection(name='loss', value=self.cross_entropy_mean)
self.loss = tf.add_n(tf.get_collection('loss')) # 总的loss
with tf.name_scope("optimizer"):
self.optimizer = tf.train.AdamOptimizer(self.learning_rate_base).minimize(self.loss)
with tf.name_scope("evaluate"): # 验证集
self.correct_prediction = tf.equal(tf.argmax(self.y, 1), tf.argmax(self.y_, 1))
self.accuracy = tf.reduce_mean(tf.cast(self.correct_prediction, dtype=tf.float32), name="accuracy")
# tensorboard显示数据
with tf.name_scope("summary"):
tf.summary.scalar("loss", self.loss)
tf.summary.scalar("accuracy", self.accuracy)
self.summary_op = tf.summary.merge_all()
def train(self, train_data, train_step=300):
"""
训练数据
:param train_data:
:param train_step:
:return:
"""
with tf.Session() as sess:
init_op = tf.group(tf.local_variables_initializer(), tf.global_variables_initializer())
sess.run(init_op)
# train_data = TrainData(data_path=train_data_path, batch_size=self.batch_size)
board_data = r"E:\back_up\code\112\tensorflow_project\newbook\chapter3\model\tensorboard" # tensorboard数据保存路径
model_save = r'E:\back_up\code\112\tensorflow_project\newbook\chapter3\model\garph\graph'
writer = tf.summary.FileWriter(logdir=board_data, graph=sess.graph) # 保存tensorboard中的数据
saver = tf.train.Saver(tf.global_variables(), max_to_keep=2) # 保存模型
for step in range(train_step): # 开始训练
xs, ys = train_data.next_batch()
feed_dict = {self.x: xs, self.y_: ys}
_, loss, summary = sess.run([self.optimizer, self.loss, self.summary_op], feed_dict=feed_dict)
# print("loss after {} steps is {}".format(step, loss))
if step % 200 == 0:
feed_dict = {self.x: train_data.validation_data()[0], self.y_: train_data.validation_data()[1]}
accuracy = sess.run(self.accuracy, feed_dict=feed_dict)
print("After {} step accuracy is {}".format(step, accuracy))
# 保存模型
saver.save(sess=sess, save_path=model_save)
# 保存tensorboard数据
writer.add_summary(summary=summary, global_step=step)
def predict(train_data):
"""
对输入的值进行预测
:param train_data: 输入数据
:return:
"""
# 加载训练好的模型
model_load = r"E:\back_up\code\112\tensorflow_project\newbook\chapter3\model\garph"
sess = tf.Session()
check_point_file = tf.train.latest_checkpoint(model_load)
saver = tf.train.import_meta_graph("{}.meta".format(check_point_file), clear_devices=True)
saver.restore(sess=sess, save_path=check_point_file)
graph = sess.graph
test_data = graph.get_operation_by_name("placeholder/x-input").outputs[0]
test_label = graph.get_operation_by_name("placeholder/y-input").outputs[0]
test_accuracy = graph.get_operation_by_name("evaluate/accuracy").outputs[0]
feed_dict = {test_data: train_data.test_data()[0], test_label: train_data.test_data()[1]}
accuracy = sess.run(test_accuracy, feed_dict=feed_dict)
print("The test accuracy is {}".format(accuracy))
if __name__ == '__main__':
data_path = r'E:\code\112\tensorflow_project\chapter5\data\tensorflow_data'
train_data = TrainData(data_path=data_path, batch_size=200)
model = Model(input_node=784, output_node=10, layer1_node=500, layer2_node=400, regularizer=True)
model.train(train_data=train_data, train_step=30000)
print("---------test-----------")
predict(train_data=train_data)
运行程序开始训练: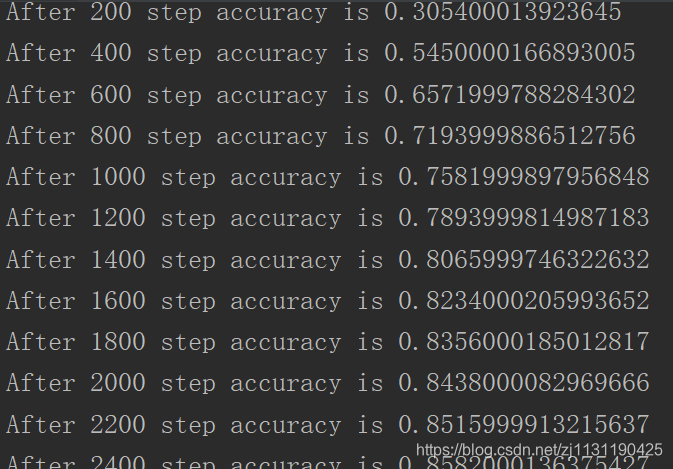
在cmd中输入如下命令:
tensorboard -logdir="E:\back_up\code\112\tensorflow_project\newbook\chapter3\model\garph"如下图所示: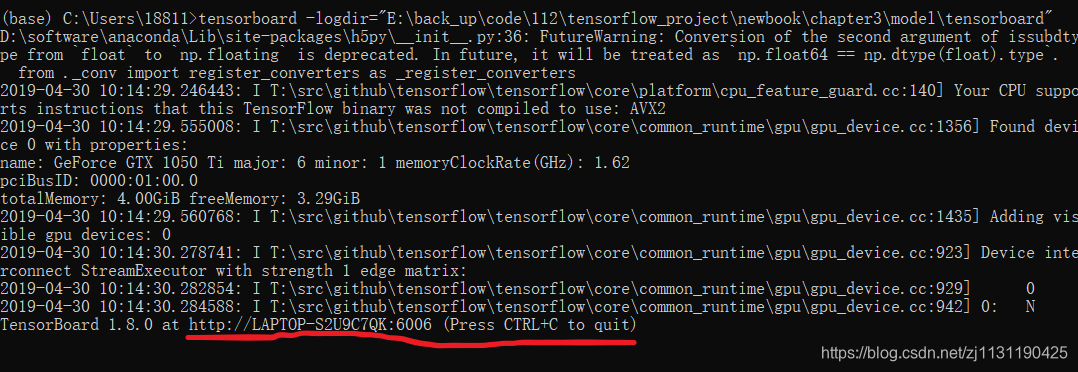
将后面的地址复制到浏览器:
可以看到训练的loss和验证集的accuracy:
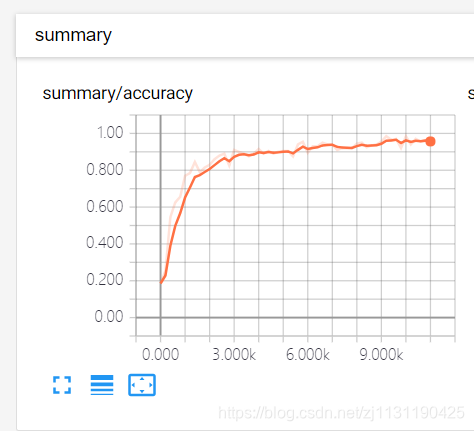
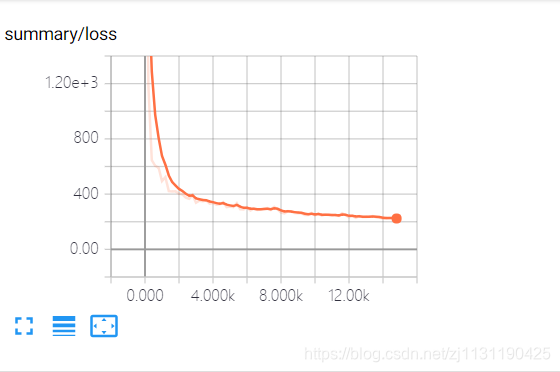
最后,通过predict()函数加载训练好的模型,求出测试集在模型上的精度:
神经网络模型最终的目标是对未知数据提供判断,所以为了对模型未知数据上的表现进行判断,需要保证测试数据在训练过程中不可见,为了评估模型在不同参数下的效果,通常会从训练数据中抽取一部分数据作为验证集。如果验证数据集不能很好的代表测试数据集的分布,则模型在这两个数据集上的表现很可能是不一样的。