今天帮师兄去做携程的数据分析的笔试时,在编程题里有一题的名字叫XX的贝叶斯,顾名思义就是贝叶斯模型,具体的题目忘记了,大概就是题目就是,根据train这些预测test_data的结果。当然数据使我瞎编的,特征少了很多,最后的输出具体是什么我也忘了,是一个概率,应该在多添加几步就出来答案了。但是写出来程序应该是一样的。
import numpy as np
import os
#P(B|A)=P(A|B)*P(B)/P(A)
#####P(类别|特征)=P(特征|类别)P(类别)/P(特征)
'''假设数据集是这样,最后一列是特征(labels),前面两列是数据(dataset)
| 天气 | 心情 | 是否打球 ?|
| 1 | 1 | 1 |
| 0 | 1 | 1 |
| 1 | 0 | 0 | ####train
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 0 | 0 | 0 |
| 0 | 0 | ? | #####test_data
'''
class Bayes:
def __init__(self):
self.length=-1
self.labelrate=dict() ####P(类别)
self.vectorrate=dict() #####训练各个类别的向量集
def fit(self,dataset,labels):
if len(dataset)!=len(labels):
raise ValueError("输入测试数组和类别数组长度不一致")
self.length=len(dataset[0])#训练数据特征值的长度
labelsnum=len(labels) #类别的数量
norlabels=set(labels) #不重复类别的数量
for item in norlabels:
self.labelrate[item]=labels.count(item)/labelsnum #####P(类别)={0:1/3,1:2/3}
for vector,label in zip(dataset,labels):
if label not in self.vectorrate:
self.vectorrate[label]=[]
self.vectorrate[label].append(vector) ####vectorrate={0:[0,0],1:[[1,1],[0,1]]}
print("训练结束")
return self
def btest(self,testdata,labelset): ####labelset=[0,1]
if self.length==-1:
raise ValueError("未开始训练,先训练")
#计算testdata分别为各个类别的概率
lbDict=dict()
for thislb in labelset:
p = 1
alllabel = self.labelrate[thislb] ####thislb=0,alllabel=1/3; thislb=1,alllabel=2/3
print(alllabel)
allvector = self.vectorrate[thislb] ####thislb=0,allvector=[0,0]; thislb=1,allvector=[ [1,1],[0,1] ]
vnum=len(allvector)
allvector=np.array(allvector).T
for index in range(0,len(testdata)):
vector=list(allvector[index])
p*=vector.count(testdata[index])/vnum ####P(特征|类别)
print(p)
lbDict[thislb]=p * alllabel ####将P(类别|特征)排序此处表示的应该是P(类别|特征)*P(特征),因为无论是其取0,或者1的概率,他们的P(特征)都是一样的,所以不影响最后的的大小。
return lbDict
测试数据如上表所示,先其格式化进行处理。
train=np.array([[1,1]
,[0,1]
,[1,0]
,[0,1]
,[1,0]
,[0,0]])
labels=[1,1,0,1,1,0]
test_data=np.array([1,0])
labelset=[1,0]
先训练测试集
bys.fit(train,labels)
测试数据。
k=bys.btest(test_data,labelset)
测试结果如图所示。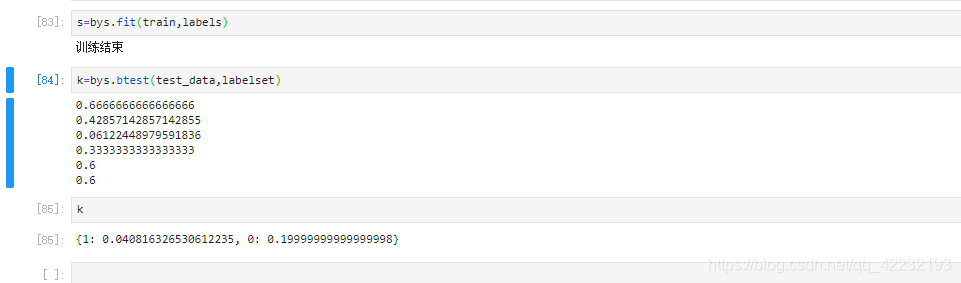
最后为1的概率为0.040816326530612235,0的概率为0.19999999999999998,这个结果代表的是P(类别|特征)*P(特征),因为无论是其取0,或者1的概率,他们的P(特征)都是一样的,所以不影响最后的的大小和我们最后的决策。