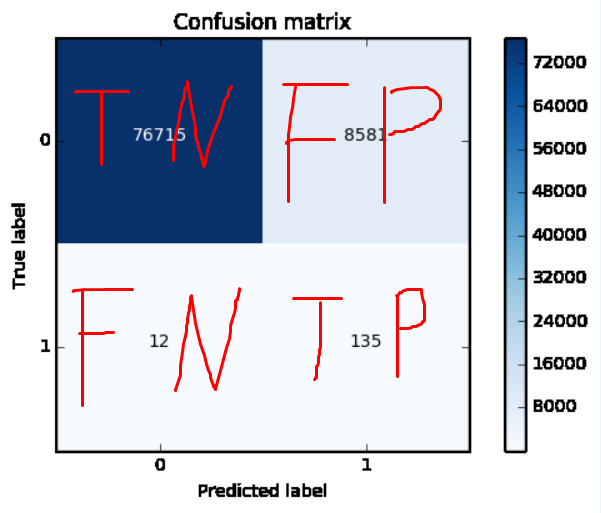
案例描述:在一个传染病数据集中,有80000个标签为不是传染病的记为负例(negtive),150个标签为是传染病的记为正例(positive),实际上我们的目标就是第一,在测试集测试的时候让这些正样本能够尽可能多得预测出来(TP)。第二,我们不希望模型把一个正常样本预测为有传染病(FP)(那不得把人吓死)。在目标第一点第二点中都提到了正例,说明影响模型可靠性的也是这些正例,我们的关注点也正是这些正例。而ROC曲线正好能够反应出来,尤其是在样本不均衡时。
1.ROC曲线相关知识
横轴:负正类率(false postive rate FPR)特异度,划分实例中所有负例占所有负例的比例;(1-Specificity)
纵轴:真正类率(true postive rate TPR)灵敏度,Sensitivity(正类覆盖率)
在一个二分类问题中,将实例分成正类(postive)或者负类(negative)。但是实际中分类时,会出现四种情况.
(1)若一个实例是正类并且被预测为正类,即为真正类(True Postive TP)
(2)若一个实例是正类,但是被预测成为负类,即为假负类(False Negative FN)
(3)若一个实例是负类,但是被预测成为正类,即为假正类(False Postive FP)
(4)若一个实例是负类并且被预测成为负类,即为真负类(True Negative TN)
TP:正确的肯定数目
FN:漏报,没有找到正确匹配的数目(这事就严重了,万一人家到处跑咋办)

FP:误报,没有的匹配不正确(相比漏报没那么严重,也就是隔离而已)
TN:正确拒绝的非匹配数目
真正例率 TPR = TP / (TP + FN)-----------------(预测对了为正(人家本来就是正的))占(真实为正的比例)
假正例率 FPR = FP / (TN + FP)-------------(预测错了为正(人家本来是负的))占(真实负例的比例)
一开始说了,我们只关心那些真正的正例和乌龙的正例
下图中绿色代表阈值,黄色是TN,紫色FP,粉色FN,灰色TP
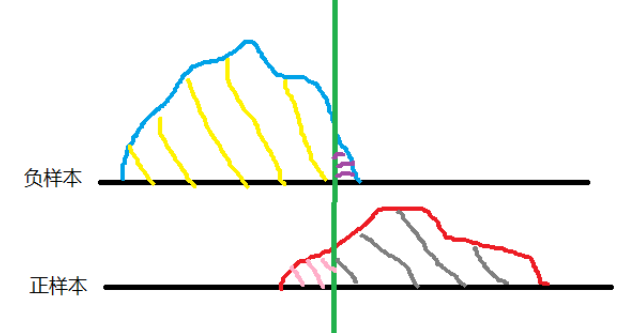
根据以上公式,我们的目标
TPR = 灰色/整个正样本 TPR越大越好
FPR = 紫色/整个负样本 。 FPR越小越好
但是看图也知道,要想让紫色面积越小,那灰色占比也会变小,所以阈值的设定比较纠结
现在我们指定一个阈值为0.9,那么只有第一个样本(0.9)会被归类为正例,而其他所有样本都会被归为负例,因此,对于0.9这个阈值,我们可以计算出FPR为0,TPR为0.1(因为总共10个正样本,预测正确的个数为1),那么我们就知道曲线上必有一个点为(0, 0.1)。依次选择不同的阈值(或称为“截断点”),画出全部的关键点以后,再连接关键点即可最终得到ROC曲线如下图所示。
2.代码实现
省略了数据处理相关代码,核心代码就是调用roc_curve()函数,传入测试集的label和模型给出的概率值
probabilities = model.predict_proba(test[["gpa"]])
fpr, tpr, thresholds = metrics.roc_curve(test["actual_label"], probabilities[:,1])
plt.plot(fpr, tpr)
plt.show()3.为什么不用PRC
因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。
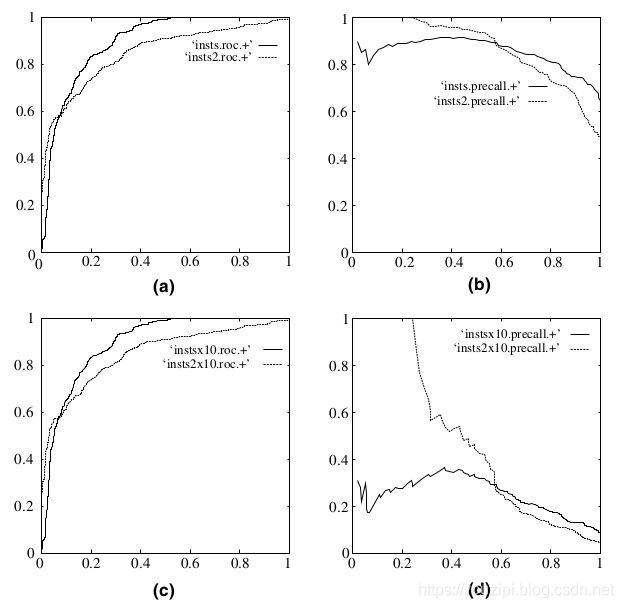
为什么不变呢?TPR和FPR是实际label内部的操作,看混淆矩阵和tpr、fpr计算公式,无论实际label比例怎么变化,tpr、fpr计算公式都是在实际为p或者n的内部计算的。
参考文章: