Python 绘制ROC曲线的例子
ROC的全称是“受试者工作特征”(Receiver Operating Characteristic)曲线。
根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出两个重要量的值(TPR、FPR),分别以它们为横、纵坐标作图。与PR曲线使用查准率、查全率为纵、横不同,ROC 曲线的纵轴是“真正例率”(True Positive Rate,TTR),横轴是“假正例率”(False Positive Rate,FPR)。
如图所示:
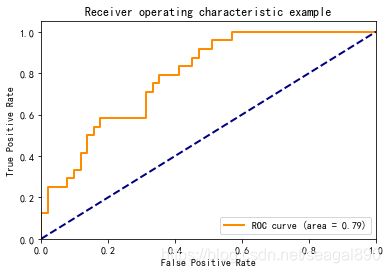
下面使用Python来作出该图:
# -*- coding: utf-8 -*-
"""
Created on Tue Mar 24 19:04:21 2020
@author: Bean029
"""
import numpy as np
import matplotlib.pyplot as plt
from itertools import cycle
from sklearn import svm, datasets
from sklearn.metrics import roc_curve, auc
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
from scipy import interp
from sklearn.metrics import roc_auc_score
# Import some data to play with
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Binarize the output
y = label_binarize(y, classes=[0, 1, 2])
n_classes = y.shape[1]
# Add noisy features to make the problem harder
random_state = np.random.RandomState(0)
n_samples, n_features = X.shape
X = np.c_[X, random_state.randn(n_samples, 200 * n_features)]
# shuffle and split training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.5,
random_state=0)
# Learn to predict each class against the other
classifier = OneVsRestClassifier(svm.SVC(kernel='linear', probability=True,
random_state=random_state))
y_score = classifier.fit(X_train, y_train).decision_function(X_test)
# Compute ROC curve and ROC area for each class
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# Compute micro-average ROC curve and ROC area
fpr["micro"], tpr["micro"], _ = roc_curve(y_test.ravel(), y_score.ravel())
roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
plt.figure()
lw = 2
plt.plot(fpr[2], tpr[2], color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % roc_auc[2])
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()
ROC曲线与PR曲线的取舍
相对来讲ROC曲线会稳定很多,在正负样本量都足够的情况下,ROC曲线足够反映模型的判断能力。因此,对于同一模型,PRC和ROC曲线都可以说明一定的问题,而且二者有一定的相关性,如果想评测模型效果,也可以把两条曲线都画出来综合评价。对于有监督的二分类问题,在正负样本都足够的情况下,可以直接用ROC曲线、AUC、KS评价模型效果。在确定阈值过程中,可以根据Precision、Recall或者F1来评价模型的分类效果。对于多分类问题,可以对每一类分别计算Precision、Recall和F1,综合作为模型评价指标。
ROC曲线下的面积,介于0.1和1之间,作为数值可以直观的评价分类器的好坏,值越大越好。
ROC曲线的特征是Y轴上的真阳性率和X轴上的假阳性率。
这意味着图的左上角是“理想”点——假阳性率为0,真阳性率为1。这不是很现实,但它确实意味着曲线下较大的面积(AUC)通常更好。
ROC曲线的“陡峭度”也很重要,因为最大化真阳性率同时最小化假阳性率是理想的。
ROC曲线通常用于二值分类以研究分类器的输出。为了将ROC曲线和ROC区域扩展到多标签分类中,需要对输出进行二值化。每个标签可以绘制一条ROC曲线,但也可以通过将标签指示符矩阵的每个元素视为二进制预测(微观平均)来绘制ROC曲线。
