机器学习中最重要的三个部分为网络结构、损失函数、优化策略。
而其中以损失函数最难以理解,主要原因是需要较强的数学知识,其中用的最多的就是参数估计。
所谓参数估计就是:对未知参数θ进行估计时,在参数可能的取值范围内选取,使“样本获得此观测值”的概率最大的参数
作为θ的估计,这样选定的
有利于
”的出现。
在机器学习指的就是,在已知数据集(结果)和模型(分布函数)的情况下,估计出最适合该模型的参数。
logistic回归的代价函数形式如下:
该代价函数就是通过--最大似然估计 出来的
最大似然估计
定义:最大似然估计(Maximum likelihood estimation)就是指,在已知样本结果的情况下,推断出最有可能使得该结果出现的参数的过程。也就是说最大似然估计一个过程,它用来估计出某个模型的参数,而这些参数能使得已知样本的结果最可能发生。
最大似然估计的重要前提:训练样本的分布能代表样本的真实分布。每个样本集中的样本都是所谓独立同分布的随机变量 (iid条件),且有充分的训练样本。
最大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为最大似然估计。
数学定义:


求解步骤:

举例:

Logistic回归代价函数的推导:



神经网络代价函数--详解
Logistic逻辑回归的代价函数
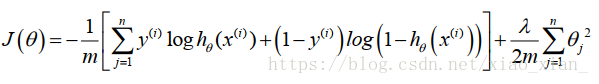
以逻辑回归为基础的神经网络的代价函数
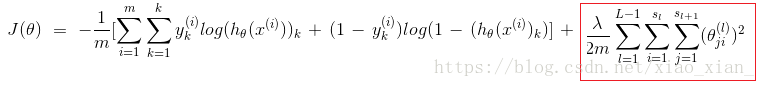
k:输出单元个数即classes个数,L:神经网络总层数,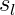
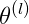
逐步分解解析:
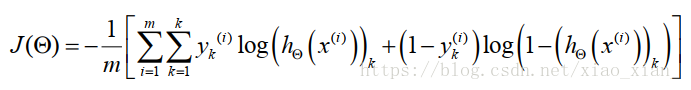
这一部分相比原来的公式,增加了一个关于K的累加。这里的 K 代表着分类的数量,对应着输出层输出结果的数量4。
这里的下标 k ,就是计算第 k 个分类的意思。
也就是说,我们需要求得的参数, 应该对每一个分类计算代价函数,并使得加总之后的结果最小。
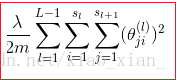
这部分是正则化项 称为正则化系数,
表示每层神经元的个数
是对每一个 θ 的平方进行累计。三个累加的含义。
最里层的循环j循环所有的行(由层的激活单元数决定);对某一层的每一行进行加总:
循环i则循环所有的列,由该层(层)的激活单元所决定;对某一层的每一列进行加总:
对每一层进行加总:
正则化:
————改善或减少过拟合问题(保留所有特征,但减少参数的大小)
正则化基本方法:在一定程度上减少高次项的系数,使之接近于0。
修改代价函数,即给高次项设置一些惩罚。
如果不知道哪些特征需要惩罚,将对所有的特征进行惩罚 。(不对进行惩罚)
正则化系数不宜太大,太大会使 造成欠拟合的现象
最大似然函数的博文来自:https://blog.csdn.net/The_lastest/article/details/78759837
损失函数原博文:https://blog.csdn.net/The_lastest/article/details/78761577
神经网络的代价函数博文参考:https://blog.csdn.net/The_lastest/article/details/77979624