此处开始谈论一个学习算法,它能在给定训练集时,为神经网络拟合参数。
和我们讨论的大多数学习算法一样,我们将从拟合神经网络参数的代价函数开始讲起。
重点讲解神经网络在分类问题中的应用。
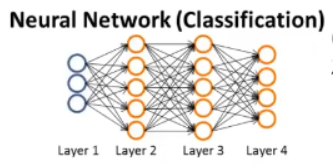
假设我们有一个与上图类似的神经网络结构:
再假设我们有一个像这样的训练集:

其中有m组训练样本(x ^(i), y ^(i))。
用大写字母L来表示这个神经网络结构的总层数。(对于上图的网络结构,能够得出L = 4。)
接着用s_l来表示第l层的单元数,也就是神经元的数量,这其中不包括第L层的偏差单元。
我们将会考虑两种分类问题:
- 第一种是二元分类:

上面那个神经网络有四个输出单元,如果遇到二元分类问题的话,就会只有一个输出单元,也就是计算出来的h(x),同时神经网络的输出结果h(x)会是一个实数。
在这种情况下,若l代表最后一层的序号,则s_l是输出单元的个数,因为l是网络结构中的层数,所以我们在输出层中的单元项目就将是1。
在这类问题里,为了简化记法,把K(输出单元的维度)设为1,这样可以把K也当做输出层的单元数目。
- 第二种是多类别分类问题:
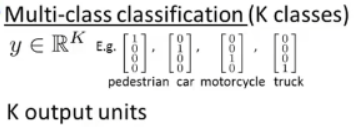
(也就是说会有K个不同的类。)
之前的例子中,如果有四类的话,就有这种表达方式来表示y:
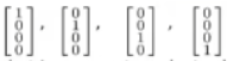
这类问题中,会有K个输出单元,我们的假设h_θ(x)会输出K维向量,同时输出单元的个数会等于K。
通常情况下,这类问题里K是大于或等于3的,因为如果只有两个类别,就不需要使用这种一对多的方法,只需要一个输出单元就可以了。
现在来为我们的神经网络定义代价函数:
先来看一下逻辑回归中使用的代价函数:
我们在神经网络里使用的代价函数是逻辑回归中使用的代价函数的一般形式。
对于逻辑回归而言,通常使代价函数J(θ)最小化。
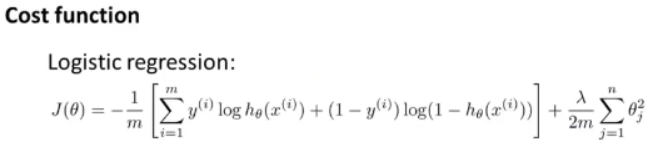
对于一个神经网络来说,我们的代价函数就会是上面那个式子的一般形式,这里不再仅有一个逻辑回归输出单元,取而代之的是K个。
所以这就是我们的代价函数:
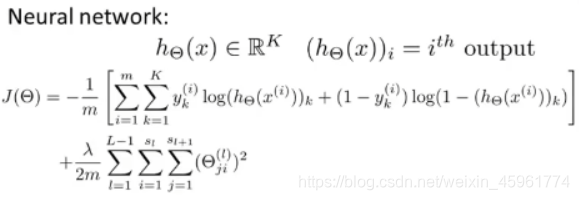
神经网络现在输出了属于R^K的向量。
(如果我们处理的是二元分类问题,这里的K可能为1。)

表示第i个输出,也就是说h_θ(x)是一个K维向量,下标i表示选择输出神经网络输出向量中的第i个元素。
代价函数J(θ)现在是这样:
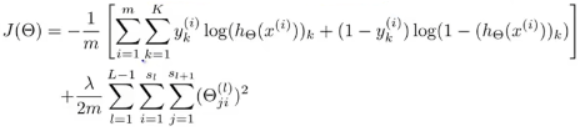
除了在这里求的从1到K的所有和,这个求和项主要是K个输出单元之和。
所以如果神经网络最后一层有四个输出单元,那么这个求和项就为求K等于从1到4的每一个逻辑回归算法的代价函数,然后按四次输出的顺序,依次把这些代价函数加起来。
所以要特别注意到这个求和符号应用于y_K和h_K,因为我们主要是将第K个输出单元的值和y_K的值的大小作比较。y_K的值就是这些向量中表示其应属于哪个类的量。
最后,这里的第二项
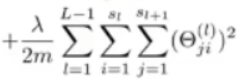
就是类似于在逻辑回归里所用的正则化项。
这个求和项看起来十分复杂,并且它总是对(θ_(ji))^l项、对所有的i j l的值求和。
正如在逻辑回归里一样,这些要除去那些对应于偏差项的值,我们不对它们进行求和。
具体而言,我们不对那些(θ_(ji))^l中i为0的项进行求和,这是因为当我们计算神经元的激励值时,我们会有像这样的项:

如果这是第一个隐含层,那么这些含有0的项就对应是乘上了某个x_0或是a_0的项。因此,这就是个有些类似于偏差单元的项:
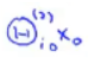
类比于在处理逻辑回归时所做的那样,我们就不会将这些项加到正则项中,因为我们并不想正则化这些项,并把这些项设定为0,但这只是一个合理的约定,即使真的将它们加进去了,也就是i从0加到s_L,这依然是有效的,并且不会有大的区别,不过可能这个不将偏差项正则化的规定会更常用一些。
这就是我们准备应用于神经网络结构的代价函数。
参考资料:吴恩达机器学习系列课程
