1. 原理

通俗理解:将真实标签减去一个很小的数,然后平均分配到其他类上,实现了标签软化。
2. 作用
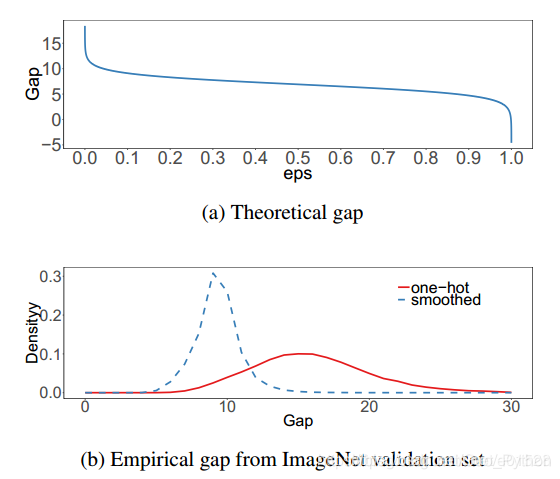
(a图):当增加ε时,目标类别与其它类别之间的理论差距减小。(b图):最大预测与其它类别平均值之间差距的经验分布。很明显,通过标签平滑,分布中心处于理论值并具有较少的极端值。
3. 代码实现
import torch
import torch.nn as nn
class LSR(nn.Module):
def __init__(self, e=0.1, reduction='mean'):
super().__init__()
self.log_softmax = nn.LogSoftmax(dim=1)
self.e = e
self.reduction = reduction
def _one_hot(self, labels, classes, value=1):
"""
Convert labels to one hot vectors
Args:
labels: torch tensor in format [label1, label2, label3, ...]
classes: int, number of classes
value: label value in one hot vector, default to 1
Returns:
return one hot format labels in shape [batchsize, classes]
"""
one_hot = torch.zeros(labels.size(0), classes)
#labels and value_added size must match
labels = labels.view(labels.size(0), -1)
value_added = torch.Tensor(labels.size(0), 1).fill_(value)
value_added = value_added.to(labels.device)
one_hot = one_hot.to(labels.device)
one_hot.scatter_add_(1, labels, value_added)
return one_hot
def _smooth_label(self, target, length, smooth_factor):
"""convert targets to one-hot format, and smooth
them.
Args:
target: target in form with [label1, label2, label_batchsize]
length: length of one-hot format(number of classes)
smooth_factor: smooth factor for label smooth
Returns:
smoothed labels in one hot format
"""
one_hot = self._one_hot(target, length, value=1 - smooth_factor)
one_hot += smooth_factor / length
return one_hot.to(target.device)
def forward(self, x, target):
if x.size(0) != target.size(0):
raise ValueError('Expected input batchsize ({}) to match target batch_size({})'
.format(x.size(0), target.size(0)))
if x.dim() < 2:
raise ValueError('Expected input tensor to have least 2 dimensions(got {})'
.format(x.size(0)))
if x.dim() != 2:
raise ValueError('Only 2 dimension tensor are implemented, (got {})'
.format(x.size()))
smoothed_target = self._smooth_label(target, x.size(1), self.e)
x = self.log_softmax(x)
loss = torch.sum(- x * smoothed_target, dim=1)
if self.reduction == 'none':
return loss
elif self.reduction == 'sum':
return torch.sum(loss)
elif self.reduction == 'mean':
return torch.mean(loss)
else:
raise ValueError('unrecognized option, expect reduction to be one of none, mean, sum')
4. 用法
from LabelSmoothing import LSR
# 标签平滑,LSR可看做一种损失函数
#criterion = nn.CrossEntropyLoss()
criterion = LSR()
# LSR()与 nn.CrossEntropyLoss()在用法上完全相同博主亲试有效(略有提升),拿去用吧。
相关: