1. 数据处理
请参考PCA的数学原理,PCA利用数据之间的相关性,通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降维。
2. 权重处理:神经网络权重初始化问题,Xavier初始化方法


3.权重处理:批标准化

关于BN的作用,总体来说,可以提升网络的速度性能和稳定性。至于为什么产生这样的效果,目的实际目前还没有定论,提出的时候是解决一个叫internal covariate shift的问题,直观上还有些其他好处。
对于上述公式的第四步:前面加了个normalization之后,很可能不是最优。再弄个线性映射,参数都是可学的。

4、防止过拟合:L1正则化与L2正则化
(1)防止过拟合的原因
结构风险最小化: 在经验风险最小化的基础上(也就是训练误差最小化),尽可能采用简单的模型,以此提高泛化预测精度。加上L1和L2正则化项可以增大惩罚项,使模型更简单。
(2)以同一条原曲线目标等高线来说,现在以最外圈的红色等高线为例,我们看到,对于红色曲线上的每个点都可以做一个菱形,根据上图可知,当这个菱形与某条等高线相切(仅有一个交点)的时候,这个菱形最小,上图相割对比较大的两个菱形对应的1范数更大。所以找相切的点。
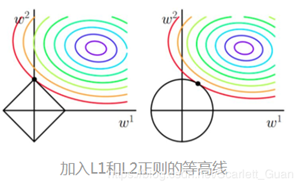
几乎对于很多原函数等高曲线,和某个菱形相交的时候极其容易相交在坐标轴(比如上图),也就是说最终的结果,解的某些维度极其容易是0,数学可证明,这也就是我们所说的L1更容易得到稀疏解(解向量中0比较多)的原因。L2范数的从图上来看,不容易交在坐标轴上,但是仍然比较靠近坐标轴。因此这也就是我们老说的,L2范数能让解比较小(靠近0),但是比较平滑(不等于0)。
(3)L2 针对于这种变动, 白点的移动不会太大, 而 L1的白点则可能跳到许多不同的地方 , 因为这些地方的总误差都是差不多的. 所以L1相比于L2不稳定。如下图所示:

5、防止过拟合:dropout为啥能防止过拟合?
- 取平均,各种过拟合相互抵消,相当于多个模型的组合
- 减少特征之间的依赖性,增加鲁棒性,泛化能力

注意: 经过上面屏蔽掉某些神经元,使其激活值为0以后,我们还需要对向量y1……y1000进行缩放,也就是乘以1/(1-p)。
p的概率屏蔽神经元,那平均就是留下了比例为1-p的神经元,那要保证输出的数值差不多,就除以1-p。
dropout率一般选0.5,为了保证随机生成的网络结构的多样性。就是比如p特别小,那很多网络结构出现的概率就很低,p特别大也是。实际中也不见得非是0.5,具体衡量得用网络结构的分布的熵吧,具体得试,不想试就还是0.5。
