散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存储存位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。 (来自维基百科)
其中前边说到的离散化也是一种特殊的哈希方式,只不过离散化注重保序性,因此使用二分查找的方法。
其中存在问题就是:可能会把不同的数映射成相同的数,这就是哈希冲突,则我们处理冲突的方法就是将一组关键字映射到一个有限的连续的地址集(区间)上,到时候我们查找的时候就可以顺着这个地址依次查找。
而处理冲突的两种方法:拉链法和开放寻址法
拉链法:
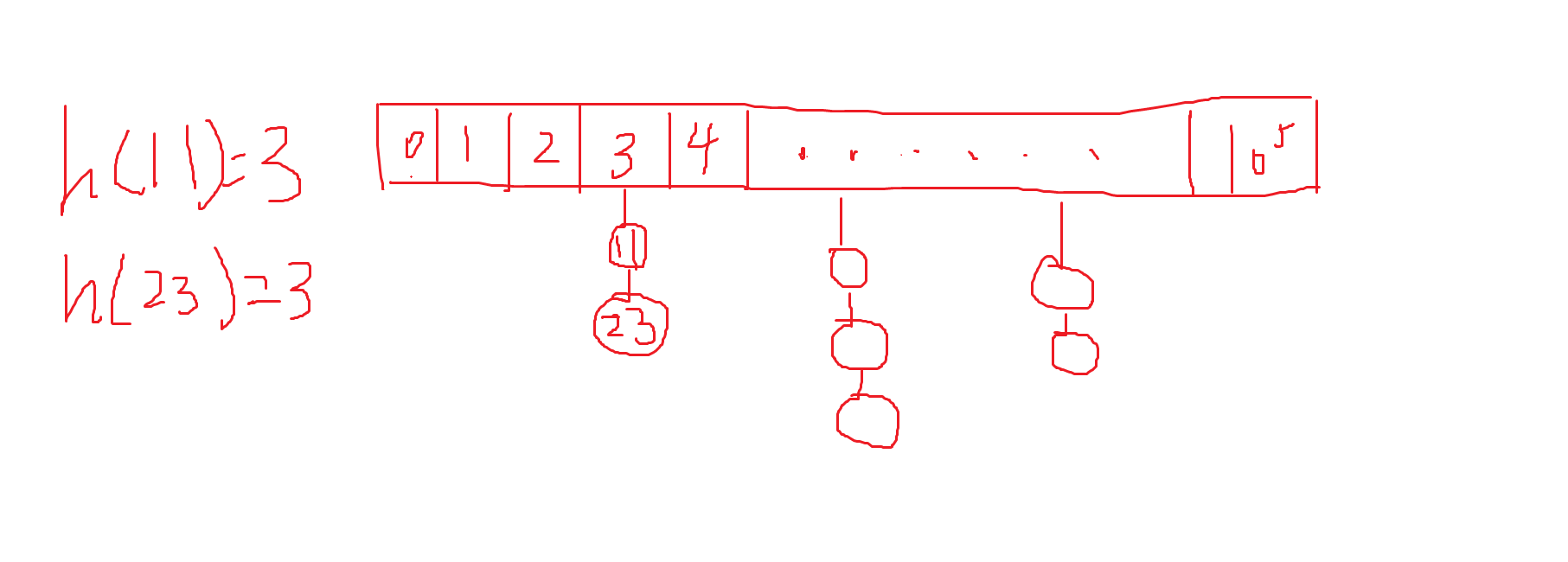 这种方法就是把映射值相同的点像链表一样挂在同一个地址上,当我们寻找的时候就可以通过地址来直接索引。
这种方法就是把映射值相同的点像链表一样挂在同一个地址上,当我们寻找的时候就可以通过地址来直接索引。
而寻找这个地址或者说映射的方法就是取模(mod),而mod的数最好就是大于映射范围的第一个质数,这样会更大的减少冲突(数学推理不清楚,听大佬说的)。
取模的方法: k = (x % N + N) %N (N是映射后的范围,这样取模是为了防止负数)
开放寻址法
这种方法只需要开一个数组,不过这个数组的大小最好是映射后范围的2~3倍,那是因为这种方法再寻找映射后结果如果被占用则它顺着这个结果继续向下找直到找到空位。
说的形象一点就好比上厕所:这个坑位有人,咱就必须取下一个坑位,直到找到一个空的坑位。

以一个题目作为例子
模拟散列表
1 #include <iostream> 2 #include <cstring> 3 4 using namespace std; 5 6 const int N = 100003; //寻找一个大于映射范围的第一个质数 最好用质数取模 7 int e[N], ne[N], idx, h[N]; 8 9 void insert(int x) 10 { 11 int k = (x % N + N) % N; 12 e[idx] = x; 13 ne[idx] = h[k]; 14 h[k] = idx; 15 idx++; 16 } 17 18 bool query(int x) 19 { 20 int k = (x % N + N) %N; 21 for(int i = h[k]; i != -1; i = ne[i]) 22 { 23 if(e[i] == x) 24 { 25 return true; 26 } 27 } 28 29 return false; 30 } 31 32 int main() 33 { 34 int n; 35 scanf("%d", &n); 36 37 memset(h, -1, sizeof(h)); 38 39 while(n--) 40 { 41 int x; 42 char op[2]; 43 scanf("%s%d", op, &x); 44 if(*op == 'I') insert(x); 45 else 46 { 47 if(query(x)) printf("Yes\n"); 48 else printf("No\n"); 49 } 50 } 51 52 system("pause"); 53 return 0; 54 }
开放寻址法Code:
1 #include <iostream> 2 #include <cstring> 3 4 using namespace std; 5 6 const int N = 200003, null = 0x3f3f3f3f; //数组开到个数上限的2~3倍, null表示为空 未被占用 7 int h[N]; 8 9 int finds(int x) //两个作用:1.寻找可以插入的位置 2.寻找哈希表中是否存在要查找的数字 10 { 11 int t = (x % N + N) % N; 12 while(h[t] != null && h[t] != x) 13 { 14 t++; 15 if(t == N) t = 0; //如果找到尾则从头寻找 16 } 17 18 return t; 19 } 20 21 int main() 22 { 23 memset(h, 0x3f, sizeof(h)); //寻找一个标志 这个标志大于x的范围 24 25 int n; 26 scanf("%d", &n); 27 28 while(n--) 29 { 30 char op[2]; 31 int x; 32 33 scanf("%s%d", op, &x); 34 if(*op == 'I') h[finds(x)] = x; 35 else 36 { 37 if(h[finds(x)] != null) puts("Yes"); 38 else puts("No"); 39 } 40 } 41 42 system("pause"); 43 return 0; 44 }
字符串哈希
字符串哈希就是把一个字符串哈希为整数,具体方法就是把一个字符串具体看成一个P进制数(P不确定),然后我们把他换算成十进制数字,这样就可以直接通过数字来判断两个字符串是否相等。(相当厉害并且好用的一种方法)。
题目描述
思路:直接把每个字符串的哈希值存入一个数组,然后对数组排序后进行判断即可。
进制P,一般取为131,1331..(同样有数学证明)。
字符串换算为10进制范围会很大,所以我们使用 unsigned long long ,溢出会自动对2^64取模。
代码:
1 #include <iostream> 2 #include <algorithm> 3 #include <cstring> 4 #include <cstdio> 5 6 using namespace std; 7 8 typedef unsigned long long ULL; 9 10 const int N = 10010, P = 131; 11 char str[N]; 12 ULL a[N]; 13 14 ULL hashGet(char str[]) 15 { 16 int len = strlen(str); 17 ULL res = 0; 18 for(int i = 0; i < len; i++) //将P进制换算为10进制 19 { 20 res = res*P + str[i]; 21 } 22 23 return res; 24 } 25 26 int main() 27 { 28 int n, res = 1; 29 30 scanf("%d", &n); 31 for(int i = 0; i < n; i++) 32 { 33 scanf("%s", str); 34 a[i] = hashGet(str); 35 } 36 37 sort(a, a+n); 38 39 for(int i = 1; i < n; i++) 40 { 41 if(a[i] != a[i-1]) res++; 42 } 43 44 printf("%d\n", res); 45 46 return 0; 47 }
明天再写字符串前缀哈希。。。