在了解哈希表之前我们先来看一下什么是Direct-Address tables?
假设我们的一个应用需要存储 键值对并且能支持操作 增删改查那么我们首先最原始的方法就是使用 Direct-address table. 我们在 T 中通过对键的查找直接找到相对应的数据。
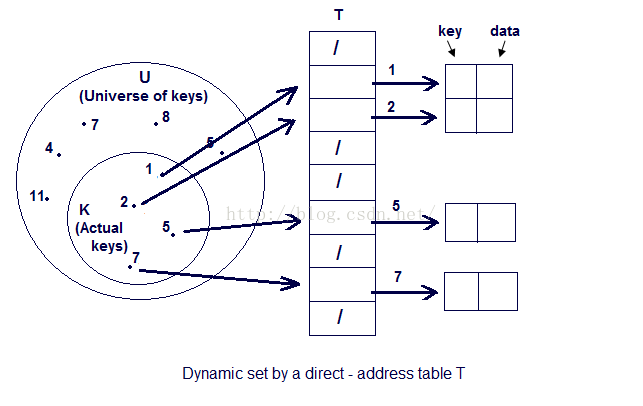
这种方法看似很好,但是有很大的局限性。 首先我们需要确定Universe of keys (U), 所以当U集合很大时, 会造成效率低下等问题。这时候一种更好的方法 Hash table 应运而生。
Hash table 就是一种将key通过 hash 函数进行计算之后,存储到key的hash code相对应的bucket中。值得注意的是bucket中存储的不仅仅是 value(值) 同时也存储 key (键)!!!如下图
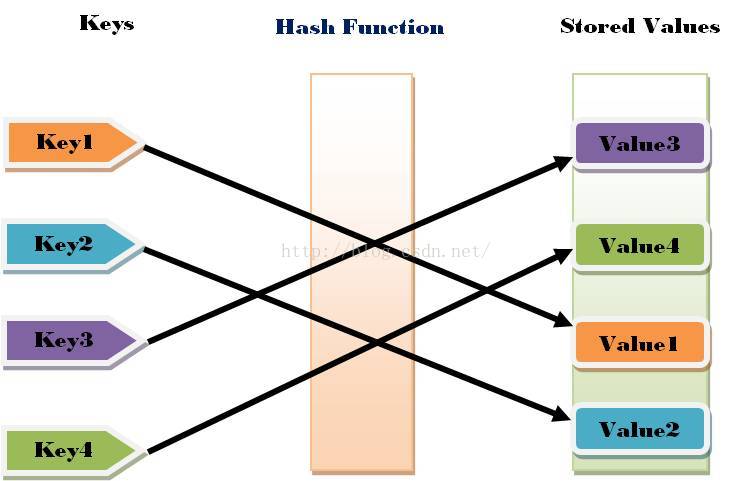
这样做会有什么问题?
当对不同的key进行hash的时候,可能造成一种错误,collision (碰撞) - 不同的键在hash之后变成相同的hash code.
如何避免碰撞?
有两种方法.
1. Chaining
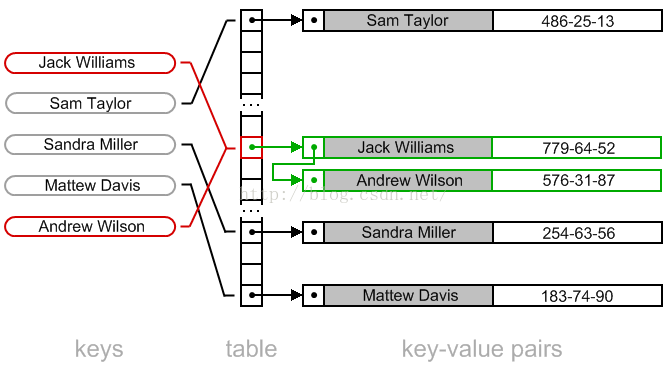
在hash table中, 我们采用一个额外的链表对 key-value进行存储( 上文中提到了bucket中存储的不仅仅是value还有key), 从下图可以看出,当Jack 和 Andrew 同时被分配到了同一个bucket 中时候,可以再继续对bucket中的链表进行遍历,找到key对应的是value就可以。 hash table中存储的是链表的表头
2. Open Addressing
与chaining采用而外的链表来存储key-value不同的是,open addressing直接将所有的key-value存储到bucket中,过程是这样的: 对 Jack Williams进行hash然后再bucket中找到相对应的位置,并且该位置为空,那么我们就把key-value存储下来, Sam Taylor, Sandra Miller Mattew Davis 都是这样,但是现在来了Andrew Wilson,它的hash code和Jack Williams 是一样的, 那么我们就在离它原本最近的bucket中找到一个空的位置赋值给他。 当查询Andrew时,我们首先查询到的是Jack, 发现andrew不在这,那我们就进行向下走直到找到Andrew. hash table中存储的是实际的key-value

有问题欢迎指出!