1、快速排序算法
快速排序(Quick Sort)的基本思想是:通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序的目的。
基本实现思路:快速排序算法每一趟排序都需要一个基准数,一般以待排序的序列最左边的第一个数值为基准数,然后设置两个哨兵在待排序的序列的两端,左哨兵往右寻找比基准数大的数值,右哨兵往左寻找比基准数小的数值,各找到一个后就交换,一直到左哨兵和右哨兵为止,左哨兵和右哨兵相遇的位置就基准数该在的位置,交换基准数和左哨兵,然后递归排序基准数左半部分的序列,递归排序基准数右半部分的序列。
/*快速排序递归算法*/
void Quick_Sort(int *arr, int left,int right)
{
if (left >= right) return; /*左与右相遇,说明已经排序完成,返回*/
int pivot = partition(arr, left, right); /*排序后,得到枢轴的位置*/
Quick_Sort(arr, left, pivot-1); /*以枢轴划分,递归排序左半部分*/
Quick_Sort(arr, pivot+1, right); /*以枢轴划分,递归排序右半部分*/
}
/*一趟排序后,返回枢轴的位置*/
int partition(int *arr, int left,int right)
{ /*一般以序列最左边的第一个数为基准数*/
int pivot = left; /*枢轴记录基准数的位置*/
while (left < right) /*直到左、右哨兵相遇,完成排序*/
{
/*右哨兵先左移,直到找到小于基准数的,或遇到左哨兵时停下*/
while (left < right && arr[right] >= arr[pivot])
right--;
/*然后左哨兵右移,直到找到大于基准数的,或遇到右哨兵时停下*/
while (left < right && arr[left] <= arr[pivot])
left++;
/*此时右哨兵指向小于基准数的,左哨兵指向大于基准数的,交换它们*/
swap_arr(arr, left, right);
}
/*左、右哨兵相遇的位置就是枢轴的位置*/
swap_arr(arr, pivot, right);
pivot = right;
return pivot;
}现在我们对arr[11] = {0, 6, 1, 2, 7, 9, 3, 4, 5, 10, 8}进行排序,基准数为arr[1]=6,左哨兵i 和右哨兵j 分别指向序列的两端。
首先右哨兵j 先向左边移动,一直找到一个比基准数小的时候停下,8->10->5,找到5,右哨兵j 停下。
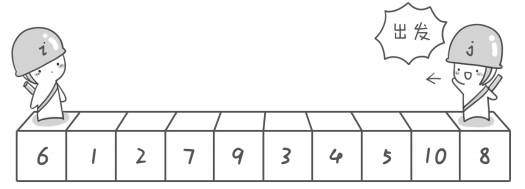
接着左哨兵i 向右边移动,一直找到一个比基准数大的时候停下,6->1->2->7,找到7,左哨兵i 停下。此时左哨兵i 和右哨兵j 都找到一个目标,就将它们进行交换。

交换后,轮到右哨兵j 继续左移,左移一位找到4,右哨兵j 停下。接着左哨兵i 继续右移,右移一位找到9,左哨兵i 停下。此时左哨兵i 和右哨兵j 都找到一个目标,就将它们进行交换。

交换后,轮到右哨兵j 继续左移,左移一位找到3,右哨兵j 停下。接着左哨兵i 右移一位,遇到了右哨兵j,此时这一趟排序结束,将基准数arr[1]=6,交换到左哨兵i 和右哨兵j 相遇的位置。
此时我们可以发现,基准数左边都是比基准数小的,基准数右边都是比基准数大的。

不再仔细讲解,给出一个完整的排序流程图:

2、快速排序的时间复杂度分析
快速排序的时间性能取决于快速排序递归的深度,可以用递归树来描述递归算法的执行情况。
在最优的情况下,递归树是一颗完全二叉树,那么树的深度为㏒n+1,有n个待排序的数据,那么快速排序的时间复杂度为O(n㏒n)。
在最坏的情况下,待排序序列为正序或者逆序,那么递归树就是一个斜树,树的深度为n,有n个待排序的数据,那么快速排序的时间复杂度为O(n²)。
3、优化快速排序算法
3.1、优化基准数的选择
如果我们每次选择的基准数都是待排序序列的中间数,那么我们就可以将待排序序列平均分为两个部分,递归树就为完全二叉树,最优效率。
但注意,“如果基准数是中间数”,那么说明每次基准数不一定会取到中间数,如果每次基准数每次都取到最大值或最小值,那么递归树就为斜树,效率极低。
如此,将基准数取为待排序序列最左边第一个数,成为了一个潜在的性能瓶颈,总是固定选取一个位置为基准数变成了极不合理的做法。
针对这个缺陷,进行改进,于是就有了三数取中法:选择三个数进行排序,选择中间数为基准数。这三个数可以是最左端、中间、最右端的三个数,也可以随机选择。
通过三数取中法选择基准数,保证了基准数一定不会是最大值或最小值,从概率来说,这个基准数大概率为较为中间的数。
对于小序列来说,三数取中法已经有很大概率选到比较中间的数,但是对于大序列来说,还无法保证,因此将三数取中法增大为九数取中法:先从序列分三次取样,每次取三个数,三个样本各取出一个中间数,再从三个中间数取一个中间数为基准数。这样基准数取为中间数的概率就更加大了。
/*三数取中法*/
int Middle_Of_Three_Nnumbers(int *arr, int low, int high)
{
/*中间值放在low*/
int mid = low + (high - low) / 2;
if (arr[low] > arr[high]) /*先将最左端和最右端排序,得出low < high*/
swap_arr(arr, low, high); /*此时low存放较小值*/
/*mid此时有三种情况:low ? mid ? high*/
if (arr[mid] > arr[high]) { /*如果是low < high < mid,说明 high就是中间值*/
swap_arr(arr, low, high); /*将high放到low*/
return low;
}
/*mid此时有两种情况:low ? mid < high*/
if (arr[mid] > arr[low]) { /*如果是low < mid < high,说明 mid就是中间值*/
swap_arr(arr, low, mid); /*将mid放到low*/
return low;
}
/*不然此时就是mid < low < high,说明 low就是中间值*/
return low;
}3.2、优化小数组的排序方案
对于一个数学科学家、博士生导师,他可以攻克世界性的难题,可以培养最优秀的数学博士,但让他去教小学生 1+1=2 的算术课程,未必会比常年在小学里耕耘的数数学老师教得好。
换句话说,大材小用有时会变得反而不好用。如果数组非常小,其实快速排序反而不如直接插入排序来得更好(直接插入是简单排序中性能最好的)。其原因在于快速排序用到了递归操作,在大量数据排序时,这点性能影响相对于它的整体算法优势是可以忽略的,但如果数组只有几个、几十个记录需要排序时,这就成了一个大炮打蚊子的问题。
因此当数组小于一定长度时,就使用直接插入排序,这样就能保证最大化的利用两种排序的优势。
3.3、优化递归操作
递归对性能是有一定影响的,栈的大小是很有限的,每次递归调用都会耗费一定的栈空间,如果能减少递归,将会提升一定的性能。
将 if 改成 while ,递归右半部分改成 left=pivot+1,再循环一次就会执行 Partition(arr, left=pivot+1, right),效果与 Quick_Sort(arr, pivot+1, right) 一样。
/*快速排序递归算法*/
void Quick_Sort(int *arr, int left,int right)
{
while (left < right)
{
int pivot = Partition(arr, left, right); /*排序后,得到枢轴的位置*/
Quick_Sort(arr, left, pivot-1); /*以枢轴划分,递归排序左半部分*/
left = pivot+1;
}
}虽然两种方法结果相同,但因为使用迭代替换递归,缩减了栈深度,从而提高了整体的性能。