简介
Labelme是麻省理工(MIT)的计算机科学和人工智能实验室(CSAIL)研发的图像标注工具,使用它可以进行语义分割和实例分割的图像标注
安装
安装推荐使用Anaconda数据科学工具进行安装,在Windows下面的安装如下
第一步
打开Anaconda的Anaconda Prompt(Windows里面可以在开始菜单里面找到),键入命令如下
conda create --name=labelme python=3.6// 一行一行执行,(修改成你的python版本)
source activate labelme
conda install pyqt
pip install labelme // 也可以指定你要安装的版本,比如这样:pip install labelme==2.0.1
等待安装,(如果安装速度慢,可以调成国内pip源,建议自行百度)
使用
打开Anaconda的Anaconda Prompt,键入下面,进入虚拟环境
activate labelme
打开软件键入下面:
labelme
软件打开以后,就可以使用它进行图像的标注,标注完成以后,保存json文件。
数据集的生成
- 打开cmd,键入
activate labelme,进入labelme虚拟环境下面。 - 进入你已经生成的json文件路径下面,比如进入d盘的\jianan\example文件下。
d:
cd jianan\example // windows下面为\
键入:
labelme_json_to_dataset <文件名>.json
然后会生成如上图的五个文件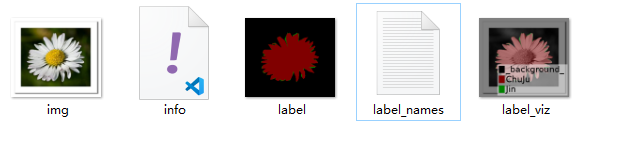
如果你生成的是四个文件,没有info文件的话,应该是你的labelme的版本太高了
解决方法如下:
进入到你的anaconda安装路径下面,比如:d:\anaconda\envs\labelme\Lib\site-packages\labelme\cli 里面
你可以看到有一个json_to_dataset.py文件
将里面的代码全部注释掉,然后替换成下面的代码就可以了
import argparse
import base64
import json
import os
import os.path as osp
import warnings
import imgviz
import PIL.Image
import yaml
from labelme.logger import logger
from labelme import utils
def main():
logger.warning('This script is aimed to demonstrate how to convert the'
'JSON file to a single image dataset, and not to handle'
'multiple JSON files to generate a real-use dataset.')
parser = argparse.ArgumentParser()
parser.add_argument('json_file')
parser.add_argument('-o', '--out', default=None)
args = parser.parse_args()
json_file = args.json_file
if args.out is None:
out_dir = osp.basename(json_file).replace('.', '_')
out_dir = osp.join(osp.dirname(json_file), out_dir)
else:
out_dir = args.out
if not osp.exists(out_dir):
os.mkdir(out_dir)
data = json.load(open(json_file))
imageData = data.get('imageData')
if not imageData:
imagePath = os.path.join(os.path.dirname(json_file), data['imagePath'])
with open(imagePath, 'rb') as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8')
img = utils.img_b64_to_arr(imageData)
label_name_to_value = {
'_background_': 0}
for shape in sorted(data['shapes'], key=lambda x: x['label']):
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
lbl, _ = utils.shapes_to_label(
img.shape, data['shapes'], label_name_to_value
)
label_names = [None] * (max(label_name_to_value.values()) + 1)
for name, value in label_name_to_value.items():
label_names[value] = name
lbl_viz = imgviz.label2rgb(
label=lbl, img=imgviz.asgray(img), label_names=label_names, loc='rb'
)
PIL.Image.fromarray(img).save(osp.join(out_dir, 'img.png'))
utils.lblsave(osp.join(out_dir, 'label.png'), lbl)
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, 'label_viz.png'))
with open(osp.join(out_dir, 'label_names.txt'), 'w') as f:
for lbl_name in label_names:
f.write(lbl_name + '\n')
warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=label_names)
with open(osp.join(out_dir, 'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
logger.info('Saved to: {}'.format(out_dir))
if __name__ == '__main__':
main()