采用的软件为labelme,labelme是麻省理工(MIT)的计算机科学和人工智能实验室(CSAIL)研发的图像标注工具,人们可以使用该工具创建定制化标注任务或执行图像标注,主要用于标记语义分割数据集。下面介绍详细的使用方法:
第一步:下载并安装anaconda,下载地址为:
https://repo.anaconda.com/archive/Anaconda2-2018.12-Windows-x86_64.exe
第二步:打开anaconda的主界面,Anaconda Navigator,如图7所示,

图7 anaconda主要功能
第三步:anaconda主界面如图8所示,点击environment进入虚拟环境创建界面

图8 anaconda主界面
第四步:点击左下角Create创建虚拟环境

图9 anaconda创建虚拟环境界面
第五步:创建虚拟环境,如图10所示,Name为labelme。一定要选择Python 2.7,然后点击Create。
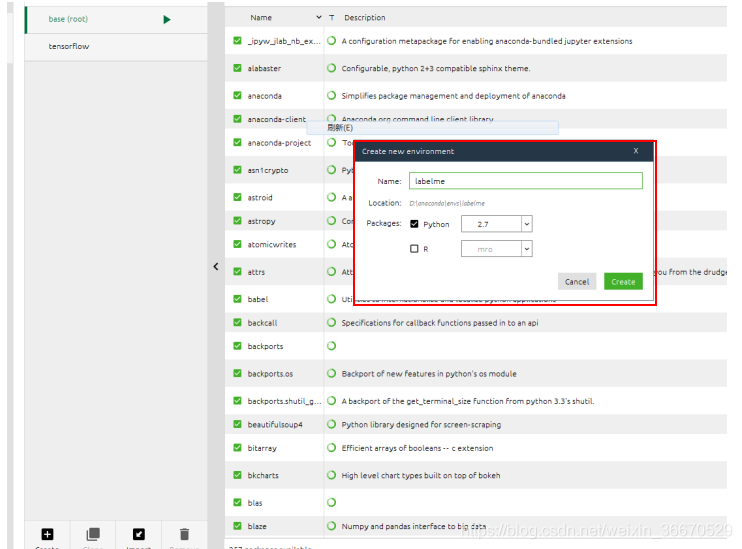
图10创建虚拟环境
第六步:已经创建了一个虚拟环境,如图11所示,点击图11的三角形启动虚拟环境,选择Open Terminal,弹出命令行窗口,如图12所示

图11启动虚拟环境

图12 labelme虚拟环境
第七步,一次输入命令conda install pyqt和pip install labelme完成labelme的安装,遇到所有的[y/n]都选y,如图13所示,

图13 labelme安装
第八步,输入命令labelme启动labelme,如图14所示,labelme界面如图15所示,

图14 labelme启动

图15 labelme主界面
第九步,标注数据集,为了使方法更具一般性,假设一幅图上同时发生了崩塌、滑坡和泥石流,如示例图像图16所示,

图16 示例图像
用labelme打开示例图片,如图17所示,

图17 labelme打开的图片
点击Create polygons对目标一个一个进行标记,对目标围成一个圈之后,对滑坡、崩塌、泥石流分别取名为slide、collapse、debris_flow,完成之后生成三个目标,如下图右边所示,多了三个目标标签,完成之后保存,会生成一个.json文件,如图18所示,

图18标记完成的文件

图19 labelme标记完成
第十步,对json文件进行解析生成最终的ground truth。打开anaconda下的Anaconda Prompt,输入命令activate labelme,如图20所示,

图20 json解析窗口
然后将json文件放到当前目录下,我的是C:\Users\optimal,输入命令 labelme_json_to_dataset <文件名>.json,在当前目录下就会生成一个新的文件,我的是timg_json,如图21所示,

图21 解析完成
打开文件,文件里有四个文件如图22所示,

图22标注完成的标签
对标签文件进行改名,把图片字和一个下划线加到每个文件的前面,我的是img,完成后如图23所示,

图23 标注完成的文件和文件名