T1:分数
1/1 + 1/2 + 1/4 + 1/8 + 1/16 + … ,每项是前一项的一半,如果一共有20项,求这个和是多少,结果用分数表示出来。类似:3/2。当然,这只是加了前2项而已。分子分母要求互质。 注意:
需要提交的是已经约分过的分数,中间任何位置不能含有空格。 请不要填写任何多余的文字或符号。
思路分析,简单利用等比数列求和公式就行。Sn=a1(1-q ^n)/(1-q)=2-1/(2 ^19)=(2 ^20-1)/2 ^19
所以这里只是需要计算2 ^19以及2 ^20,可以利用快速幂,另外注意别忘了约分。
代码:
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
ll gcd(ll a,ll b) {
return b?gcd(b,a%b):a;
}
ll fastpow(ll x,ll y) { //求取x^y
ll res=1;
while(y) {
if(y%2==1) {//为奇数,当前最低位为1,res就要乘以当前位置的权重
res*=x;
}
x*=x; //每右移一次,最低位的权重都要乘以x
y/=2; //右移
}
return res;
}
int main() {
ll x=fastpow(2,19);
ll y=fastpow(2,20)-1;
ll a=x,b=y;
ll res=gcd(x,y);
a/=res;b/=res;
cout<<b<<'/'<<a;
return 0;
}
答案:1048575/524288
T2:星期一
整个20世纪(1901年1月1日至2000年12月31日之间),一共有多少个星期一? (不要告诉我你不知道今天是星期几)
注意:需要提交的只是一个整数,不要填写任何多余的内容或说明文字。
思路:先算出1901到2000一共多少天,得36525天,然后除以7等于5217余6。然后翻日历,发现2000年12月31日是周日,依次往前推,可以得出答案就是5217。
代码:
#include<iostream>
using namespace std;
bool leapyear(int n) { //判断是否是闰年
if(n%400==0||n%4==0&&n%100!=0) {
return true;
}else {
return false;
}
}
int count(int m,int n) { //从m年到n年一共多少天
int res=0;
for(;m<=n;m++) {
if(leapyear(m)) {
res+=366;
}
else {
res+=365;
}
}
return res;
}
int main() {
int x=count(1901,2000);
int y=x/7;
int z=x%7;
cout<<y<<endl;
return 0;
}
答案:5217
T3:乘积尾零
如下的10行数据,每行有10个整数,请你求出它们的乘积的末尾有多少个零?
5650 4542 3554 473 946 4114 3871 9073 90 4329
2758 7949 6113 5659 5245 7432 3051 4434 6704 3594
9937 1173 6866 3397 4759 7557 3070 2287 1453 9899
1486 5722 3135 1170 4014 5510 5120 729 2880 9019
2049 698 4582 4346 4427 646 9742 7340 1230 7683
5693 7015 6887 7381 4172 4341 2909 2027 7355 5649
6701 6645 1671 5978 2704 9926 295 3125 3878 6785
2066 4247 4800 1578 6652 4616 1113 6205 3264 2915
3966 5291 2904 1285 2193 1428 2265 8730 9436 7074
689 5510 8243 6114 337 4096 8199 7313 3685 211
思路:要是python的话可以不用那么麻烦,c++就要考虑乘积是否溢出了。我们不妨换一种思路,我们不算出乘积,直接找出0的个数。具体做法是:我们将每一个数进行因式分解,那么所有数相乘就等于他们所分解的数相乘,比如12 * 12=2 * 2 * 3 * 2 * 2 * 3,因式分解中不可能有0,因此想要在末尾产生0,那就只有2 * 5才能满足了,因此我们只要找到所有的这些分解后相乘的数中,有多少对2 * 5即可,具体做法就是找出2和5当中出现次数较少的那个值。
代码:
#include<iostream>
#include<cstdio>
using namespace std;
typedef long long LL;
int main() {
int a[]={5650,4542,3554,473,946,4114,3871,9073,90,4329
,2758,7949,6113,5659,5245,7432,3051,4434,6704,3594
,9937,1173,6866,3397,4759,7557,3070,2287,1453,9899
,1486,5722,3135,1170,4014,5510,5120,729,2880,9019
,2049,698,4582,4346,4427,646,9742,7340,1230,7683
,5693,7015,6887,7381,4172,4341,2909,2027,7355,5649
,6701,6645,1671,5978,2704,9926,295,3125,3878,6785
,2066,4247,4800,1578,6652,4616,1113,6205,3264,2915
,3966,5291,2904,1285,2193,1428,2265,8730,9436,7074
,689,5510,8243,6114,337,4096,8199,7313,3685,211};
int num2=0,num5=0;
for(int i=0;i<100;i++) {
while(1) {
if(a[i]%2==0) {
num2++;
a[i]/=2;
}
else if(a[i]%5==0) {
num5++;
a[i]/=5;
}
else break;
}
}
printf("%d\n",num2<num5?num2:num5);
return 0;
}
答案:31
T4:第几个幸运数
到x星球旅行的游客都被发给一个整数,作为游客编号。 x星的国王有个怪癖,他只喜欢数字3,5和7。
国王规定,游客的编号如果只含有因子:3,5,7,就可以获得一份奖品。 我们来看前10个幸运数字是: 3 5 7 9 15 21 25 27 35 45 因而第11个幸运数字是:49 小明领到了一个幸运数字59084709587505,他去领奖的时候,人家要求他准确地说出这是第几个幸运数字,否则领不到奖品。
请你帮小明计算一下,59084709587505是第几个幸运数字。 需要提交的是一个整数,请不要填写任何多余内容。
思路:因子只含357,那么最暴力最暴力的解法就是枚举,从1一直枚举,对该数进行因式分解,如果只含有357那么就count++。但在很明显这个会超时,因此我们得进行优化。
我们不妨观察这组数据,3、5、7、15、21、27。最前面三个数是357毫无疑问,那么接下来的一个数要怎么操作才能使得它的因数也只有357呢?答案就是用前面的数分别乘上357。这样产生的三个数,它的因数一定只有357,这应该很好理解。 3乘上357分别是15、21、27,接下来5乘上357分别是15、25、35,但是15已经出现过了,因此我们需要判重,c++提供的集合set恰好可以解决这个问题,set不仅可以判重,还可以解决排序的问题。
注意我们上面的思路,先是357,然后是3乘上357,接下来是5,为了我们每次乘上357的这个数都是第一个数,我们需要一个队列来存储这些数据,每次取队头这个数乘上357。但是又有一个问题,队列每次必须要保证取出的数是里面最小的,我们可以考虑priority_queue,也是从小到大排序的。
#include<bits/stdc++.h>
using namespace std;
priority_queue<long long,vector<long long>,greater<long long> > q; //从小到大排序
set<long long> s;
int main() {
q.push(1); //1乘上3,5,7就是3,5,7
s.insert(1); //q,s同步,q提供每次乘上357的数
long long ans=-1;
while(1) {
long long n=q.top();
ans++;
if(n==59084709587505) {
break;
}
q.pop();
for(int i=3;i<=7;i+=2) {
long long m=n*i;
if(!s.count(m)) {
q.push(m);
s.insert(m);
}
}
}
cout<<ans;
}
答案:1905
T5:打印图形
如下的程序会在控制台绘制分形图(就是整体与局部自相似的图形)。
当n=1时图形长这样:
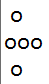
当n=2时:
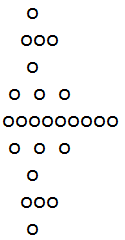
当n=3时:

#include <stdio.h>
#include <stdlib.h>
void show(char* buf, int w){
int i,j;
for(i=0; i<w; i++){
for(j=0; j<w; j++){
printf("%c", buf[i*w+j]==0? ' ' : 'o');
}
printf("\n");
}
}
void draw(char* buf, int w, int x, int y, int size){
if(size==1){
buf[y*w+x] = 1;
return;
}
int n = _________________________ ; //填空
draw(buf, w, x, y, n);
draw(buf, w, x-n, y ,n);
draw(buf, w, x+n, y ,n);
draw(buf, w, x, y-n ,n);
draw(buf, w, x, y+n ,n);
}
int main()
{
int N = 3;
int t = 1;
int i;
for(i=0; i<N; i++) t *= 3;
char* buf = (char*)malloc(t*t);
for(i=0; i<t*t; i++) buf[i] = 0;
draw(buf, t, t/2, t/2, t);
show(buf, t);
free(buf);
return 0;
}
答案:size/3,暂时不会。
T6:航班时间
具体见:【航班时间】2018第九届蓝桥杯【C/C++省赛A组】
T7:三体攻击
【题目描述】
三体人将对地球发起攻击。为了抵御攻击,地球人派出了 A × B × C 艘战舰,在太空中排成一个 A 层 B 行 C 列的立方体。其中,第 i 层第 j 行第 k 列的战舰(记为战舰 (i, j, k))的生命值为 d(i, j, k)。
三体人将会对地球发起 m 轮“立方体攻击”,每次攻击会对一个小立方体中的所有战舰都造成相同的伤害。具体地,第 t 轮攻击用 7 个参数 lat, rat, lbt, rbt, lct, rct, ht 描述;
所有满足 i ∈ [lat, rat],j ∈ [lbt, rbt],k ∈ [lct, rct] 的战舰 (i, j, k) 会受到 ht 的伤害。如果一个战舰累计受到的总伤害超过其防御力,那么这个战舰会爆炸。
地球指挥官希望你能告诉他,第一艘爆炸的战舰是在哪一轮攻击后爆炸的。
【输入格式】
从标准输入读入数据。
第一行包括 4 个正整数 A, B, C, m;
第二行包含 A × B × C 个整数,其中第 ((i − 1)×B + (j − 1)) × C + (k − 1)+1 个数为 d(i, j, k);
第 3 到第 m + 2 行中,第 (t − 2) 行包含 7 个正整数 lat, rat, lbt, rbt, lct, rct, ht。
【输出格式】
输出到标准输出。
输出第一个爆炸的战舰是在哪一轮攻击后爆炸的。保证一定存在这样的战舰。
【样例输入】
2 2 2 3
1 1 1 1 1 1 1 1
1 2 1 2 1 1 1
1 1 1 2 1 2 1
1 1 1 1 1 1 2
【样例输出】
2
【样例解释】
在第 2 轮攻击后,战舰 (1,1,1) 总共受到了 2 点伤害,超出其防御力导致爆炸。
【数据约定】
对于 10% 的数据,B = C = 1;
对于 20% 的数据,C = 1;
对于 40% 的数据,A × B × C, m ≤ 10, 000;
对于 70% 的数据,A, B, C ≤ 200;
对于所有数据,A × B × C ≤ 10^6, m ≤ 10^6, 0 ≤ d(i, j, k), ht ≤ 10^9。
思路分析:暂时只会暴力求解,拿下一半的分数。。。太菜了,等我想到办法再列上来。
T8:全球变暖
具体请参考:第九届蓝桥杯省赛C语言A8:全球变暖
T9:倍数问题
【题目描述】
众所周知,小葱同学擅长计算,尤其擅长计算一个数是否是另外一个数的倍数。但小葱只擅长两个数的情况,当有很多个数之后就会比较苦恼。现在小葱给了你 n 个数,希望你从这 n 个数中找到三个数,使得这三个数的和是 K 的倍数,且这个和最大。数据保证一定有解。
【输入格式】
从标准输入读入数据。
第一行包括 2 个正整数 n, K。
第二行 n 个正整数,代表给定的 n 个数。
【输出格式】
输出到标准输出。
输出一行一个整数代表所求的和。
【样例入】
4 3
1 2 3 4
【样例输出】
9
【样例解释】
选择2、3、4。
【数据约定】
对于 30% 的数据,n <= 100。
对于 60% 的数据,n <= 1000。
对于另外 20% 的数据,K <= 10。
对于 100% 的数据,1 <= n <= 10^5, 1 <= K <= 10^3,给定的 n 个数均不超过 10^8。
解题思路:最简单的方法就是暴力循环,找到答案,应该能得到大部分的分数。这题我们换下思路,回忆以前做过的那种选数问题,我们用到了dfs,这里其实也可以用dfs。具体做法是:先选择一个数,然后标记已经选好,接着选下一个数,因为我们并不能保证下一个没被选择的数一定是最优解里面的一个数,因此要记得回溯!!!
代码:
#include<bits/stdc++.h>
using namespace std;
const int maxn=100000;
long long a[maxn];
bool visited[maxn];
long long b[3]; //结果数组
static int res=-789; //保存最后的和
int k,n;
void dfs(int x) {
if(x==3) {
if((b[0]+b[1]+b[2])%k==0&&(b[0]+b[1]+b[2]>res)){
res = b[0]+b[1]+b[2];
}
}
else {
for(int i=0;i<n;i++) {
if(visited[i]==false) {
visited[i] = true; //标记被访问过
b[x] = a[i];
dfs(x+1);
visited[i] = false; //回溯
}
}
}
}
int main() {
cin>>n>>k;
memset(visited,false,sizeof(visited));
for(int i=0;i<n;i++) {
cin>>a[i];
}
dfs(0);
cout<<res<<endl;
return 0;
}
T10:付账问题
【题目描述】
几个人一起出去吃饭是常有的事。但在结帐的时候,常常会出现一些争执。
现在有 n 个人出去吃饭,他们总共消费了 S 元。其中第 i 个人带了 ai 元。幸运的是,所有人带的钱的总数是足够付账的,但现在问题来了:每个人分别要出多少钱呢?
为了公平起见,我们希望在总付钱量恰好为 S 的前提下,最后每个人付的钱的标准差最小。这里我们约定,每个人支付的钱数可以是任意非负实数,即可以不是1分钱的整数倍。你需要输出最小的标准差是多少。
标准差的介绍:标准差是多个数与它们平均数差值的平方平均数,一般用于刻画这些数之间的“偏差有多大”。形式化地说,设第 i 个人付的钱为 bi 元,那么标准差为 : [参见p1.png]
【输入格式】
从标准输入读入数据。
第一行包含两个整数 n、S;
第二行包含 n 个非负整数 a1, …, an。
【输出格式】
输出到标准输出。
输出最小的标准差,四舍五入保留 4 位小数。
保证正确答案在加上或减去 10^−9 后不会导致四舍五入的结果发生变化。
【样例1输入】
5 2333
666 666 666 666 666
【样例输出】
0.0000
【样例解释】
每个人都出 2333/5 元,标准差为 0。
再比如:
【样例输入】
10 30
2 1 4 7 4 8 3 6 4 7
【样例输出】
0.7928
【数据说明】
对于 10% 的数据,所有 ai 相等;
对于 30% 的数据,所有非 0 的 ai 相等;
对于 60% 的数据,n ≤ 1000;
对于 80% 的数据,n ≤ 10^5;
对于所有数据,n ≤ 5 × 10^5, 0 ≤ ai ≤ 10^9。
解题思路:这题的大概意思就是找到一组数使得它们的标准差最小。标准差最小意味着什么?意味着每个人付钱数目要尽量靠近均值。 均值是固定已知的,每个人带的钱要么小于这个值要么大于这个值。
小于均值的应该付多少呢?答案是全部。我们不妨设想,假设他不付全部,那么他的付钱数目距离均值就会变远;另外,带钱大于均值的人要付的更多,也就离均值更远,所以“双重打击”会使得标准差变得更大。因此,带钱小于均值的,不应该藏着掖着,应该给出所有。
大于均值的自然应该给上述那些人补出没付的那部分,那么关键就是怎么补呢?我们不妨这样想:当一个人出的钱已经小于均值的时候,他出钱的数目是一定的,那么我们就不需要考虑他们了,对于剩下的这部分人,我们重新算均值,然后重新比较大小,直到不存在小于均值的人,就结束。
因此,我们第一步要做的就是排序,然后求出均值,筛掉小于均值的那部分,对剩余部分求同样操作,直到不存在有人的钱小于均值!!
这道题的思想有点贪心的意思在里面,就我每次让小于均值的那部分人给出全部的钱,这样可以使当前的标准差最小,不断迭代,进而使全局的标准差最小。
代码:
#include<bits/stdc++.h>
using namespace std;
const int maxn=5e5+10;
long long a[maxn];
int main() {
int n,S;
cin>>n>>S;
for (int i = 0; i < n; i++) {
cin>>a[i]; //输入钱
}
sort(a, a + n); //排序
double avg = S * 1.0 / n; //求原始均值
double newavg = avg; //每次迭代后新的均值
double ans = 0; //方差
for (int i = 0; i < n; i++) {
if (a[i] < newavg) {
ans += pow(a[i] - avg, 2); //小于当前均值,直接就给全部钱
S -= a[i]; //从总额里扣除
newavg = S * 1.0 / (n - i - 1); //计算新的均值
}
else {
ans += (n - i)*pow(newavg - avg, 2); //所有人都大于均值,就付均值这么多钱
break;
}
}
ans = sqrt(ans / n);
printf("%.4lf\n", ans);
return 0;
}