大家好,我是不温卜火,是一名计算机学院大数据专业大二的学生,昵称来源于成语—
不温不火,本意是希望自己性情温和。作为一名互联网行业的小白,博主写博客一方面是为了记录自己的学习过程,另一方面是总结自己所犯的错误希望能够帮助到很多和自己一样处于起步阶段的萌新。但由于水平有限,博客中难免会有一些错误出现,有纰漏之处恳请各位大佬不吝赐教!暂时只有csdn这一个平台,博客主页:https://buwenbuhuo.blog.csdn.net/
这篇文章讲述的是基于模型的缺失值填补。希望这篇数据清洗的文章对您有所帮助!如果您有想学习的知识或建议,可以给作者留言~
基于模型的方法会将含有缺失值的变量作为预测目标
将数据集中其他变量或其子集作为输入变量,通过变量的非缺失值构造训练集,训练分类或回归模型
使用构建的模型来预测相应变量的缺失值

一、线性回归
是一种数据科学领域的经典学习算法
用来刻画响应变量与自变量之间的关系
线性回归模型的数学表达式为:


- 1、线性回归可以用来预测响应变量,那如何用来进行缺失值填充呢?
- 含有缺失值的属性作为因变量
- 其余的属性作为多维的自变量
- 建立二者之间的线性映射关系
- 求解映射函数的次数
- 2、在训练线性回归模型的过程中
- 数据集中的完整数据记录作为训练集,输入线性回归模型
- 含有缺失值的数据记录作为测试集,缺失值就是待预测的因变量
这样,一个缺失值填补的问题就成为一个经典的回归预测问题
- 含缺失值的属性是目标属性,运用线性回归进行填补,顺理成章
- 如果自变量存在缺失值,运用线性回归算法进行填补
- 但是,增大属性之间的相关性,对原始数据集的分析造成影响
- 3、线性回归填补和插入法的关系
- 线性回归要求
拟合函数与原始数据的误差最小,是一种整体靠近,对局部性质没有要求
- 插入方法要求
在原有数据之间插入数值,插值函数必须经过所有的已知数据点
二、KNN算法
通过计算训练集样本与目标样本的相似性,“鼓励”每个样本与目标样本去匹配
根据给定条件,选择最适合的K个样本作为目标样本的“邻居”
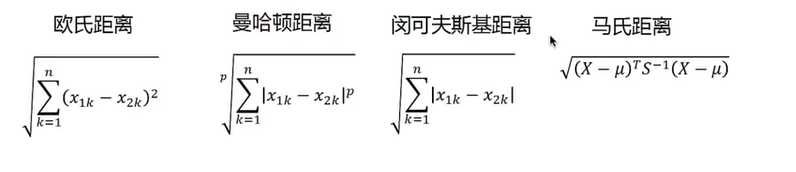
相似性的度量有以下选择:
- 1、主要步骤:
计算距离:给定目标样本,计算它与训练集中每个样本的距离
寻找邻居:选择距离最近的K个训练集样本,作为目标样本的近邻
分类预测:根据近样本的所属类别,或者属性的取值来预测目标样本的类别或者属性取值
- 2、使用KNN算法进行缺失值填补
当预测某个样本的缺失属性时,KNN会先去寻找与该样本最相似的K个样本
通过观察近邻样本的相关属性取值,来最终确定样本的缺失属性值
- 数据集的实例s存在缺失值,根据无缺失的属性信息,寻找K个与s最相似的实例
- 依据属性在缺失值所在字段下取值,来预测s的缺失值
- 3、数据集介绍
- 对青少年数据集的缺失值属性gender进行填补
学生的兴趣对其性别具有较好的指示作用
将兴趣作为输入属性,将gender属性作为预测目标
- 数据集包含40个变量,其中gradyear,gender,age和friends分别代表高中生的毕业年份、性别、年龄和好友数等基本信息
- 其余36个变量代表36个词语,这36个词语代表高中生的五大兴趣类:课外活动、时尚、宗教、浪漫和反社会行为
- 4、数据集处理
把gender属性作为目标属性,36个表征兴趣的属性作为输入属性
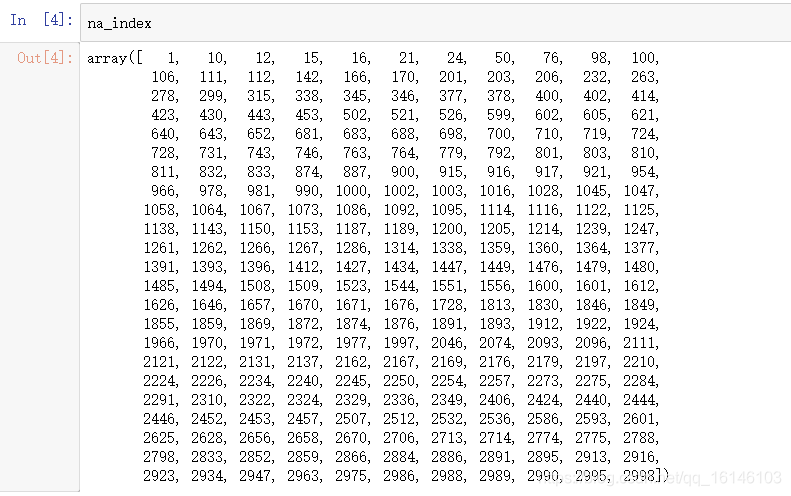
- 缺失值所在的行索引
import pandas as pd
import numpy as np
teenager = pd.read_csv('./input/teenager.csv')
teenager['gender'].value_counts(dropna=False)
na_index = teenager[teenager['gender'].isnull()].index.values
- 完整样本的行索引
# 不含有缺失值的索引, 可作为我们的训练集
normal_index = teenager[~teenager['gender'].isnull()].index.values

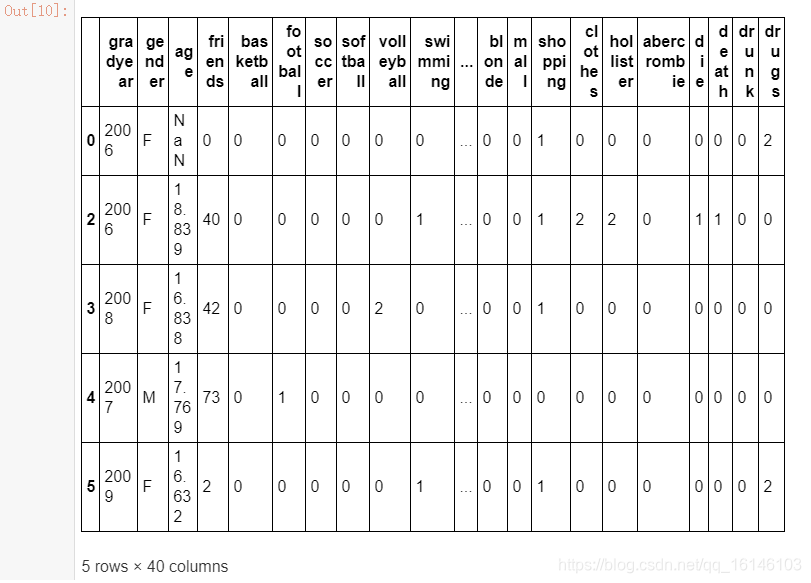
- 将不含有缺失值的索引,做成训练集
# x为兴趣爱好,y为性别
trainX = teenager.iloc[normal_index]
trainY = teenager.iloc[normal_index,1]
trainX.head()
- 把含有缺失值的样本作为测试集
testX = teenager.iloc[na_index]
testY = teenager.iloc[na_index,1]
- 计算欧氏距离
# 计算欧式距离
distances = []
for item in testX.iloc[:,4:].values:
dist = {}
for index, item1 in enumerate(trainX.iloc[:,4:].values):
distance = np.sqrt(np.sum(np.square(item - item1)))
dist[index] = distance
distances.append(dist)
enumerate()函数,可以在生成值得时候能够自定生成递增序列
enumerate(trainX.iloc[:,4:].values)
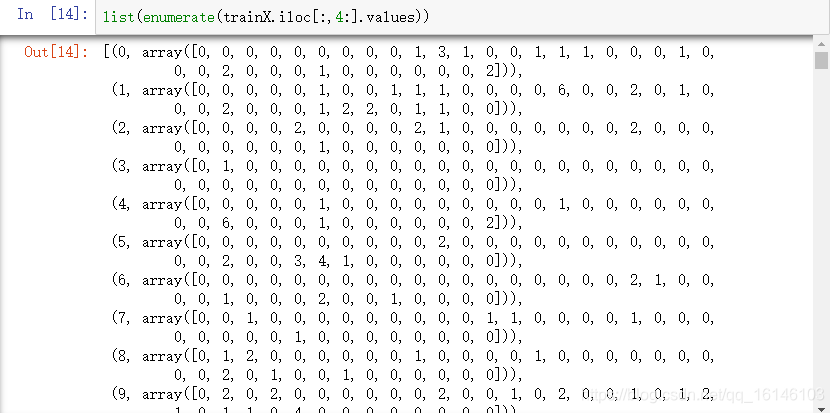
- 查看distances中得元素
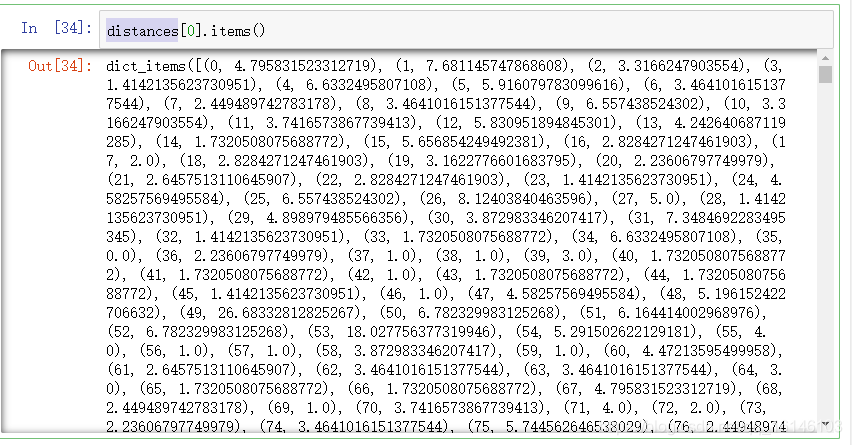
- 对每一个测试集到所有得训练集的距离排序
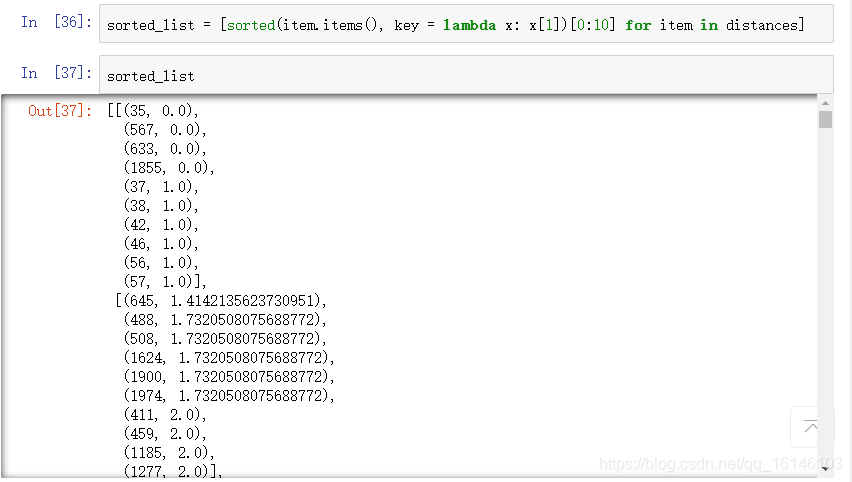
- 预测多数性别
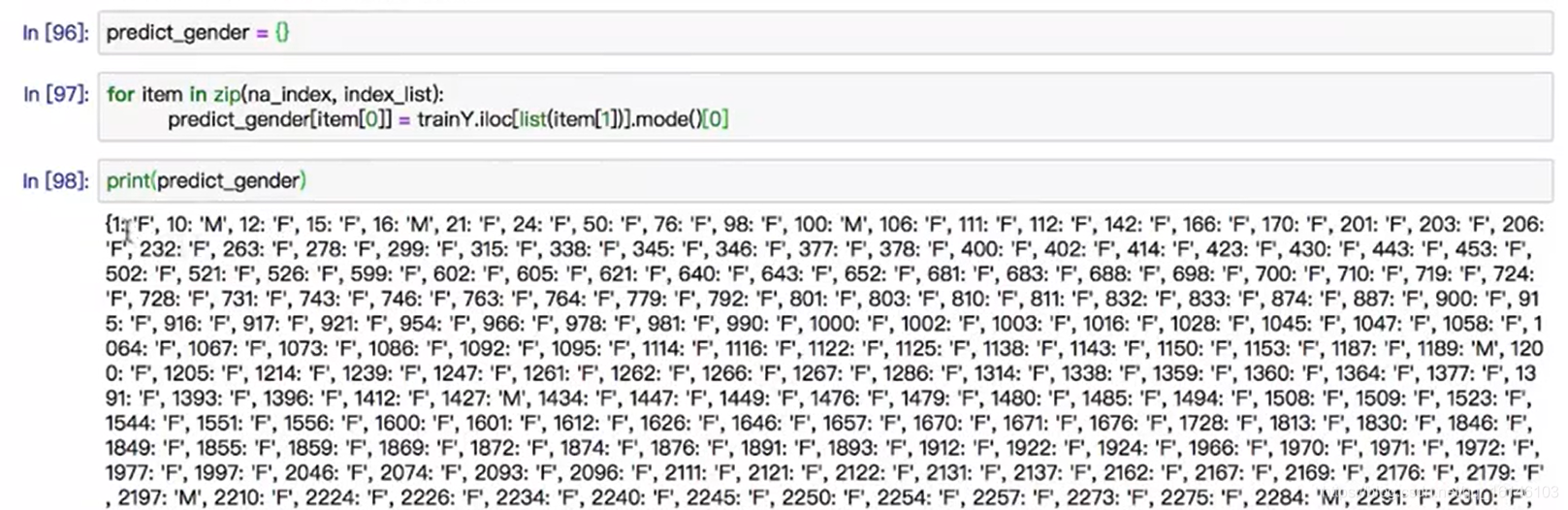
- 5、KNN算法总结
- 使用KNN算法进行缺失值填补需要注意:
KNN是一个偏差小,方差大的计算模型
KNN只选取与目标样本相似的完整样本参与计算,精度相对来说比较高
为了计算相似程度,KNN必须重复遍历训练集的每个样本
如果数据集容量较大,KNN的计算代价会升高
- 使用KNN算法进行缺失值填补需要注意:
标准KNN算法对数据样本的K个邻居赋予相同的权重,并不合理
一般来说,距离越远的数据样本所能施加的影响就越小
需要对KNN一定的改进,比如让邻居的权重与距离成反比关系
本次的分享就到这里了,

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请“点赞” “评论”“收藏”一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
码字不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!