draft-detect
运行环境:
Windows10 系统 6核6线程 16G内存
基于 Python3.8 版本 vitualenv 虚拟环境
1、安装依赖
先创建虚拟环境,基于Python3.8,然后激活虚拟环境。
安装 requirements 中的依赖项
pip install -r requirements.txt
安装版面分析的特定库,注意:只能安装这个库,其他版本的库会有问题
pip install -U https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl
2、解析流程
1、相关服务
api_server 接口服务,用于外部上传票面进行票据识别,并返回识别内容。
slice_table 用于将票据进行分类,将表格数据和票号等数据分隔开来。
table_ceil 用于将表格识别并解析为Excel,此时可以根据表格解析为结构化数据。
ocr_dect 用于识别图像中的文本,并输出文字到指定位置。主要是识别票号数据和表格中的数据。
focus_draft 票据数据聚合服务,用于将所有的到的数据聚合成一个整体的票据结构化数据。
2、识别流程
1、由 web 服务接收图像。
2、使用 slice_table 做版面分析,拆出表格部分、票号部分。
3、分别识别票号部分和表格部分,最后做合并,尝试了多线程和多进程分开异步识别,由于是计算密集型反而识别时间增加了。
4、使用聚合服务将数据聚合成一个整体的票据结构化数据。
5、由 web 接口返回结果。
3、相关模型
inference/ch_PP-OCRv2_det_infer 飞桨OCR文本识别模型
inference/ch_PP-OCRv2_rec_infer 飞桨OCR文本检测模型
inference/ch_ppocr_mobile_v2.0_cls_infer 飞桨OCR文本方向分类模型
models/table-line-fine-last.h5 基于 TensorFlow 的表格检测模型
slice_table.py 中的 lp://TableBank/ppyolov2_r50vd_dcn_365e_tableBank_latex/config 基于 layoutparser 的版面分析模型
3、启动服务
python api_server.py
4、测试服务
接口地址:http://127.0.0.1:8080/table/predict
请求方式:POST
请求参数:form-data 传参
- file 要识别的票据图像
- isToExcel 是否输出识别后的 Excel,1 表示 是,否则为 否。保存位置为 ceil-result
- isToCeil 是否输出识别后的表格框图片,1 表示 是,否则为 否。保存位置为 excel-result
请求示例:
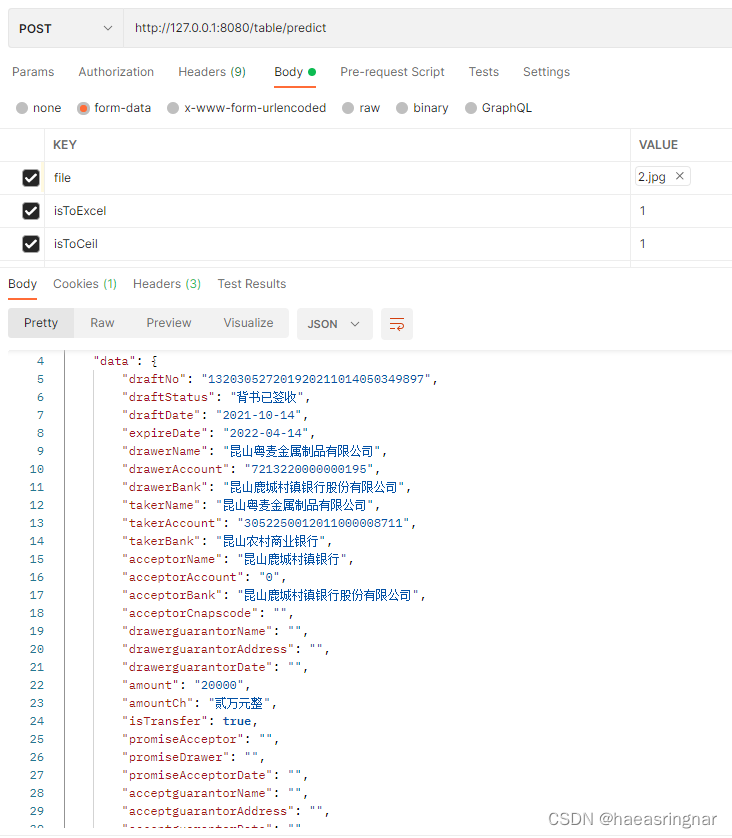
传入的图像:
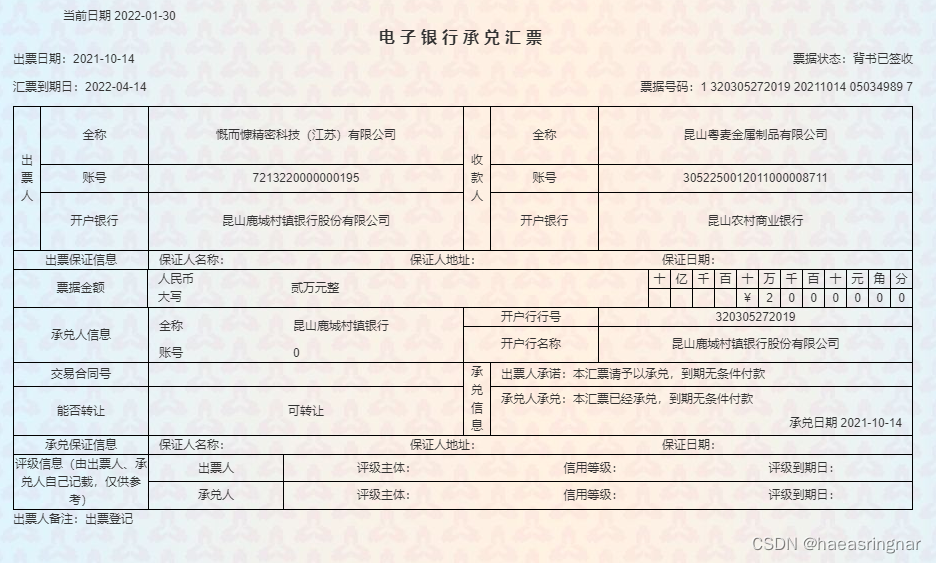
识别的框:
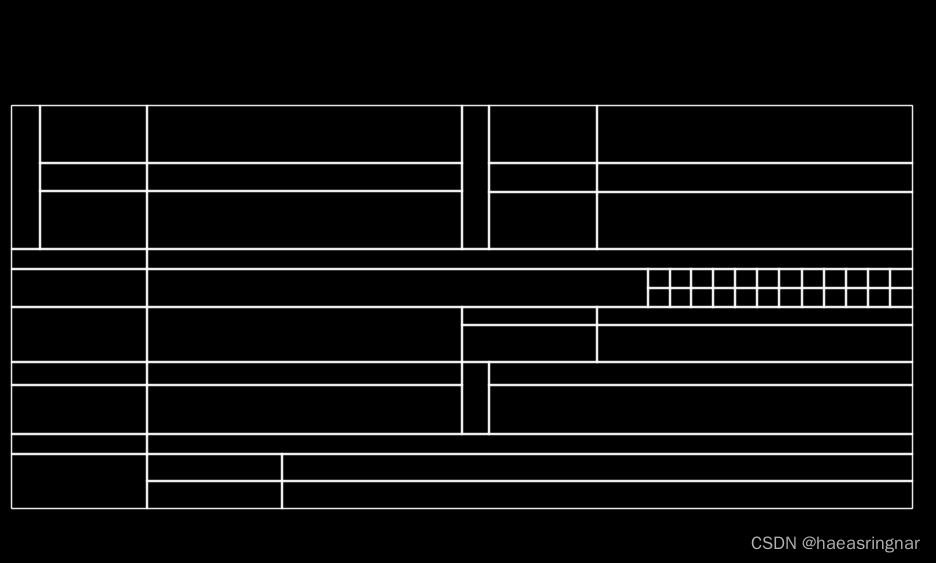
识别的表格:

5、表格如何打标
表格打标使用 labelme 工具,官方地址:https://github.com/wkentaro/labelme
1、安装labelme
pip install labelme==5.0.1
安装完成后还需要修改源码保证工具可以打标png类型的图像
修改如下:
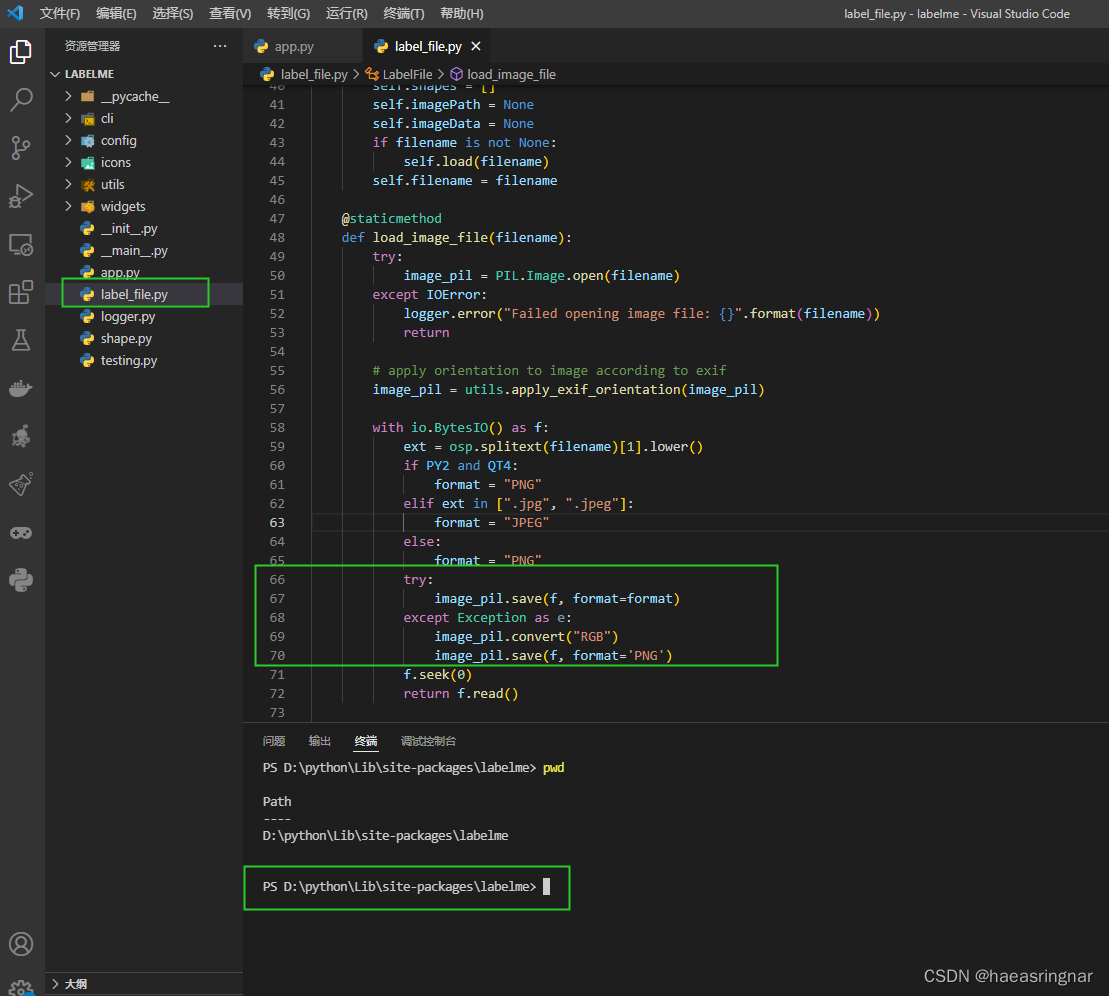
2、使用labelme进行打标
使用命令启动 labelme,打开终端,输入 labelme 按下回车键即可。

打完一张标注后,点击完成即可保存为可训练标注文件。
3、如何训练
将所有标注好的文件放入到 ./train/dataset-line/0/ 中
然后执行训练脚本,等待训练完成后,会将新的模型保存为 ./models/table-line-fine.h5
python train/train.py
4、使用新的模型进行预测
将配置文件 config.py 中的 tableModeLinePath 修改为新的模型路径即可。
启动服务后进行测试即可
python api_server.py