本文介绍流计算的概念、什么是Storm、Storm的安装以及如何运行Storm自带的单词统计测试例子。
静态数据和流数据
在讲清楚什么是Storm之前,我们需要了解流计算的概念。而在讲清楚什么是流计算之前,我们要先了解流计算的处理对象:流数据,而要阐明什么是流数据,我们又不得不先引入流数据的对照物:静态数据。
数据总体上可以分为静态数据和流数据
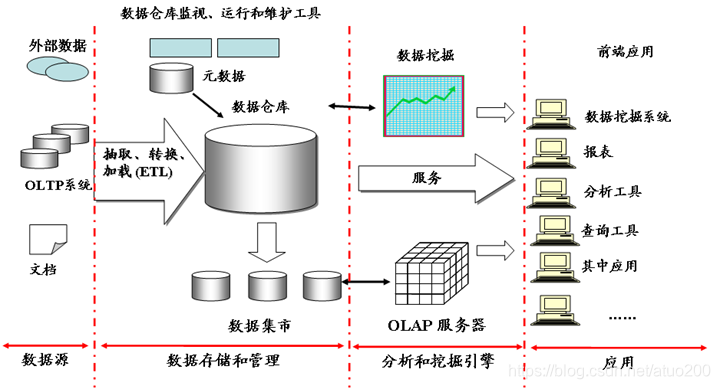
- 静态数据:如果把数据存储系统比作一个“水库”,那么存储在数据存储系统中的静态数据就像水库中的水,是静止不动的。很多企业为了支持决策分析而构建的数据仓库系统,其中存放的大量的历史数据就是静态数据,这些数据来自不同的数据源,利用ETL工具加载到数据仓库中,并且不会发生更新,技术人员可以利用数据挖掘和OLAP分析工具从这些静态数据中找到对企业有价值的信息。
- 流数据:假如静态数据是“水库”,那么流数据就像不断奔涌的“河流”,即以大量、快速、时变的流形式持续到达的数据。
批量计算和实时计算
对静态数据和流数据的处理,对应着两种截然不同的计算模式:批量计算和实时计算。
- 批量计算以“静态数据”为对象,可以在很充裕的时间内对海量数据进行批量处理,计算得到有价值的信息。Hadoop就是典型的批处理模型,由HDFS和HBase存放大量的静态数据,由MapReduce负责对海量数据执行批量计算。
- 流数据必须采用实时计算,实时计算最重要的一个需求是能够实时得到计算结果,当只需要处理少量数据时,实时计算并不是问题;但是,在大数据时代,数据格式复杂、来源众多,而且数据量巨大,这就对实时计算提出了很大的挑战。因此,针对流数据的实时计算——流计算,应运而生。
到这里我们了解到实时计算和流计算两者有一定的相关性,但两者并不相同。可以说流计算是实时计算的一个子集,流计算强调数据以数据流的形式输入、处理和输出,实时计算强调数据输入到产出最终结果的时延要低,其本身并不关心数据是以何种形式在系统中传递。
流计算框架的要求
流计算秉持着一个基本理念,即数据的价值会随着时间的流逝降低,因此,当数据到达时就应该立即进行处理,而不是存储起来后续进行批量处理。为了及时处理数据,就需要一个低延迟、可扩展、高可靠的处理引擎。对于一个流计算框架来说,它应达到如下需求。
- 高性能:处理大数据的基本要求,如每秒处理几十万条数据。
- 海量式:支持TB级甚至是PB级的数据规模。
- 实时性:必须保证一个较低的延迟时间,达到秒级别,甚至是毫秒级别。
- 分布式:支持大数据的基本架构,能够水平扩展
- 易用性:能够快速进行开发和部署。
- 可靠性:能可靠地处理流数据。
而Storm就是集合了以上优秀特性的一个流计算框架。
认识Storm
Storm简介
Twitter Storm是一个免费、开源的分布式实时计算系统,Storm可以简单、高效、可靠地处理流数据,并支持多种编程语言。并且按照Storm作者的说法:Storm对于实时计算的意义类似于Hadoop对于批处理的意义,该怎样理解这句话呢?Hadoop为批量计算抽象出了map和reduce原语,使我们的批处理程序变得简单和高效。同样,Storm也为实时计算抽象出了一些简单高效的原语Spouts和Bolts。

Storm具有以下主要特点:
- 整合性:Storm可方便地与队列系统和数据库系统进行整合
- 简易的API:Storm的API在使用上即简单又方便
- 可扩展性:Storm可以运行在分布式集群中
- 容错性:Storm可自动进行故障节点的重启、任务的重新分配
- 可靠的消息处理:Storm保证每个消息都能完整处理
- 支持各种编程语言:Storm支持使用各种编程语言来定义任务
- 快速部署:Storm可以快速进行部署和使用
- 免费、开源:Storm是一款开源框架,可以免费使用
Storm的设计思想
Storm对一些设计思想进行了抽象化,其主要术语包括Streams、Spouts、Bolts、Topology和Stream Groupings。
-
Streams:即数据流,也可以看做是“水流”。一个无限的Tuple序列,Tuple即元组,是元素的有序列表,每一个Tuple就是一个值列表,列表中的值可以类型不一。。
-
Spouts:有了“水流”,自然会有“水流”的源头,Spouts就是Streams的源头,Spouts会从外部读取流数据并持续不断地发出Tuple,假如Streams是“水流”,那么Spouts则为“水龙头”。
-
Bolts:流的中间状态转换,可以理解为“水处理器”,Bolts会对接收到的Tuple进行相应的计算及处理。
-
Topology:对Spouts和Bolts的高度抽象,表示“水流”导向的流转换拓扑图,类似Hadoop中的MapReduce作业,一个Topology就是一个Storm作业
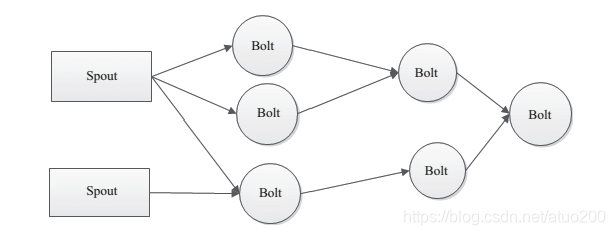
- Stream Groupings:用于告知Topology如何在两个组件间(如Spouts和Bolts之间,或者不同的Bolt之间)进行Tuple的传送,实际上Stream Groupings可以看作是定义spouts上一堆task对应bolt上另一堆task的分配策略,其分配策略有如下几种:

Storm的框架设计
不多阐述,来看别人写的博文:Storm框架设计
Storm的安装
Storm的下载网址:Index of /apache/storm,我选取的Storm版本是1.2.3
执行如下命令安装Storm
sudo tar -zxf apache-storm-1.2.3.tar.gz -C /usr/local
cd /usr/local
sudo mv apache-storm-1.2.3 storm
sudo chown -R hadoop ./storm
执行如下命令配置环境变量
vi ~/.bashrc
export STORM_HOME=/usr/local/storm
export PATH=${STORM_HOME}/bin:$PATH
执行如下命令配置Storm
vi /usr/local/storm/conf/storm.yaml
配置如下配置项
storm.local.dir: "/usr/local/storm/localdir"
storm.zookeeper.port: 2181
storm.zookeeper.servers:
- "Master"
- "Slave1"
nimbus.seeds: ["master"]
ui.host: 192.168.100.10
ui.port: 8080
supervisor.slots.ports:
- 6700
- 6701
- 6702
其中
-
storm.zookeeper.servers: Storm集群使用的Zookeeper集群地址
-
storm.local.dir: Nimbus和Supervisor进程用于存储少量状态,如jars、confs等的本地磁盘目录,需要提前创建该目录并给以足够的访问权限(就是storm.local.dir指定的目录需要自己创建一下)
-
nimbus.host: Storm集群Nimbus机器地址
-
supervisor.slots.ports: 对于每个Supervisor工作节点,需要配置该工作节点可以运行的worker数量。每个worker占用一个单独的端口用于接收消息,该配置选项即用于定义哪些端口是可被worker使用的。默认情况下,每个节点上可运行4个workers,分别在6700、6701、6702和6703端口
最后,启动Storm
在Master上启动
storm nimbus &
在Slave1上启动
storm supervisor &
这里只是启动了nimbus和supervisor服务,如果还需要使用UI界面监控Storm,还需要在Master上另外启动ui服务:storm ui &。
启动完成之后不要忘记用jps命令查看一下相应的服务有没有正常启动。
运行Storm自带的测试例子
Storm中自带了一些例子放置在storm/examples下,我们可以执行一下example目录下的storm-starter中的WordCount 例子来感受一下 Storm 的执行流程。
进入到storm/examples/storm-starter目录下,再通过maven命令下载相应的依赖再打包jar包,-DskipTests=true参数表示打包jar包时不执行代码里的测试用例
cd /usr/local/storm/examples/storm-starter
mvn clean install -DskipTests=true
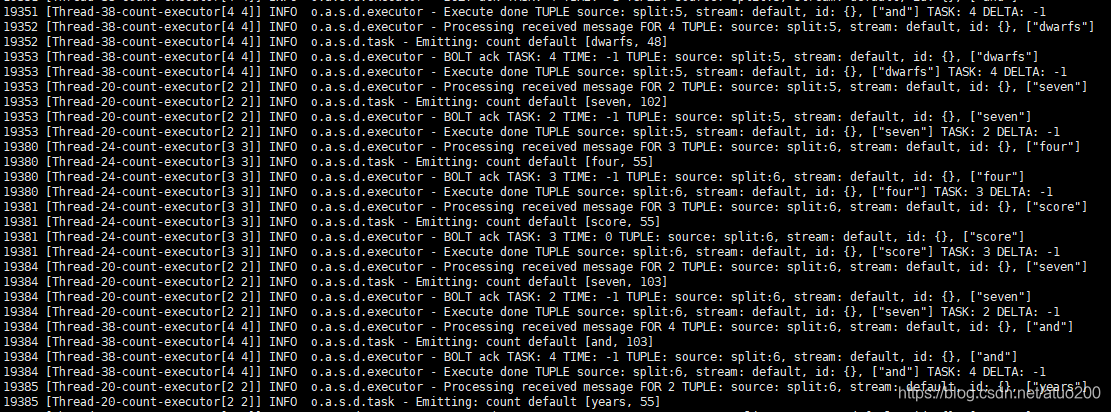
jar包打包完毕后,便可执行里面的WordCount实例,把输出的内容通过grep过滤,使只显示我们关心的信息:grep ‘Thread-[0-9]*-count’
storm jar ~/.m2/repository/org/apache/storm/storm-starter/1.2.3/storm-starter-1.2.3.jar org.apache.storm.starter.WordCountTopology -c nimbus.host=Master | grep 'Thread-[0-9]*-count'
如图便会输出单词的统计结果