原文地址:https://www.cnblogs.com/cutd/p/6740179.html
首先我要强调的是,Storm的分组策略对结果有着直接的影响,不同的分组的结果一定是不一样的。其次,不同的分组策略对资源的利用也是有着非常大的不同,本文主要讲一讲localOrShuffle这个分组对资源利用的重大改善。最后,不同的分组对项目的逻辑也起着至关重要的决定,比如在写数据的时候不同的分组策略会导致死锁。
简单理解数据流分组
拓扑定义的一部分就是为每个Bolt指定输入的数据流,而数据流分组则定义了在Bolt的task之间如何分配数据流。
目前的Storm1.1.0版本内置了8种流分组策略,除此之外你也可以通过实现 CustomStreamGrouping接口来实现自定义的流分组策略。下面将结合具体的需求场景来具体的聊聊这些内置的分组策略:
Shuffle grouping:
随机分组:随机的将tuple分发给bolt的各个task,每个bolt实例接收到相同数量的tuple。
Fields grouping:
按字段分组:根据指定的字段的值进行分组,举个栗子,流按照“user-id”进行分组,那么具有相同的“user-id”的tuple会发到同一个task,而具有不同“user-id”值的tuple可能会发到不同的task上。这种情况常常用在单词计数,而实际情况是很少用到,因为如果某个字段的某个值太多,就会导致task不均衡的问题。
Partial Key grouping:
部分字段分组:流由分组中指定的字段分区,如“字段”分组,但是在两个下游Bolt之间进行负载平衡,当输入数据歪斜时,可以更好地利用资源。本论文 提供了一个很好的解释,说明它的工作原理以及它提供的优点。有了这个分组就完全可以不用Fields grouping了。
All grouping:
全复制分组:将所有的tuple都复制之后再分发给Bolt所有的task,每一个订阅数据流的task都会接收到一份相同的完全的tuple的拷贝。
Global grouping:
全局分组:这种分组会将所有的tuple都发到一个taskid最小的task上。由于所有的tuple都发到唯一一个task上,势必在数据量大的时候会造成资源不够用的情况。
None grouping:
不分组:不指定分组就表示你不关心数据流如何分组。目前来说不分组和随机分组效果是一样的,但是最终,Storm可能会使用与其订阅的bolt或spout在相同进程的bolt来执行这些tuple。这可能是节省资源最好的一种方式吧,但是目前并未实现。
Direct grouping:
指向分组:这是一种特殊的分组策略。以这种方式分组的流意味着将由元组的生成者决定消费者的哪个task能接收该元组。指向分组只能在已经声明为指向数据流的数据流中声明。tuple的发射必须使用emitDirect种的一种方法。Bolt可以通过使用TopologyContext或通过在OutputCollector(返回元组发送到的taskID)中跟踪emit方法的输出来获取其消费者的taskID。
Local or shuffle grouping:
本地或随机分组:和随机分组类似,但是如果目标Bolt在同一个工作进程中有一个或多个任务,那么元组将被随机分配到那些进程内task。简而言之就是如果发送者和接受者在同一个worker则会减少网络传输,从而提高整个拓扑的性能。有了此分组就完全可以不用shuffle grouping了。
本地或随机分组对于并发度大的拓扑简直是神器好吧,发一张图让你们见识见识。
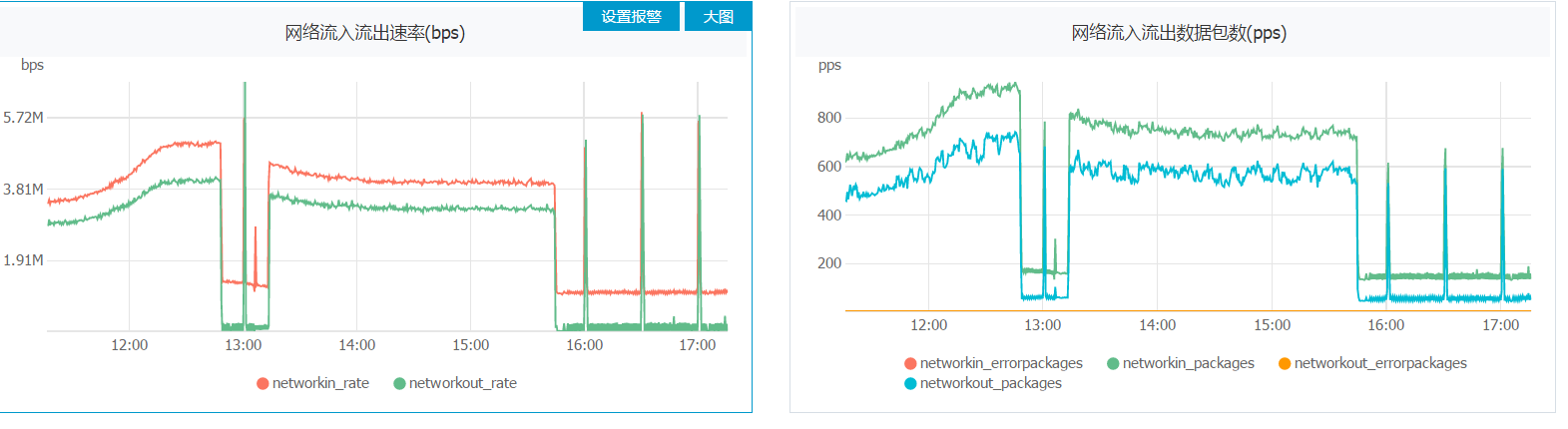
原文地址:https://www.cnblogs.com/LHWorldBlog/p/8352994.html
Storm分组策略
一、前述
Storm由数源泉spout到bolt时,可以选择分组策略,实现对spout发出的数据的分发。对多个并行度的时候有用。
二、具体原理
1. Shuffle Grouping
随机分组,随机派发stream里面的tuple,保证每个bolt task接收到的tuple数目大致相同。
轮询,平均分配
2. Fields Grouping(相同fields去分发到同一个Bolt)
按字段分组,比如,按"user-id"这个字段来分组,那么具有同样"user-id"的 tuple 会被分到相同的Bolt里的一个task, 而不同的"user-id"则可能会被分配到不同的task。
3. All Grouping
广播发送,对于每一个tuple,所有的bolts都会收到
4. Global Grouping
全局分组,把tuple分配给task id最低的task 。
5. None Grouping
不分组,这个分组的意思是说stream不关心到底怎样分组。目前这种分组和Shuffle grouping是一样的效果。 有一点不同的是storm会把使用none grouping的这个bolt放到这个bolt的订阅者同一个线程里面去执行(未来Storm如果可能的话会这样设计)。
6. Direct Grouping
指向型分组, 这是一种比较特别的分组方法,用这种分组意味着消息(tuple)的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为 Direct Stream 的消息流可以声明这种分组方法。而且这种消息tuple必须使用 emitDirect 方法来发射。消息处理者可以通过 TopologyContext 来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)
7. Local or shuffle grouping
本地或随机分组。如果目标bolt有一个或者多个task与源bolt的task在同一个工作进程中,tuple将会被随机发送给这些同进程中的tasks。否则,和普通的Shuffle Grouping行为一致
8.customGrouping
自定义,相当于mapreduce那里自己去实现一个partition一样。
总结:前4种用的多些,后面4种用的少些。
三、具体案例
Spout(产生数据):
package com.sxt.storm.grouping;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.Map;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
public class MySpout implements IRichSpout {
private static final long serialVersionUID = 1L;
FileInputStream fis;
InputStreamReader isr;
BufferedReader br;
SpoutOutputCollector collector = null;
String str = null;
@Override
public void nextTuple() {//真正发的逻辑
try {
while ((str = this.br.readLine()) != null) {
// 过滤动作
collector.emit(new Values(str, str.split("\t")[1]));//发出数据,一行和一行切分完后第二个字段。
}
} catch (Exception e) {
}
}
@Override
public void close() {//释放资源
try {
br.close();
isr.close();
fis.close();
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {//初始化(方法只调用一次)
try {
this.collector = collector;
this.fis = new FileInputStream("track.log");
this.isr = new InputStreamReader(fis, "UTF-8");
this.br = new BufferedReader(isr);
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {//声明发出去的字段
declarer.declare(new Fields("log", "session_id"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
@Override
public void ack(Object msgId) {
System.out.println("spout ack:" + msgId.toString());
}
@Override
public void activate() {
}
@Override
public void deactivate() {
}
@Override
public void fail(Object msgId) {
System.out.println("spout fail:" + msgId.toString());
}
}Bolt:(处理单元)
package com.sxt.storm.grouping;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
public class MyBolt implements IRichBolt {
private static final long serialVersionUID = 1L;
OutputCollector collector = null;
int num = 0;
String valueString = null;
@Override
public void cleanup() {
}
@Override
public void execute(Tuple input) {
try {
valueString = input.getStringByField("log");//通过fields接收数据
if (valueString != null) {
num++;
System.err.println(input.getSourceStreamId() + " " + Thread.currentThread().getName() + "--id="//打印当前进程名字
+ Thread.currentThread().getId() + " lines :" + num + " session_id:"//打印当前进程id
+ valueString.split("\t")[1]);//这行词的第二个字母
}
collector.ack(input);
// Thread.sleep(2000);
} catch (Exception e) {
collector.fail(input);
e.printStackTrace();
}
}
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields(""));//声明空即可
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Main方法:
package com.sxt.storm.grouping;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
public class Main {
/**
* @param args
*/
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new MySpout(), 1);//拓扑名,数据源,并行度
builder.setBolt("bolt", new MyBolt(), 2).allGrouping("spout");//两个spot并行 所有都分发
//builder.setBolt("bolt", new MyBolt(), 2).shuffleGrouping("spout");// shuffleGrouping其实就是随机往下游去发,不自觉的做到了负载均衡
//builder.setBolt("bolt", new MyBolt(), 2).fieldsGrouping("spout", new Fields("session_id")); // fieldsGrouping其实就是MapReduce里面理解的Shuffle,根据fields求hash来取模
//builder.setBolt("bolt", new MyBolt(), 2).globalGrouping("spout"); // 只往一个里面发,往taskId小的那个里面去发送
// builder.setBolt("bolt", new MyBolt(), 2).noneGrouping("spout"); // 等于shuffleGrouping
// Map conf = new HashMap();
// conf.put(Config.TOPOLOGY_WORKERS, 4);
Config conf = new Config();
conf.setDebug(false);
conf.setMessageTimeoutSecs(30);
if (args.length > 0) {
try {
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());//集群方式
} catch (AlreadyAliveException e) {
e.printStackTrace();
} catch (InvalidTopologyException e) {
e.printStackTrace();
}
} else {
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("mytopology", conf, builder.createTopology());// 本地模拟参数分别为名称,配置,构建拓扑结构。
}
}
}结果:
1. builder.setBolt("bolt", new MyBolt(), 2).allGrouping("spout");//两个spot并行 所有都分发

2. builder.setBolt("bolt", new MyBolt(), 2).shuffleGrouping("spout")其实就是随机往下游去发,不自觉的做到了负载均衡

3.builder.setBolt("bolt", new MyBolt(), 2).fieldsGrouping("spout", new Fields("session_id")); // fieldsGrouping其实就是MapReduce里面理解的Shuffle,根据fields求hash来取模,相同的名称的fields分发到一个bolt里面。

4.builder.setBolt("bolt", new MyBolt(), 2).globalGrouping("spout"); // 只往一个里面发,往taskId小的那个里面去发送

企业中常用的也就是这几个!!!