一、简介
我们前面的文章对Apache Storm 是一个开源的分布式、实时、可扩展、容错的计算系统的基本知识进行熟悉之后,我们通过Storm简单的例子把应用跟基础知识结合起来。
Storm的Topology是一个分布式实时计算应用,它通过Stream groupings把spouts和Bolts串联起来组成了流数据处理结构,Topologys在集群中一直运行,直到kill(storm kill topology-name [-w wait-time-secs]) 拓扑时扑才会结束运行。
拓扑运行模式:本地模式和分布式模式。
二、单词统计的例子

我们通过Spout读取文本,然后发送到第一个bolt对文本进行切割,然后在对切割好单词把相同的单词发送给第二个bolt同一个task来统计,这些过程可以利用多台服务器帮我们完成。
组件有spout、bolt、Stream groupings(shuffleGrouping、fieldsGrouping)、Topology
第一步:创建spout数据源
import java.util.Map;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
/**
* 数据源
* @author zhengcy
*
*/
@SuppressWarnings("serial")
public class SentenceSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private String[] sentences = {
"Apache Storm is a free and open source distributed realtime computation system",
"Storm makes it easy to reliably process unbounded streams of data",
"doing for realtime processing what Hadoop did for batch processing",
"Storm is simple", "can be used with any programming language",
"and is a lot of fun to use" };
private int index = 0;
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//定义输出字段描述
declarer.declare(new Fields("sentence"));
}
@SuppressWarnings("rawtypes")
public void open(Map config, TopologyContext context,SpoutOutputCollector collector) {
this.collector = collector;
}
public void nextTuple() {
if(index >= sentences.length){
return;
}
//发送字符串
this.collector.emit(new Values(sentences[index]));
index++;
Utils.sleep(1);
}
}第二步:实现单词切割bolt
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
/**
* 切割句子
* @author zhengcy
*
*/
@SuppressWarnings("serial")
public class SplitSentenceBolt extends BaseBasicBolt {
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//定义了传到下一个bolt的字段描述
declarer.declare(new Fields("word"));
}
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String sentence = input.getStringByField("sentence");
String[] words = sentence.split(" ");
for (String word : words) {
//发送单词
collector.emit(new Values(word));
}
}
}第三步:对单词进行统计bolt
import java.util.HashMap;
import java.util.Map;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Tuple;
/**
* 统计单词
* @author zhengcy
*
*/
@SuppressWarnings("serial")
public class WordCountBolt extends BaseBasicBolt {
private Map<String, Long> counts = null;
@SuppressWarnings("rawtypes")
@Override
public void prepare(Map stormConf, TopologyContext context) {
this.counts = new HashMap<String, Long>();
}
@Override
public void cleanup() {
//拓扑结束执行
for (String key : counts.keySet()) {
System.out.println(key + " : " + this.counts.get(key));
}
}
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String word = input.getStringByField("word");
Long count = this.counts.get(word);
if (count == null) {
count = 0L;
}
count++;
this.counts.put(word, count);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
第四步:创建Topology拓扑
通过Stream groupings把spouts和Bolts串联起来组成了流数据处理,并设置spout和bolt处理的并行数。
拓扑运行模式:本地模式和分布式模式。
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
/**
* 单词统计拓扑
* @author zhengcy
*
*/
public class WordCountTopology {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new SentenceSpout(), 1);
builder.setBolt("split", new SplitSentenceBolt(), 2).shuffleGrouping("spout");
builder.setBolt("count", new WordCountBolt(), 2).fieldsGrouping("split", new Fields("word"));
Config conf = new Config();
conf.setDebug(false);
if (args != null && args.length > 0) {
// 集群模式
conf.setNumWorkers(2);
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
} else {
// 本地模式
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word-count", conf, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}
}
三、运行拓扑
1、本地模式
本地模式是我们用来本地开发调试的,不需要部署到storm集群就能运行,运行java的main函数就可以了
// 本地模式
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word-count", conf, builder.createTopology());

2、集群模式
把代码生成jar,放到服务器某个目录下,例如:/usr/local/storm,并/usr/local/storm/bin目录下运行storm命令提交拓扑。
>./storm jar ../stormTest.jar cn.storm.WordCountTopology WordCountTopolog
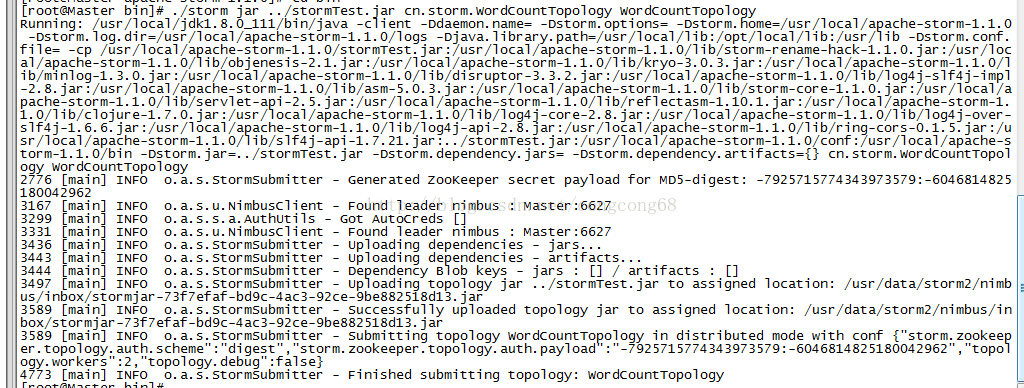
查看storm ui 是否提交成功拓扑

四、查看集群模式下拓扑的日志
我们查看运行起来的拓扑有没有报错
第一步:访问storm管理页面
例如:http://192.168.2.200:8081/index.html
访问storm管理页面并点击对应的拓扑,并查看拓扑分布到哪几台服务器
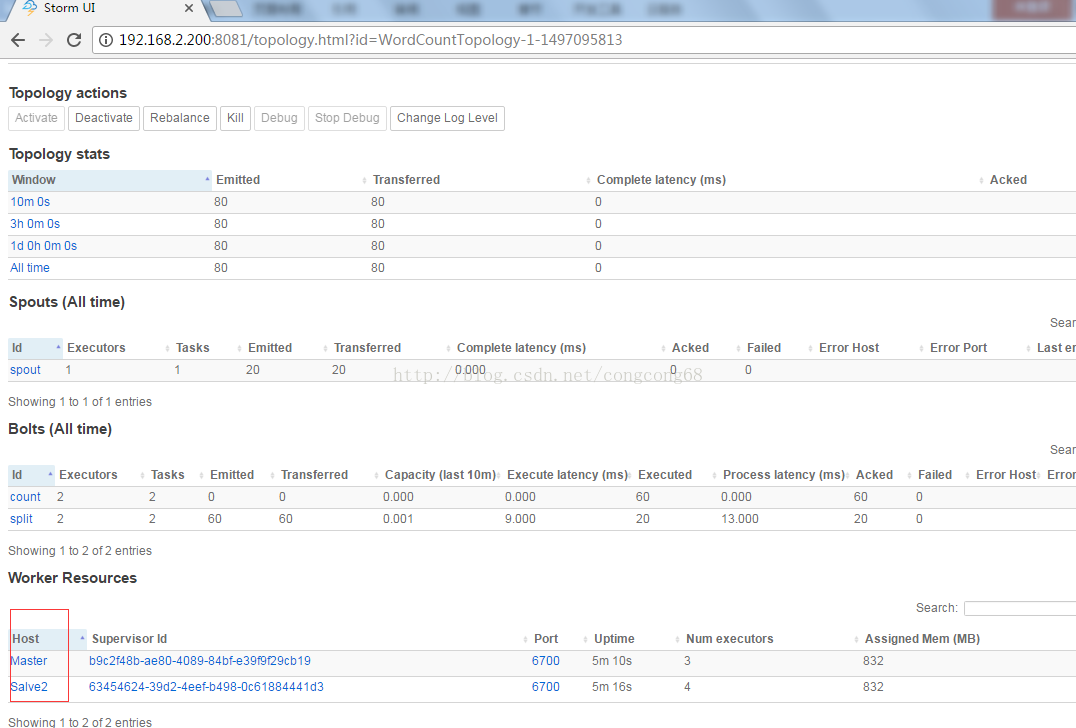
第二步:查看日志
tail -f logs/workers-artifacts/拓扑ID/端口/worker.log

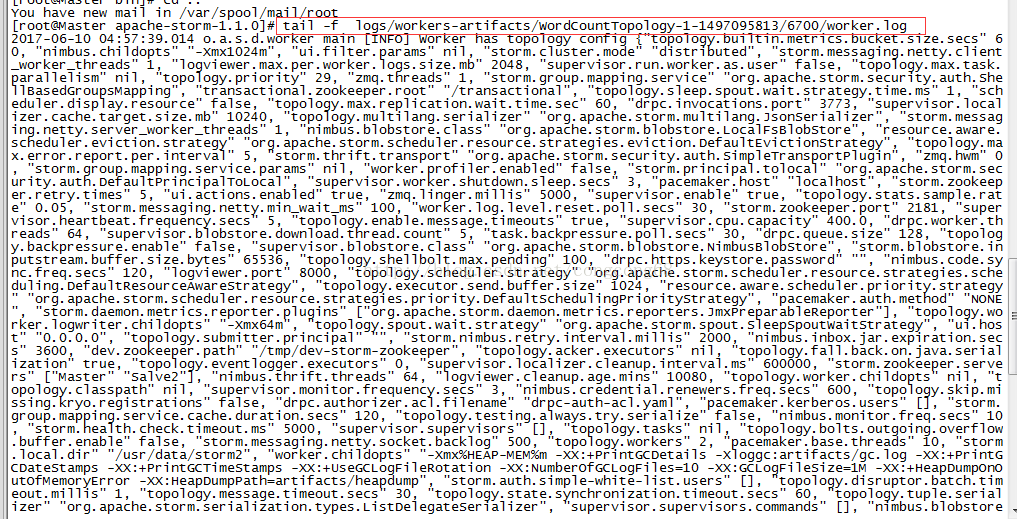
例如:
>tail -f logs/workers-artifacts/WordCountTopology-1-1497095813/6700/worker.log