1、Streaming or Batch 流式计算与批量计算:
1.1、基本概念:
Streaming Analytics 流式计算:顾名思义,就是对数据流进行处理,如使用流式分析引擎如 Storm,Flink 实时处理分析数据,应用较多的场景如实时大屏、实时报表。
Batch Analytics 批量计算:统一收集数据到存储到 Data Base 再到对数据进行批量处理,就是传统意义上使用类似于 MapReduce、Hive、Spark Batch等,对作业进行分析、处理、生成离线报表
流式计算与批量计算最本质的区别就是 数据的处理方式不同:
在流式计算中,数据按照数据流的方式处理,像一条河流一样,数据动态增加,且没有边界;持续的在处理数据。
在批量计算中,数据按照数据块的方式处理,像一个个快递包裹,一次性处理一批数据。
处理方式的不同表现在外观上体现在两种模式处理数据的 时效性 与 规模 上的不同:
流式计算的表现是有很高的时间效率:一条数据从进入流式系统到输出结果的时间间隔较短,可以实时获取最新的计算结果。
批量计算的表现是有很大的数据容量:直接从持久存储设备处理数据集或将数据集载入内存,可提供充足的处理资源。
1.2、Off-Line or Real-Time 离线计算与实时计算:
离线计算: 就是在计算开始前已知所有输入数据,输入数据不会产生变化,一般计算量级较大,计算时间也较长。是对历史数据的一种处理、提取,这类数据的特点就是数据量大,固定不变,基本上都采取批处理的方式进行计算。
实时计算: 输入数据是可以以序列化的方式一个个输入并进行处理的,也就是说在开始的时候并不需要知道所有的输入数据。运行时间短,计算量级相对较小,具有实时性。
实时计算 就一定是 流式计算 ? 离线计算 就一定是 批量计算 ?
其实,实时与离线是从 时效性的需求 角度来看的,流式与批量是从 数据处理的方式 角度来看的。
两者没有一一对应的关系,只是流式计算为实时计算提供了效率提升,离线计算允许批量计算更大的数据规模。
高频率计算的批量计算也可以达到实时计算的效果。
2、有关Storm的基础知识:
2.1、Storm的背景:
Twitter Storm是一个免费、开源的分布式实时计算系统,Storm对于流式计算的意义类似于Hadoop对于批处理的意义,Storm可以简单、高效、可靠地处理流数据,并支持多种编程语言;Storm框架可以方便地与数据库系统进行整合,从而开发出强大的实时计算系统。
2.2、Storm的特点:
Storm可用于许多领域中,如实时分析、在线机器学习、持续计算、远程RPC、数据提取加载转换等。Storm具有以下特点:
整合性: Storm可方便地与队列系统和数据库系统进行整合;
简易的API: Storm的API在使用上即简单又方便;
可扩展性: Storm的并行特性使其可以运行在分布式集群中;
容错性: Storm可自动进行故障节点的重启、任务的重新分配;
可靠的消息处理: Storm保证每个消息都能完整处理;
支持各种编程语言: Storm支持使用各种编程语言来定义任务;
快速部署: Storm可以快速进行部署和使用;
免费、开源: Storm是一款开源框架,可以免费使用。
2.3、Storm的主要术语:
Nimbus:即Storm的Master,负责资源分配和任务调度。一个Storm集群只有一个Nimbus。
Supervisor:即Storm的Slave,负责接收Nimbus分配的任务,管理所有Worker,一个Supervisor节点中包含多个Worker进程。
Worker:工作进程,每个工作进程中都有多个Task。
Task:任务,在 Storm 集群中每个 Spout 和 Bolt 都由若干个任务(tasks)来执行。每个任务都与一个执行线程相对应。
Streams:Storm将流数据Stream描述成一个无限的Tuple序列,这些Tuple序列会以分布式的方式并行地创建和处理。
Tuple:每个tuple是一堆值,每个值有一个名字,并且每个值可以是任何类型;Tuple本来应该是一个Key-Value的Map,由于各个组件间传递的tuple的字段名称已经事先定义好了,所以Tuple只需要按序填入各个Value,所以就是一个Value List(值列表)。
Spout:Storm认为每个Stream都有一个源头,并把这个源头抽象为Spout;通常Spout会从外部数据源(队列、数据库等)读取数据,然后封装成Tuple形式,发送到Stream中。Spout是一个主动的角色,在接口内部有个nextTuple函数,Storm框架会不停的调用该函数。
Bolt:Storm将Streams的状态转换过程抽象为Bolt。Bolt即可以处理Tuple,也可以将处理后的Tuple作为新的Streams发送给其他Bolt;Bolt可以执行过滤、函数操作、Join、操作数据库等任何操作;Bolt是一个被动的角色,其接口中有一个execute(Tuple input)方法,在接收到消息之后会调用此函数,用户可以在此方法中执行自己的处理逻辑。
Topology:Storm将Spouts和Bolts组成的网络抽象成Topology,它可以被提交到Storm集群执行。Topology可视为流转换图,图中节点是一个Spout或Bolt,边则表示Bolt订阅了哪个Stream。当Spout或者Bolt发送元组时,它会把元组发送到每个订阅了该Stream的Bolt上进行处理;Topology里面的每个处理组件(Spout或Bolt)都包含处理逻辑, 而组件之间的连接则表示数据流动的方向;Topology里面的每一个组件都是并行运行的;在Topology里面可以指定每个组件的并行度, Storm会在集群里面按照并行度分配线程来同时计算;在Topology的具体实现上,Storm中的Topology定义仅仅是一些Thrift结构体(二进制高性能的通信中间件),支持各种编程语言进行定义。
Stream Groupings:Storm中的Stream Groupings告知Topology如何在组件间(如Spout和Bolt之间,或者不同的Bolt之间)进行Tuple的传送。每一个Spout和Bolt都可以有多个分布式任务,一个任务在什么时候、以什么方式发送Tuple就是由Stream Groupings来决定的。
2.4、Storm的架构设计与工作流程:
2.4.1、Storm的整体结构:

Storm集群采用“Master—Worker”的节点方式:
Master节点运行名为“Nimbus”的后台程序:负责在集群范围内分发代码、为Worker分配任务和监测故障。
Worker节点运行名为“Supervisor”的后台程序:负责监听分配给它所在机器的工作。
即根据Nimbus分配的任务来决定启动或停止Worker进程,在一个Worker节点上同时运行若干个Worker进程。
Storm使用 Zookeeper 作为分布式协调组件,负责Nimbus和多个Supervisor之间的所有协调工作。借助于Zookeeper,若Nimbus进程或Supervisor进程意外终止,重启时也能读取、恢复之前的状态并继续工作,使得Storm极其稳定。
2.4.2、向 Supervisor 的深处进发:

Worker:每个worker进程都属于一个特定的Topology,每个Supervisor节点的Worker可以有多个,每个Worker对Topology中的每个组件(Spout或 Bolt)运行一个或者多个Executor线程来提供task的运行服务。
Executor:Executor是产生于Worker进程内部的线程,会执行同一个组件的一个或者多个Task。
Task:实际的数据处理由Task完成,在Topology的生命周期中,每个组件的Task数目是不会发生变化的,而Executor的数目却不一定。Executor数目小于等于Task的数目,默认情况下,二者是相等的。
2.4.3、Storm的工作流程:
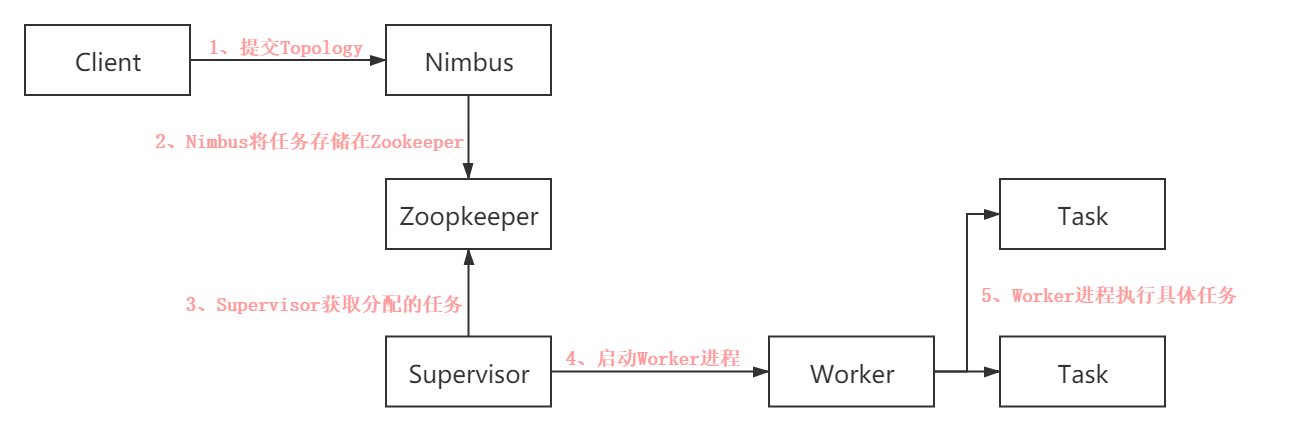
所有Topology任务的提交必须在Storm客户端节点上进行,提交后由Nimbus节点分配给其他Supervisor节点进行处理; Nimbus节点首先将提交的Topology进行分片,分成一个个Task,分配给相应的Supervisor, 并将Task和Supervisor相关的信息提交到Zookeeper集群上; Supervisor会去Zookeeper集群上认领自己的Task,通知自己的Worker进程进行Task的处理。 说明: 在提交了一个Topology之后,Storm就会创建Spout/Bolt实例并进行序列化。 之后,将序列化的组件发送给所有的任务所在的机器(即Supervisor节点),在每一个任务上反序列化组件。
3、Storm的安装:
相信你在学到这个知识点之前已经安装配置了CentOS、Java JDK、Zookeeper 这些必要的组件。
如果没有安装好这些组件的同学也没关系,再不济你总有个 CentOS 7.x 的虚拟机配置吧。
我用的版本是 Java JDK-1.8.0 、Zookeeper 3.4.6 、CentOS 7 ,目标是安装 Storm1.2.3 。
3.1、安装Java JDK-1.8.0(已有JDK同学可以跳过这一步)
(确保要有网络连接)在虚拟机中,打开Shell窗格:
sudo yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel
通过上述命令安装 OpenJDK,默认安装位置为 /usr/lib/jvm/java-1.8.0-openjdk。
OpenJDK 安装后就可以直接使用 java、javac 等命令了。
配置一下 JAVA_HOME 环境变量:
vim ~/.bashrc
在文件最后面添加如下单独一行(指向JDK的安装位置),并保存:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
接着还需要让该环境变量生效,执行如下代码:
source ~/.bashrc
设置好后我们来检验一下是否设置正确:
java -version
如果设置正确的话,java -version会输出 java 的版本信息。这样,Storm所需的Java运行环境就安装好了。
3.2 安装Zookeeper(已有Zookeeper同学可以跳过这一步)
选择安装 zookeeper 稳定版(3.4.6):
下载地址:Zookeeper安装地址1 或 Zookeeper安装地址2
下载方式:打开网页,点击 Projects 下的 “zookeeper-3.4.6.tar.gz” 进行下载
传输方式:可以在虚拟机直接下载至Downloads文件夹下,也可以在Windows端下载好压缩文件用X Shell传输。
下载后执行如下命令进行安装 zookeeper:
sudo tar -zxf ~/Downloads/zookeeper-3.4.6.tar.gz -C /usr/local
cd /usr/local
sudo mv zookeeper-3.4.6 zookeeper
sudo chown -R hadoop ./zookeeper
最后一步操作是赋予权限,hadoop是虚拟机用户名,安装虚拟机时会配置一个hadoop用户拥有root权限。
接着执行如下命令进行zookeeper配置:
cd /usr/local/zookeeper
mkdir tmp
cp ./conf/zoo_sample.cfg ./conf/zoo.cfg
vim ./conf/zoo.cfg
将当中的 dataDir=/tmp/zookeeper 更改为
dataDir=/usr/local/zookeeper/tmp
启动Zookeeper:
./bin/zkServer.sh start
若成功显示 Starting zookeeper … STARTED 则启动成功。
3.2 安装Storm(单机模式)
下载地址:Storm-1.2.3下载地址;
下载后执行如下命令进行安装Storm:
sudo tar -zxf ~/Downloads/apache-storm-1.2.3.tar.gz -C /usr/local
cd /usr/local
sudo mv apache-storm-1.2.3 storm
sudo chown -R hadoop ./storm
接着执行如下命令进行Storm配置:
cd /usr/local/storm
vim ./conf/storm.yaml
修改其中的 storm.zookeeper.servers 和 nimbus.host 两个配置项,
因为我们配置的为主机模式的Storm,即 取消掉注释 且都 修改值为主机名,亦可以为主机端口号,如下所示。
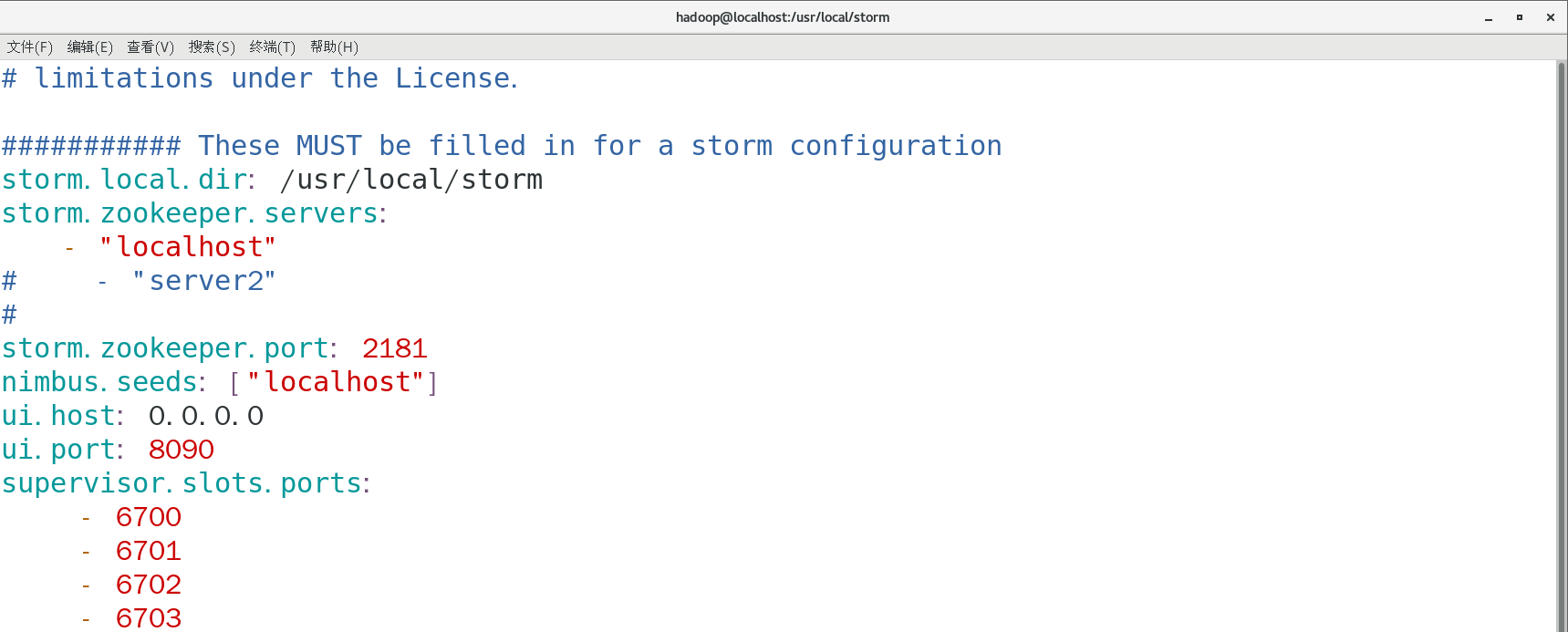
添加主机名的ip映射:
sudo vim /etc/hosts
添加一行(主机号+主机名):
127.0.0.1 localhost

简单配置后就可以启动 Storm 了。执行如下命令启动 nimbus 后台进程:
cd /usr/local/storm
./bin/storm nimbus &
若启动成功则显示如下图内容:
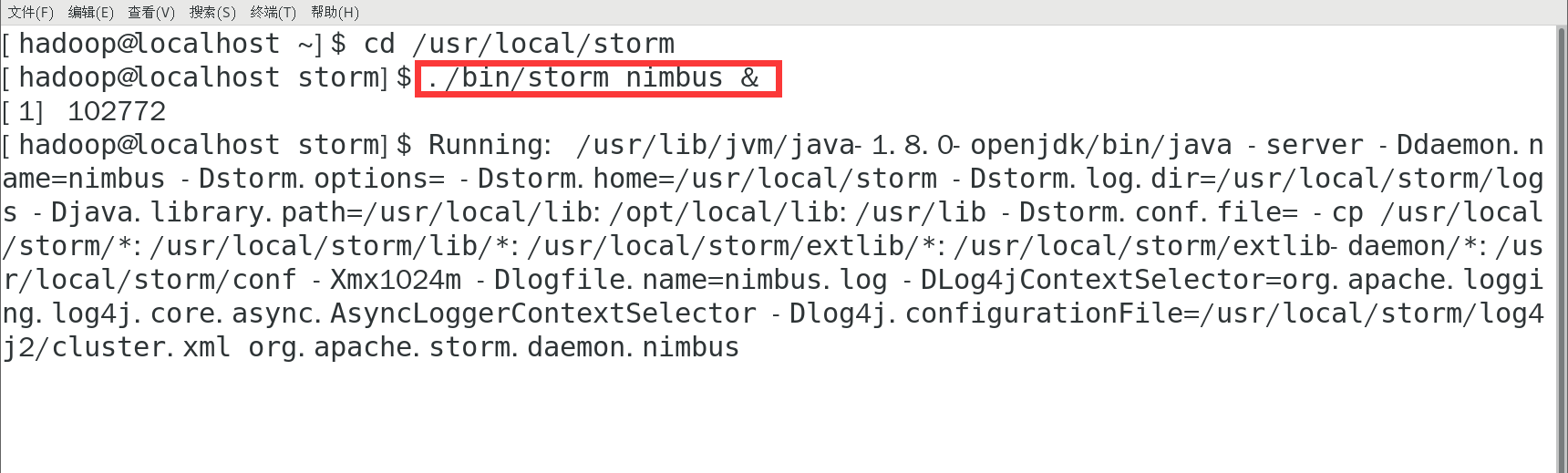
启动 nimbus 后,终端被该进程占用了,不能再继续执行其他命令了。
因此我们需要另外开启一个终端,然后执行如下命令启动 supervisor 后台进程:
/usr/local/storm/bin/storm supervisor

同样的,启动 supervisor 后,我们还需要开启另外的终端才能执行其他命令。
另外,我们可以使用 jps 命令 检查是否成功启动,若成功启动会显示 nimbus、supervisor、QuorumPeeMain 。
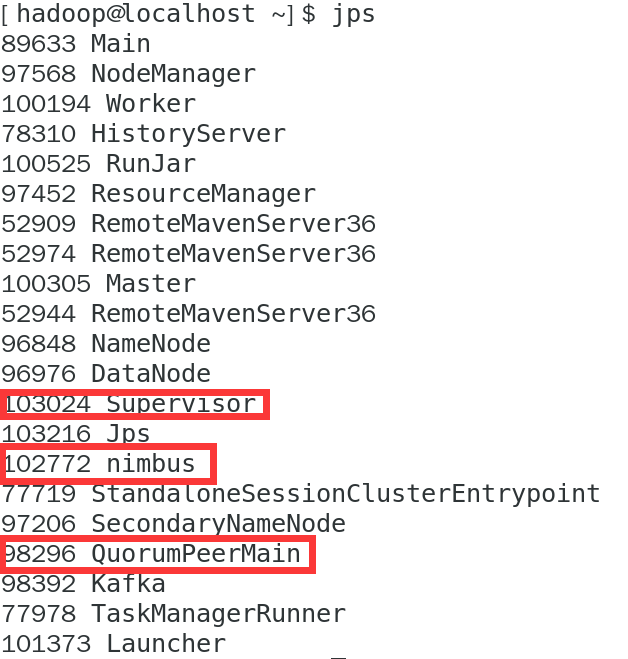
至此,Storm(单机)的安装配置全部完成。