tensorflow实现线性回归例子
一、环境
python3.5版本、pycharm2020、TensorFlow1.14.1
(关于pycharm版本没有什么关系,TensorFlow的版本最好是1.几版本,否则可能存在运行不了的情况)
二、要求和实现
主要描述tensorflow实现线性回归的流程
三、实现流程
线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。表达形式为y = w’x+e,e为误差服从均值为0的正态分布。
在建模的时候一般需要绘制散点图。
用TensorFlow实验线性回归的话,首先,我们需要样本数据 - train_x,train_y、随机生成变量w,b。接着可以创建线性模型 y=wx+b。我们还需要创建损失函数cost,再对函数用梯度下降算法优化损失函数。完成之后,创建一个session会话
并对变量进行初始化,开始迭代训练。还可以计算模型在数据集上的损失、最终的Loss。最后画出拟合曲线,更好的进行观察。
四、代码详解
import tensorflow as tf
import numpy
import matplotlib.pyplot as plt
rng = numpy.random
# Parameters
learning_rate = 0.01#设置梯度下降算法的学习率,一般为0~1之间比较小的值
training_epochs = 1000 #设置迭代次数
display_step = 50 #每迭代100次输出一次loss
# Training Data
#训练数据,生成生成样本数据train_x,train_y。asarray可以将元组,列表,元组列表,列表元组转化成ndarray对象。
train_X = numpy.asarray([3.3,4.4,5.5,6.71,6.93,4.168,9.779,6.182,7.59,2.167,
7.042,10.791,5.313,7.997,5.654,9.27,3.1])
train_Y = numpy.asarray([1.7,2.76,2.09,3.19,1.694,1.573,3.366,2.596,2.53,1.221,
2.827,3.465,1.65,2.904,2.42,2.94,1.3])
n_samples = train_X.shape[0] #获取训练数据的大小
# tf Graph Input
#定义输入变量,变量只有一个特征
X = tf.placeholder("float")
Y = tf.placeholder("float")
# Set model weights
W = tf.Variable(rng.randn(), name="weight") #定义权重
b = tf.Variable(rng.randn(), name="bias") #定义偏置
# Construct a linear model
pred = tf.add(tf.multiply(X, W), b) #计算预测值,y=wx+b公式
# Mean squared error
#定义损失函数
cost = tf.reduce_sum(tf.pow(pred-Y, 2))/(2*n_samples)
# Gradient descent
#使用梯度下降算法来优化损失函数
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
# Initialize the variables (i.e. assign their default value)
#开始创建一个会话
init = tf.global_variables_initializer()# 初始化所有变量
# Start training
with tf.Session() as sess:# 开启会话进行训练
sess.run(init)
# Fit all training data #迭代训练
for epoch in range(training_epochs):
for (x, y) in zip(train_X, train_Y):
sess.run(optimizer, feed_dict={X: x, Y: y})
#Display logs per epoch step
if (epoch+1) % display_step == 0:
#计算模型在数据集上的损失
c = sess.run(cost, feed_dict={X: train_X, Y:train_Y})
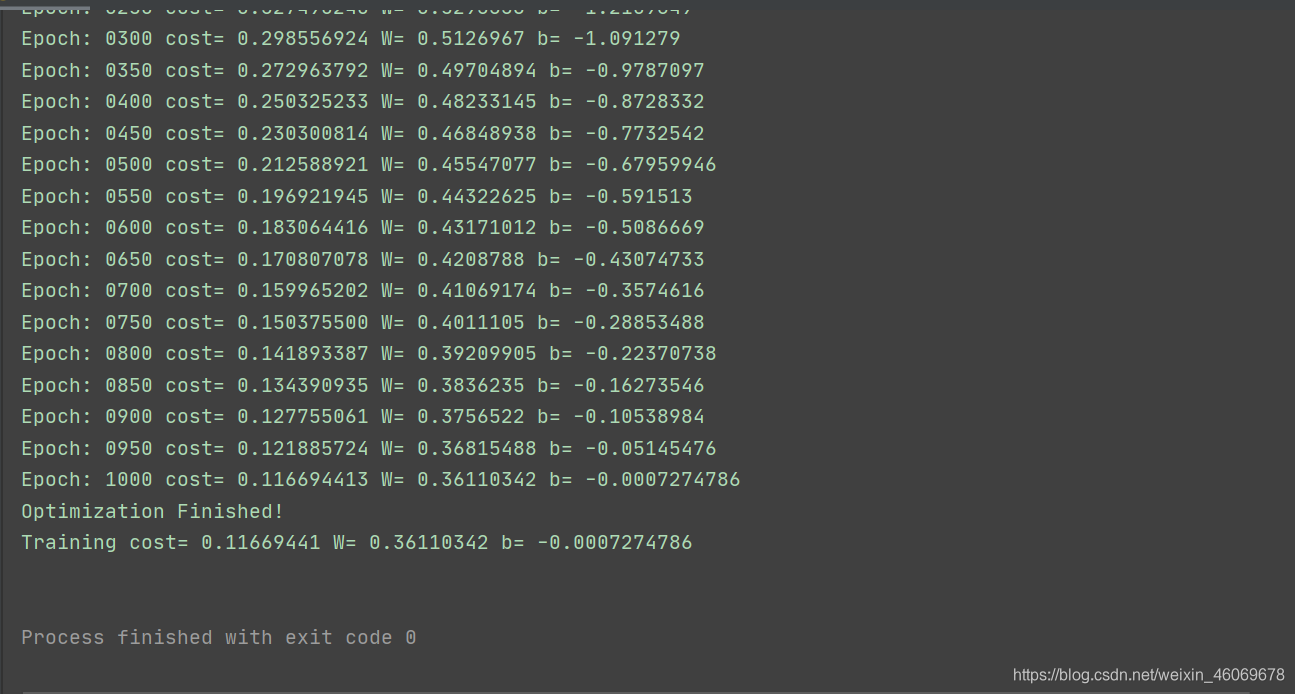
print ("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(c), \
"W=", sess.run(W), "b=", sess.run(b))
print ("Optimization Finished!")
#计算最终的Loss
training_cost = sess.run(cost, feed_dict={X: train_X, Y: train_Y})
print ("Training cost=", training_cost, "W=", sess.run(W), "b=", sess.run(b), '\n')
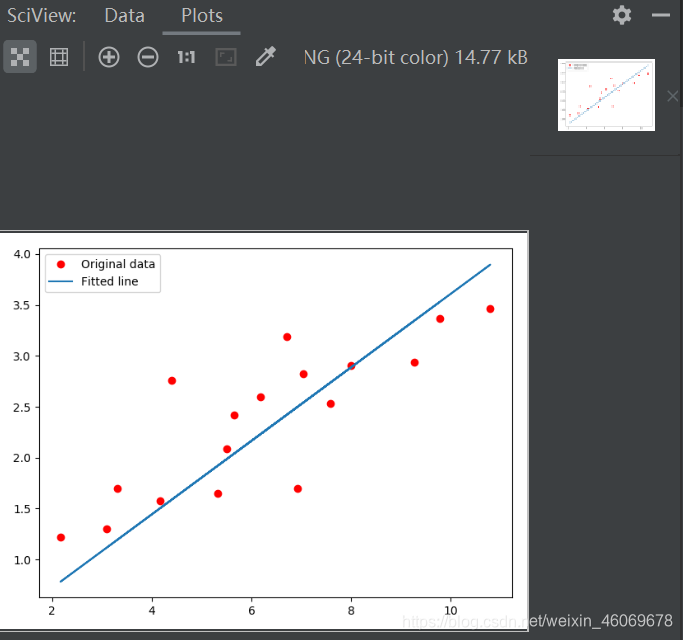
#Graphic display#绘图
plt.plot(train_X, train_Y, 'ro', label='Original data')
plt.plot(train_X, sess.run(W) * train_X + sess.run(b), label='Fitted line')
plt.legend()
plt.show()
五、结果
制作人:只识闲人不识君
日期:2020.05.20