目录
Chapter 2: The term vocabulary and postings lists
In fact, this chapter is an detailed description of Inverted index introduced in the first chapter. At first, the author listed the specific steps to constract inverted index:

The logical structure of this chapter is clear: The first section explains how to select document unit and how to convert the document from byte streams to character streams (step 1); The second section illustrates how to tokenize the document and the advantages and disadvantages of dropping common terms(stop Word). These corresponding steps are step two. In addition, the second section also explains several operations to normalize tokens (including mapping, Stemming, and Lemmatization), which helps the system group several different tokens into an equivalence class. Section 3 Introduces skip pointers to speed up posting merges. Finally, section 4 shows two methods to “pharse queries”, which compensate for the shortcomings at the end of the first chapter.
First of all, I list the definitions of the main terms in this chapter here: (The definitions summarized by me instead of being clearly defined in the book are marked with **.)
- Documen unit: **The minimum index uni. In previous chapters, the default document unit is a document.
- Token: **The output of Tokenization. It is a word after document Tokenization.
- Term: **After token normalization, we get token sets with different glyphs but same meanings.
- Stop word: Extremely common words that would appear to be of little value in helping select documents matching a user need.
- Token normalization: The process of canonicalizing tokens so that matches normalization occur despite superfificial differences in the character sequences of the tokens.
- Stemming: **Use some matching rules to restore a variety of deformed words to their original lexicon.
- Lemmatization: **Put words with the same meaning but different parts of speech into an equivalence class.
- Skip list: **Based on Posting with some jump Pointers to provide speed improvement for the merge operation.
- Phrase query: **Use phrases to query and expect to return the words searched in the document to appear consecutively as phrases.
- Biword indexes: **A method of phrase query that treats two consecutive words in a phrase as a term and indexes it.
- Positional indexes: **Another method to “query phrases”. By adding the word position information in the Posting, we determine whether the two words constitute a phrase.
The following is a more detailed summary and reflection of this chapter. Since the content of this chapter is relatively scattered, I will summarize by taking the sections in the book as units:
The first section:
Byte stream to character stream conversion: Documents on a Web server typically take the form of a byte stream. To construct inverted index, we first need to convert the document from byte stream to character stream. The biggest problems are two: how to determine the encoding of the document and how to do some pre-conversion according to the document type. For the first question, This can be regarded as a machine learning classifification problem, but is, handled by heuristic methods, user selection, or using provided the document metadata. Once the encoding is determined, We decode the byte sequence to a Character Sequence. For the second question, we can also use machine learning methods to determine the type of document (such as XML, JAVA, HTML) and then perform the corresponding conversion according to the document type (for example, the escape character “&” in XML should be converted to “&”). Search engines should make conversion rules for common document types in advance. In addition, some literals represented by nonlinear character streams should be reversed according to the order in which they are encoded. For example, Arabic is used from right to left, so in some old codes, we need to invert it. There are languages whose representations are even two-dimensional (see below), and for such languages there are special strategies to be developed according to their characteristics.
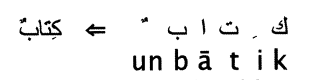
Document unit selection: Previously, we chose a document as the index unit by default, but in some special cases, we can change the document unit flexibly. Generally speaking, the smaller the index unit is, the higher the accuracy rate is, and the lower the recall rate is.
The second section:
Tokenization: After the character stream is obtained, the character stream needs to be segmented into Token stream next. There are a number of ways to split, including directly by Spaces, by quotes, and by hyphenation. In English, quotation marks and hyphenation often have special meanings, so the separation may cause some ambiguity. Divide “It’s my bag.” into “It s my bag.” But the latter is obiviously an ill-formed sentence. So in this step, we need to tokenize based on the language features.
Dropping common terms(stop words): Within an expression, there are usually words that constrict the expression, making it more grammatical. However, such words have no practical meaning and frequently occur. So when indexing documents, we can drop these words. However, with the introduction of some theoretical technologies, the additional cost of including stop words is not that high-either in terms of index size or in terms of query processing time. Therefore, the stop words table in IR system is becoming smaller and smaller, and some systems do not even use stop tables any more.
Term normalization: Once gotten tokens of documentation, we can not use token as Term directly because many tokens tend to have the same meaning, and searchers prefer that the IR system treat token with the same meaning as an equivalence class. Therefore, the purpose of this step is to establish token equivalence classes, each of which corresponds to a term. The author introduces two approaches here, namely, establishing mapping rules and maintaining relations between unnormalized tokens. One example of mapping rules is droping hyphenation, “foot-ball” and “football” will be classified into an equivalence class. The other method for establishing equivalence class is to maintain the association relationship between multiple nonnormalized entries. This approach can be further extended to manual construction of the synonym glossary, such as classifying car and automobile as synonyms. The usual way is to index unnormalized tokens and to maintain a query expansion list of multiple vocabulary entries to consider for a certain query term. A query term is then effectively a combination of several posting lists.
The third section:
The author introduces a posting update with jump Pointers in this section. The jump pointer is a shortcut in posting. Before we had to traverse the whole posting to merge posting, but now we can skip the middle part directly through the jump pointer. Take the picture in the book for example:
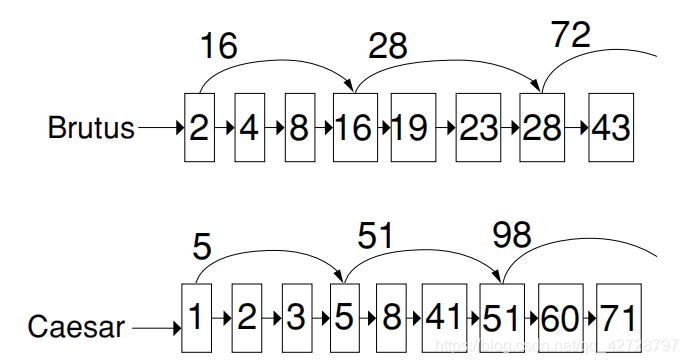
As can be seen, in the Posting of Brutus, there is a jump pointer between 2 and 16. Under certain conditions, the pointer can jump directly from 2 to 16, which saves the time of traversing the middle 4 and 8. So under what circumstances can it jump? The answer is that when the pointer target item is still smaller than another posting comparison item, you can use the pointer to jump directly. Assume that at some point, the current terms in the two tables are 16 and 41, respectively. In this case, the terms of Brutus are less than the expression of Caesar, so it should be moved back. It also finds a jump pointer for the current item, and the jump target item(28) is still smaller than Caesar’s current item(41), so it can choose to jump! The algorithm is represented by pseudocode as follows (source code from the book) :

Now there’s one last question: Where should I set the jump pointer? The answer is that there are no fixed placement requirements. It can be imagined that if the jump pointer appears frequently, the advantage is more jump opportunities, while the disadvantage is that the jump distance is low and more processing time is required. In practice, there is a simple heuristic strategy: place pointers evenly at every , where P is the length of the posting. This strategy is simple and effective, but there is still room for improvement.
The fourth section:
Biword Indexes: An implementation of phrase query. For example, searching “Wuhan University Library” will automatically treat adjacent entries as a term, so the actual index target is: “Wuhan University” AND “University Library”. Of course, there are also problems in this way. For example, if there are both “Peking University Library” and “Wuhan University” in a document, the document will also be retrieved. One way to improve is to combine more token into a term, called the phrase Index. Practice has proved that the chance of a false-positive match on indexed phrases of length three or more becomes very small indeed. The disadvantage of this strategy is that the maintenance cost increases rapidly because the number of possible combinations increases.
Positional Indexes: Another way to implement Positional queries. It is a further improvement for Posting by adding information about the distribution of terms in the document. When location information is available, we can determine whether it is the same phrase by calculating the difference of location. The pseudocode is as follows (from the book) :

Combination schemes: This is a Combination of the above two methods. First, let’s analyze the advantages of each approach. Biword Indexes have advantage for phrases where the individual words are common but the merged phrase is comparatively rare. Take “The Who” for example, “The” and “Who” are both common, so using positional indexes will increase posting length. While using Biword Indexes results in a short posting because ‘The Who’ is a rare combination. So we should use a phrase index in this case.