文章目录
一、线性表查找
1、顺序查找
这里顺序查找比较简单,顺序查找与底层结构无关。(可以是顺序存储,也可时链式存储)
这里为了方便,使用数组来展示。
思路:逐个比较,如果找到,返回数据或索引,如果全部比较完毕,还找到,返回null.
在各个结点查找概率相同的情况下。默认查询长度为一半。所以时间复杂度为 T(n) = O(n)。
代码实现:
package com.gwz.datastructure.search;
/**
* 顺序查找,使用顺序存储结构
* 时间复杂度 T(n) = O(n)
* 空间复杂度 S(n) = O(1)
*/
public class SortSearch {
public static void main(String[] args) {
int[] arrNums = {12,3,4,67,267,2,721};
int num = 67;
int index = -1;
index = sortSearch(arrNums,num);
if (index != -1) {
System.out.println("所要查找的数-》" + num + "的下标为-》" + index);
} else {
System.out.println("此数不存在!");
}
}
public static int sortSearch(int[] arrNums, int num) {
for (int i = 0; i < arrNums.length; i++) {
if (num == arrNums[i]) {
return i;
}
}
return -1;
}
}
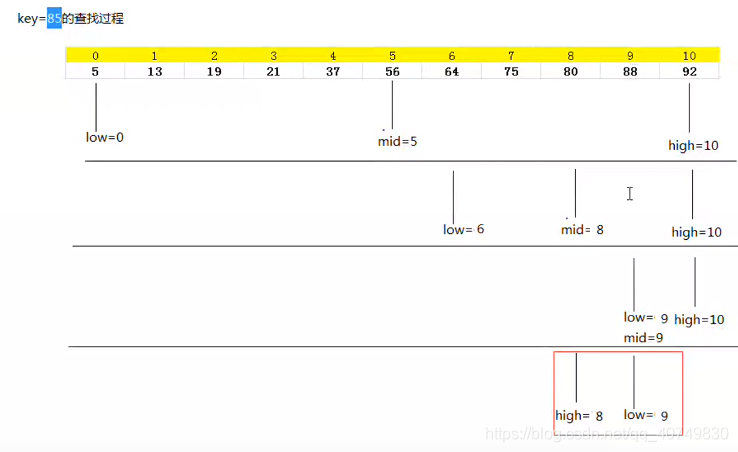
2、折半查找
使用折半(二分)查找的条件:
1、首先是顺序存储结构,
2、排列是有序的。
思路:
代码实现:
package com.gwz.datastructure.search;
/**
* 二分查找,使用顺序存储结构
*/
public class BinarySearch {
public static void main(String[] args) {
int[] arrNums = {1,2,3,4,5,6,7,78,89};
int num = 5;
int index = -1;
index = binarySearch2(arrNums,num);
if (index != -1) {
System.out.println("所要查找的数-》" + num + "的下标为-》" + index);
} else {
System.out.println("此数不存在!");
}
}
/**
* 不是使用递归
* 时间复杂度 T(n) = (log2^n)
* 空间复杂度 S(n) = O(1)
* @param arrNums
* @param num
* @return
*/
public static int binarySearch(int[] arrNums, int num) {
// 定义 low ,high
int low = 0;
int high = arrNums.length - 1;
int mid = (low + high) / 2;
while (low <= high) {
mid = (low + high) / 2;
if (num == arrNums[mid]) return mid;
else if (num < arrNums[mid])
high = mid - 1;
else low = mid + 1;
}
return -1;
}
/**
* 使用递归
* 时间复杂度 T(n) = (log2^n)
* 空间复杂度 S(n) = O(log2^n)
* @return
*/
public static int binarySearch2(int[] arrNums, int num) {
int low = 0;
int high = arrNums.length - 1;
return binarySearch3(arrNums, num, low, high);
}
private static int binarySearch3(int[] arrNums, int num, int low, int high) {
if (low <= high) {
int mid = (low + high) / 2;
if (num == arrNums[mid]) {
return mid;
} else if(num < arrNums[mid]){
return binarySearch3(arrNums, num, low, mid - 1 );
} else {
return binarySearch3(arrNums, num, mid + 1, high);
}
}else {
return -1;
}
}
}
二、查找树
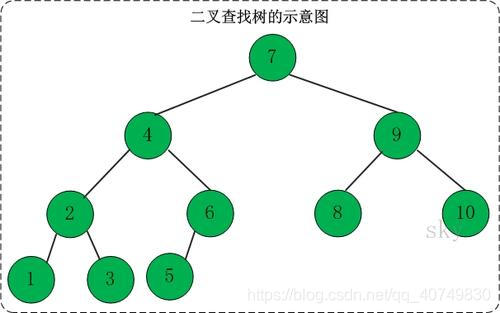
1、二叉查找、搜索、排序树(binary search/ sort tree)
特点:一颗空树,或者具有以下性质的二叉树
-
如果左子树不为空,则左子树上所有结点的值均小于根结点的值
-
如果右子树不为空,则右子树上所有结点的值均大于根结点的值
-
它的左、右子树也分别为二叉排序树。
-
对二叉排序树进行中序遍历,会得到一个递增序列。
2、平衡二叉树(Self-balanceing binary search tree)
是自平衡二叉查找树,又被称为AVL树(有别于AVL算法)
特点:一颗空树,或者具有以下性质的二叉树
-
首先具有二叉查找树的性质
-
其次它的左子树、与右子树的高度差(平衡因子)的绝对值不不超过1.
-
左、右子树也是平衡二叉树。
-
总的来说,就是每个结点的左、右、子树高度差为只能为-1、0、1的二叉排序树。
平衡二叉树的出现是为了减少二叉排序树的层次,以提高查找效率。
注意:平衡二叉树的常用实现方法有AVL、红黑树、替罪羊树、Treap、伸展树等。具体有关算法这里不一一探索,有兴趣的小伙伴可以去研究一下。绝对烧脑。
3、红黑树
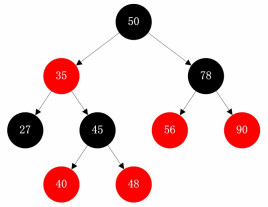
红黑树是一种平衡二叉树、红黑树使用比较广泛,这里就总结一下。
java集合中的TreeSet 和 TreeMap, C++ STL 中的set 、map 以及linux虚拟内存管理,都是通过红黑树去实现的。值得一学。
特点:
- 每个结点或者是黑色,或者是红色。
- 根结点是黑色。
- 每个叶子结点是黑色,这里说的叶子结点是指为Null的叶子结点。
- 如果一个叶子结点是红色的,则它的子结点必须是黑色的。
- 从一个结点到该结点的子孙结点的所有路径上包含相同的数量的黑结点。
4、B树、B+树、B*树
有兴趣的小伙伴可以了解一下。这些结构有它们自己的特殊性,使用空间来换取时间。
数据库索引就是采用B+树实现的。
三、哈希表查找
hashtable:散列表。

1、结构、特点
特点:一个字就是快。存储结构可以由很多种
使用最多的就是:顺序表 + 链表。
主结构:顺序表,每个顺序表的结点可以单独引用一个链表。
2、哈希表如何添加数据?
-
计算哈希码(调用hashcode(),结果是一个int值,整数哈希码取自身即可。
-
计算哈希表中存储的位置 y = k(x) % key
x:哈希码,k(x) 函数 y:在哈希表中的存储位置
-
存入哈希表
- 一次存入成功
- 多次成功(出现冲突,调用equals方法和对应链表上的元素比较。比到最后,返回结果都是false,创建新结点,存入数据,加入链表末尾。
- 不添加,出现冲突,一次,或多次比较,返回都是true,表面重复,不添加。
结论:哈希表添加数据只需三步。
唯一、无序、
3、hashCode()和equals()方法
hashCode():计算哈希码,是一个整数,可以通过哈希码,计算出元素在哈希表中存储的位置。
equals():添加数据出现冲突时,需要调用equals方法进行比较。判断是否相同,总是相同,不添加,查询是也需要调用equals比较,判断是否相同。
4、hashCode的计算
不同类型的哈希码,有不同的计算规则,可以参考源码计算规则。
5、如何减少哈希冲突
1、哈希表的长度和表中记录数,简单来说就是控制装填因子
装填因子(尽量控制在0.5) = 需要存储的数据个数 / 哈希表长度。
2、哈希函数的选择:直接定地址法、平凡取中法、折叠法、除留取余方法、
3、处理冲突的方法: 链地址法、开放地址法、再散列法、
四、java中的查找树和哈希表
1、java中TreeSet和TreeMap 底层实现是红黑树。
TreeSet底层是TreeMap.
添加结点的过程,会通过旋转法,保证每次添加前后都是平衡树。
2、java中HashSet和HashMap底层使用了哈希表Hashtable
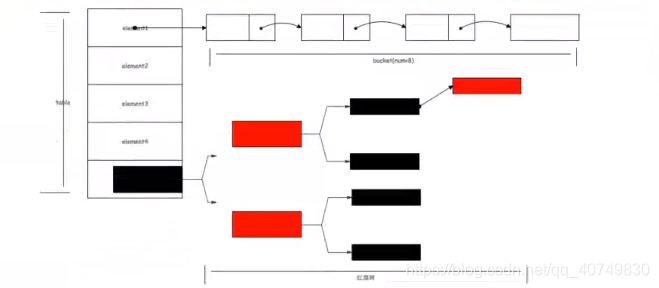
- HashSet的底层结构:HashSet底层采用HashMap,HashSet的元素作为HashMap的key,统一使用Object对象作为value.
- jdk8之后为了解决查询效率的问题。链表查询时间复杂度为O(n),红黑树为O(logn),不过链表变换成红黑树是否条件的,当冲突过多时,》8,就会转出成红黑树。