活体检测算法本周论文阅读小结
本周正式开始看活体检测方向的论文,之前两周完成了Head Pose的部署工作,后面主要负责做活体检测.本周的情况是阅读了三篇cvpr, 其中复现了2篇,实验结果还算满意,等待后续评估.
Learning Generalized Spoof Cues for Face Anti-spoofing
本文是百度的一篇活体检测的论文,利用的是异常检测的思想,通过学习所谓的cue map,利用metric learning的方法来实现活体检测.
论文的网络结构大致为:
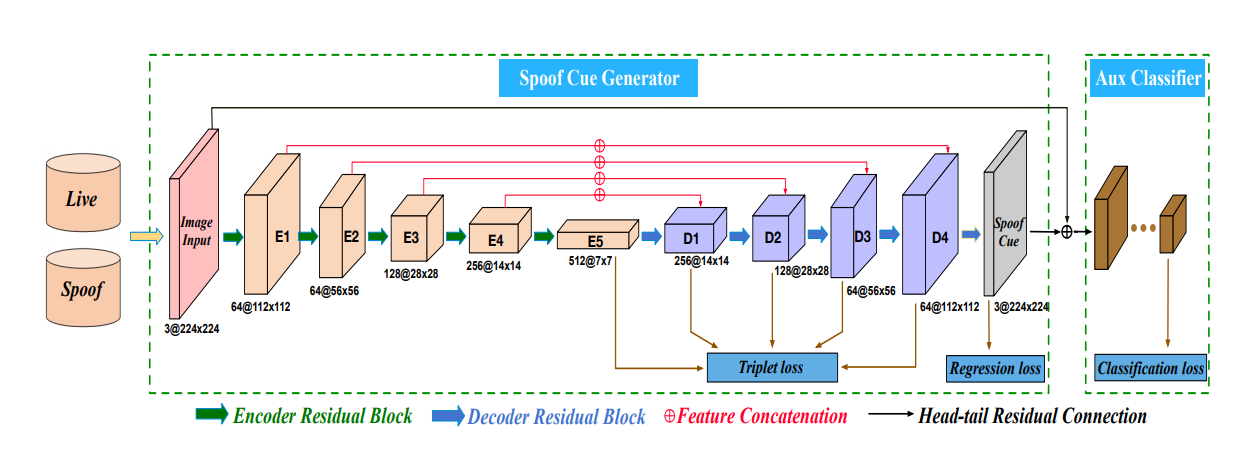
主干网为U-Net结构,其中Regression Loss需要将正常样本回归到0,而对异常样本则不管,这样做的依据是认为正常样本都有一个同一的域内中心,即为0,而异常样本的中心是不定的,所以计算回归loss的时候只计算正常样本的loss.
后面的分类loss是辅助loss,增强梯度效应,做正例和负例二分类.
文章比较出彩的是中间的Ttiplet Loss,一个batch的数据里有m个正样本和n个负样本,则按照(a,p,n)则可以组成n*n*m个三元组,计算三元组loss.这样可以使得类内紧凑,类间分散,这是典型的metric learning的内容.
triplet loss定义为:
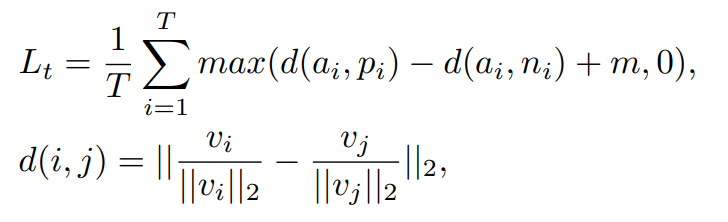
所以对上图中对应的层提取的特征做triplet loss,regression loss是对正样本回归到0,负样本不管,最后对提取出的cue map接一个mlp做分类.
最终训练完成即可根据Cue map的大小判定异常度,cue map大则认为更加异常(非活体).亦或是根据后面的分类器来判别.
主要复现代码(完整代码等整理好放到github里):
import torch
import torch.nn as nn
import torch.nn.functional as F
class TripletLoss(nn.Module):
def __init__(self,margin = 0.2):
super(TripletLoss,self).__init__()
self.margin = margin
def forward(self, f_anchor, f_positive, f_negative): # (-1,c)
f_anchor, f_positive, f_negative = renorm(f_anchor), renorm(f_positive), renorm(f_negative)
with torch.no_grad():
idx = hard_samples_mining(f_anchor, f_positive, f_negative, self.margin)
d_ap = torch.norm(f_anchor[idx] - f_positive[idx], dim = 1) # (-1,1)
d_an = torch.norm(f_anchor[idx] - f_negative[idx], dim = 1)
return torch.clamp(d_ap - d_an + self.margin,0).mean()
def hard_samples_mining(f_anchor,f_positive, f_negative, margin):
d_ap = torch.norm(f_anchor - f_positive, dim = 1)
d_an = torch.norm(f_anchor - f_negative, dim = 1)
idx = (d_ap - d_an) < margin
return idx
def renorm(x): # Important for training!
# renorm in batch axis to make sure every vector is in the range of [0,1]
# important !
return x.renorm(2,0,1e-5).mul(1e5)
class TotalLoss(nn.Module):
def __init__(self,margin = 0.2):
super(TotalLoss, self).__init__()
self.margin = margin
self.trip = TripletLoss(margin)
self.reg = nn.MSELoss()
self.cla = nn.CrossEntropyLoss()
def forward(self, regression, classification, feat, labels):
regression_anchor, regression_positive, regression_negative = regression
b,c,_,_ = regression_anchor.size()
classification_anchor, classification_positive, classification_negative = classification
feat_anchor, feat_positive, feat_negative = feat
reg_loss = self.reg(regression_negative[labels == 1], torch.zeros_like(regression_negative[labels == 1])) + self.reg(regression_anchor[labels == 0], torch.zeros_like(regression_anchor[labels == 0])) + self.reg(regression_positive[labels == 0], torch.zeros_like(regression_positive[labels == 0]))
cla_loss = self.cla(classification_anchor[labels==0], torch.tensor([1] * classification_anchor[labels==0].size(0), dtype = torch.long)) + \
self.cla(classification_anchor[labels==1], torch.tensor([0] * classification_anchor[labels==1].size(0), dtype = torch.long)) + \
self.cla(classification_positive[labels==0], torch.tensor([1] * classification_positive[labels==0].size(0), dtype = torch.long)) + \
self.cla(classification_positive[labels==1], torch.tensor([0] * classification_positive[labels==1].size(0), dtype = torch.long)) + \
self.cla(classification_negative[labels==0], torch.tensor([0] * classification_negative[labels==0].size(0), dtype = torch.long)) + \
self.cla(classification_negative[labels==1], torch.tensor([1] * classification_negative[labels==1].size(0), dtype = torch.long))
trip_loss = sum([self.trip(a,b,c) for a,b,c in zip(feat_anchor, feat_positive, feat_negative)])
return reg_loss + cla_loss + trip_loss
if __name__ == "__main__":
regression = [torch.randn(1,3,24,24), torch.randn(1,3,24,24), torch.randn(1,3,24,24)]
classification = [torch.randn(1,2), torch.randn(1,2), torch.randn(1,2)]
feat = [[torch.randn(1,16),torch.randn(1,16)],[torch.randn(1,16),torch.randn(1,16)],[torch.randn(1,16),torch.randn(1,16)]]
labels = torch.tensor([0],dtype = torch.long)
loss_fn = TotalLoss()
res = loss_fn(regression, classification, feat, labels)
Deep Anomaly Detection for Generalized Face Anti-spoofing
文章的贡献在于两点,一是设计了一种新的loss,称之为Triplet Focal Loss,融合了Triplet Loss和 Focal Loss,通过metric learning来使得学习到的特征之间类内紧凑,类间分散.二是从异常检测的角度看待人脸假体攻击的问题,(我感觉看问题的角度还是挺重要的),所以论文的方法分为few shot版本的和非few shot版本的,非few shot版本的就是直接针对特征训练个svm分类器,few shot版本的类似于knn吧感觉上.
文章的网络结构很简单:

就是一个简单的CNN结构,主要是loss和训练方式.
triplet loss应该是早些年做人脸相似度匹配的时候提出的loss,具体的形式为:
简单理解一下,就是在L越小的时候,理论上\(d(a,p)\)应该越小,同时\(d(a,n)\)应该越大,但是前者和后者的插值应满足在margin内,这样的话.理想情况就是anchor和正样本的距离足够小,和负样本的距离足够大,如果正负样本已经分隔的足够好了(大于margin),就没必要再去优化这一组了,着重去优化分隔的还不够好的三元组.但是,这样的loss可能并不容易优化,经验上Loss很容易一直维持在margin附近,所以后来对triplet loss的一个改进就是加一个softmax loss联合训练,而所谓的softmax loss也就是分类的损失交叉熵而已.
在本文中,作者的贡献是对triplet loss类似focal loss一样取了exp,则最终的损失就变成了:
前部分是正常的分类loss,后面是triplet loss,作者认为后者是对前者的正则化约束,能够保证特征之间的区分性,而非直接用分类损失去引导梯度.
这里要注意的是,如果在arxiv上找到的这篇paper,公式是错的(我上面写的是对的),后来我联系到了作者,更正了公式.
拿这个去train,就基本完事了.
选择pair的时候是先计算所有positive对应的anchor与所有negative样本的特征之间的距离,选择\(D(a,p) - D(a,n) < m\)的随机negative样本训练,这样可以保证能够继续被优化.loss一直下降.
要注意的是网络输出的是特征而非分类概率,如果是非few shot版本,则可以后面直接接个svm去训练,由于在神经网络训练阶段采用欧式距离将正负样本分开,所以这里使用对距离敏感的RBF核分类.
如果是few shot版本的,则可以直接根据上面的softmax来分类:
上式M表示训练集pair数,作者实验中只取了3,也就是只有三组,上式表示分类为正类的概率,父类概率是同样的.
Loss Function Code:
# By Aoru Xue. Time: 2020.6.16
import torch
import torch.nn as nn
import torch.nn.functional as F
class TripletLoss(nn.Module):
def __init__(self,margin = 0.2, sigma = 0.3):
super(TripletLoss,self).__init__()
self.margin = margin
self.sigma = sigma
def forward(self,f_anchor,f_positive, f_negative): # (-1,c)
d_ap = torch.norm(f_anchor - f_positive, dim = 1) / self.sigma # (-1,1)
d_an = torch.norm(f_anchor - f_negative, dim = 1) / self.sigma
return torch.clamp(torch.exp(d_ap) - torch.exp(d_an) + self.margin,0).sum()
class MetricSoftmaxLoss(nn.Module):
def __init__(self):
super(MetricSoftmaxLoss,self).__init__()
def forward(self,f_anchor,f_positive, f_negative):
d_ap = torch.norm(f_anchor - f_positive, dim = 1)
d_an = torch.norm(f_anchor - f_negative, dim = 1)
return -torch.log(torch.exp(d_an) / (torch.exp(d_an) + torch.exp(d_ap))).sum()
def hard_samples_mining(f_anchor,f_positive, f_negative, margin):
d_ap = torch.norm(f_anchor - f_positive, dim = 1)
d_an = torch.norm(f_anchor - f_negative, dim = 1)
idx = (d_ap - d_an) < margin
return idx
def renorm(x): # Important for training!
# renorm in batch axis to make sure every vector is in the range of [0,1]
# important !
return x.renorm(2,0,1e-5).mul(1e5)
class MetricLoss(nn.Module):
def __init__(self,margin = 0.2, sigma = 0.3, l = 1.):
super(MetricLoss, self).__init__()
self.l = l
self.margin = margin
self.trip = TripletLoss(margin, sigma)
self.soft = MetricSoftmaxLoss()
def forward(self, f_anchor,f_positive, f_negative):
f_anchor, f_positive, f_negative = renorm(f_anchor), renorm(f_positive), renorm(f_negative)
with torch.no_grad():
idx = hard_samples_mining(f_anchor, f_positive, f_negative, self.margin)
#print(idx)
loss_trip = self.trip(f_anchor, f_positive, f_negative)
loss_soft = self.soft(f_anchor, f_positive, f_negative)
#print(loss_trip.item(), loss_soft.item())
return loss_trip + self.l * loss_soft
#return self.trip(f_anchor[idx], f_positive[idx], f_negative[idx]) + self.l * self.soft(f_anchor[idx], f_positive[idx], f_negative[idx])
if __name__ == "__main__":
x = torch.randn(3,17)
y = torch.randn(3,17)
z = torch.randn(3,17)
loss_fn = MetricLoss()
res = loss_fn(x,y,z)
目前整个代码已在公司数据集下复现了结果,确实有一定效果,后续将持续更新活体检测的复现代码,上传到我的github上.
Deep Tree Learning for Zero-shot Face Anti-Spoofing
这篇文章采用树状网络来做活体检测,网络分为CRU节点和TRU节点,其中CRU节点为单连接,做卷积提取特征,而TRU节点负责分裂节点.
给定一批数据(包含正负样本的一个batch),先固定网络中的CRU节点的权重,数的深度固定,则网络一定会得到唯一路径,计算路径中的LOSS,更新TRU的权重,然后固定TRU,使用分类监督和mask监督的方式更新CRU的节点权值.
网络大致结构如下:
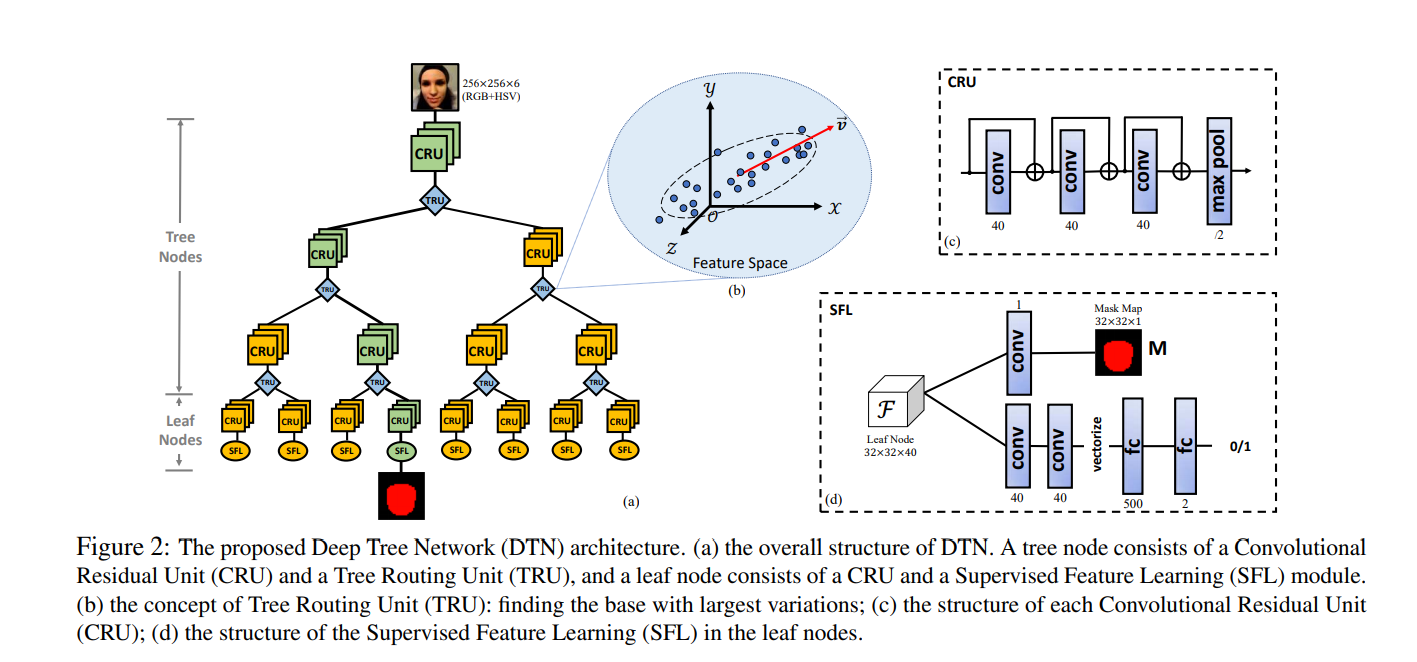
其中TRU有两个可学习参数\(v\)和\(t\),其输出为:
然后根据其值的正负,将一个batch内的样本分到树的两个子节点上去.
其结构为:
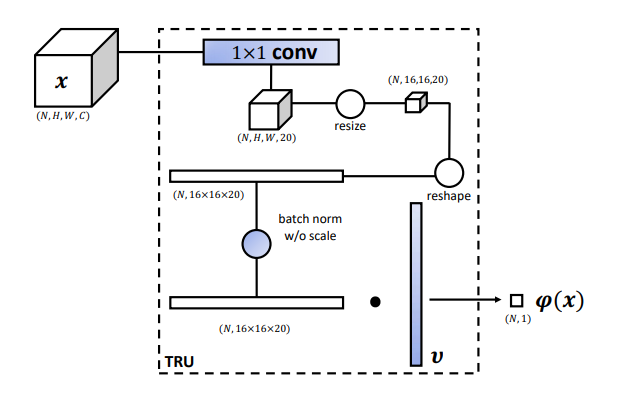
为了让TRU有特征分辨能力,一个简单的想法就是让TRU的两个输出子节点区别最大化,因此,向量\(v\)像是对输入x做投影,找到方差最大的方向,在这个方向上做特征投影,这样不同样本之间的区分度就会变大,因此可以变得易分.上图中的Resize可能是个双线性插值,可以减少参数.
因此loss设计为:

其中前者是投影之后的方差,需要最大化,后面的是正则项引入稀疏防止过拟合.
对于CRU,采用有监督方式训练:
分类的交叉熵 + 输出每个像素的pixel wise loss.
总结一下,可以学习的其实还是网络结构,感觉这个结构也是个通用结构,并不是为这一任务所专门设计的.节点划分的无监督loss挺厉害.
但是感觉吧,太花哨了,不太实用. 不复现.