- 本系列课程由浅入深,讲解常规排序算法的实现及优化步骤。
- 参考《数据结构与算法分析 java语言描述》及李明杰(小码哥)视频课程。
一、冒泡排序
算法过程:
① 从头开始比较每一对相邻元素,如果第1个比第2个大,就交换它们的位置
✓ 执行完一轮后,最末尾那个元素就是最大的元素
② 忽略 ① 中曾经找到的最大元素,重复执行步骤 ①,直到全部元素有序
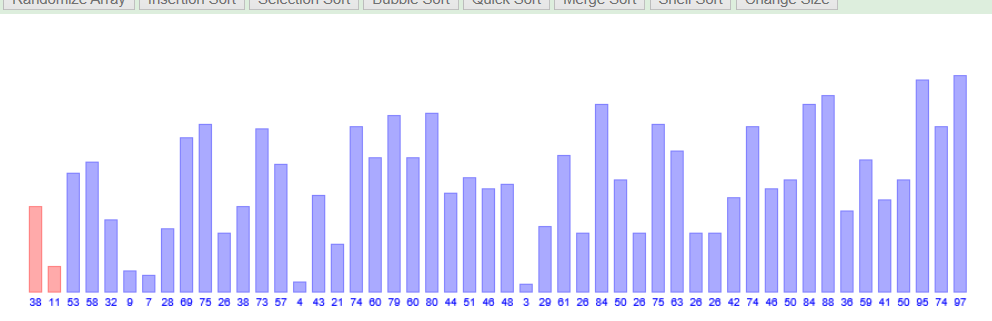
如上图,最终比较完毕后,得到有序数组

直接上初始代码,代码两层for循环非常易懂,
区别于全网很多博客的循环从0开始 真的难以理解他们为什么这么设计!。
1 public static void bubbleSort1(Integer[] arr) { //未优化 2 System.out.println(Arrays.toString(arr)); 3 int count=0; 4 int compare = 0; 5 for (int end = arr.length-1; end > 0 ; end--) { //每次得到一个最大值,第一次在arr.length-1,第二次在 arr.length-2,直到 1,因为此时 0和1不需要再比较了 6 for (int begin = 1; begin <= end; begin++) { //从1开始和前驱节点比较,每次都比较到end, 当然end值每次都减1. 7 compare++; 8 if(arr[begin]<arr[begin-1]){ 9 int tmp = arr[begin] ; 10 arr[begin] = arr[begin - 1]; 11 arr[begin-1 ] = tmp; 12 count++; 13 } 14 } 15 16 } 17 System.out.println(Arrays.toString(arr)); 18 System.out.println("调换次数 "+count); 19 System.out.println("比较次数 "+compare); 20 }
理解:
1、每次循环 begin=1,比较到end结束,关键是end怎么界定?
2、所以提供了外层循环,控制 end值的大小,第一次肯定是到数组末尾,第二次末尾-1,一次类推,直到end=1,结束。
3、完毕,这就是冒泡排序。
计算复杂度O:
由于外层for执行了大概N-1次,每次内层for执行N-1,... 1; 显然 等差数列求和,基本就是O(N^2)的时间复杂度,
由于没有借助其他数组,只是利用了tmp一个对象,空间复杂度是O(1).
二、优化1
上面的算法直接已经是标准的冒泡排序了,也是全网博客的标准答案,但其实使用上并不理想。
比如,数组已经部分有序了, 为什么每次都要两层for循环呢? 是不是需要一个契机来break? 上代码
1 /** 2 * 实际上完全乱序情况下是慢于未优化的,因为每次都多了判断,当比较有序时性能较强。 3 */ 4 public static void bubbleSort2(Integer[] array) { //优化 1 可能数组已经有序了,不需要一直遍历 5 System.out.println(Arrays.toString(array)); 6 int count=0; 7 int compare = 0; 8 for (int end = array.length-1; end > 0 ; end--) { 9 boolean sorted = true; //设置标志位 10 for (int begin = 1; begin <= end; begin++) { //每一次从1 --end的比较,都能得出是否有序(是否进入if循环) 11 compare++; 12 if (array[begin] < array[begin - 1]) { 13 int tmp = array[begin]; 14 array[begin] = array[begin - 1]; 15 array[begin - 1] = tmp; 16 sorted = false; //只要排序了 就false 17 count++; 18 } 19 } 20 if(sorted) break; //一旦有一次排序没有改变任何位置,就代表不需要继续排序了 21 22 } 23 System.out.println(Arrays.toString(array)); 24 System.out.println("调换次数 "+count); 25 System.out.println("比较次数 "+compare); 26 }
上述代码的思想主要在一个中断标志位:
当 for (int begin = 1; begin <= end; begin++) 这次循环 一次都没有进入 if()结构,那么 该数组一定是有序的! 是吧,直接break!!!
比如提供了个有序数组 {1,2,3,4,5},第一次for循环进去,就会直接退出,是不是比原来 20多次遍历效率高得多!
但是该优化实际上是有缺点,因为当数组大量数据又无序的情况下,多了判断 效率更低一点点。
三、优化2
针对上述问题,我们再执行一点点的优化,形成实用性更强的冒泡排序
1 /** 2 * 优化2,针对于部分有序,比如 末尾的 N个值已经有序了,那么每次 if循环 都是不必要的。 3 * 最终,它的效率是最高的! 4 */ 5 public static void bubbleSort3(Integer[] array) { //优化 2 6 System.out.println(Arrays.toString(array)); 7 int count=0; 8 int compare = 0; 9 for (int end = array.length-1; end > 0 ; end--) { 10 int sortIndex = 1; //初始值是为了完全有序时做准备的 完全有序 直接退出for循环 11 for (int begin = 1; begin <= end; begin++) { 12 compare++; 13 if (array[begin] < array[begin - 1]) { 14 int tmp = array[begin]; 15 array[begin] = array[begin - 1]; 16 array[begin - 1] = tmp; 17 sortIndex = begin; 18 count++; 19 } 20 } 21 end = sortIndex; //后面的就不用再比较了 一定是有序的 22 } 23 24 System.out.println(Arrays.toString(array)); 25 System.out.println("调换次数 "+count); 26 System.out.println("比较次数 "+compare); 27 }
思想:
1、我们假设{3,2,1,5,6,7,8,9},显然5,6,7,8,9已经有序了,那么 if()中,会执行交换位置,执行到5就停止了,因为5 6 7 8 9根本不会交换位置,不会进入if 循环,所以 sortIndex = 5
2、 end值被设置成了5, 本来是7的,就跳过了 6 7 8,如果数组数据量更大,这会是显著的优化
3、关于sortIndex=1,主要是为了针对 完全有序的数组,那么for循环一进来 就会退出,是end = 1,结束全部循环。
四、比较性能
1 完全无序
我们测试下 三种比较算法的性能 1: 我使用了 int数组 包含了随机生成的10000个数字,从1-300000中随机选取。
可以看出,完全乱序下,原生的算法效率最高,因为少执行了两步。
第一次的优化,不怎么理想,主要在于 完全无序时,多执行了2步,形成负优化,第二次是对第一次的加强!
第二次的优化比较次数最少。
2、部分尾端有序
再试一下 部分有序的情况:又测试了部分数据,1-10000,但是后2000个是升序的! 这种情况下,效率差别就明显了。
原生方法无论什么数据,都是一样的比较次数,而后两种则优化明显。

3、 根据实际情况,选择使用!
关于最终的时间复杂度,最差O(n^2) ,最好是O(n),第一轮内层for循环结束就退出了。
空间复杂度O(1)
并且bubblesort是稳定排序, 因为当A>B 才交换位置,A=B,不动!