打开网页
https://list.tmall.com
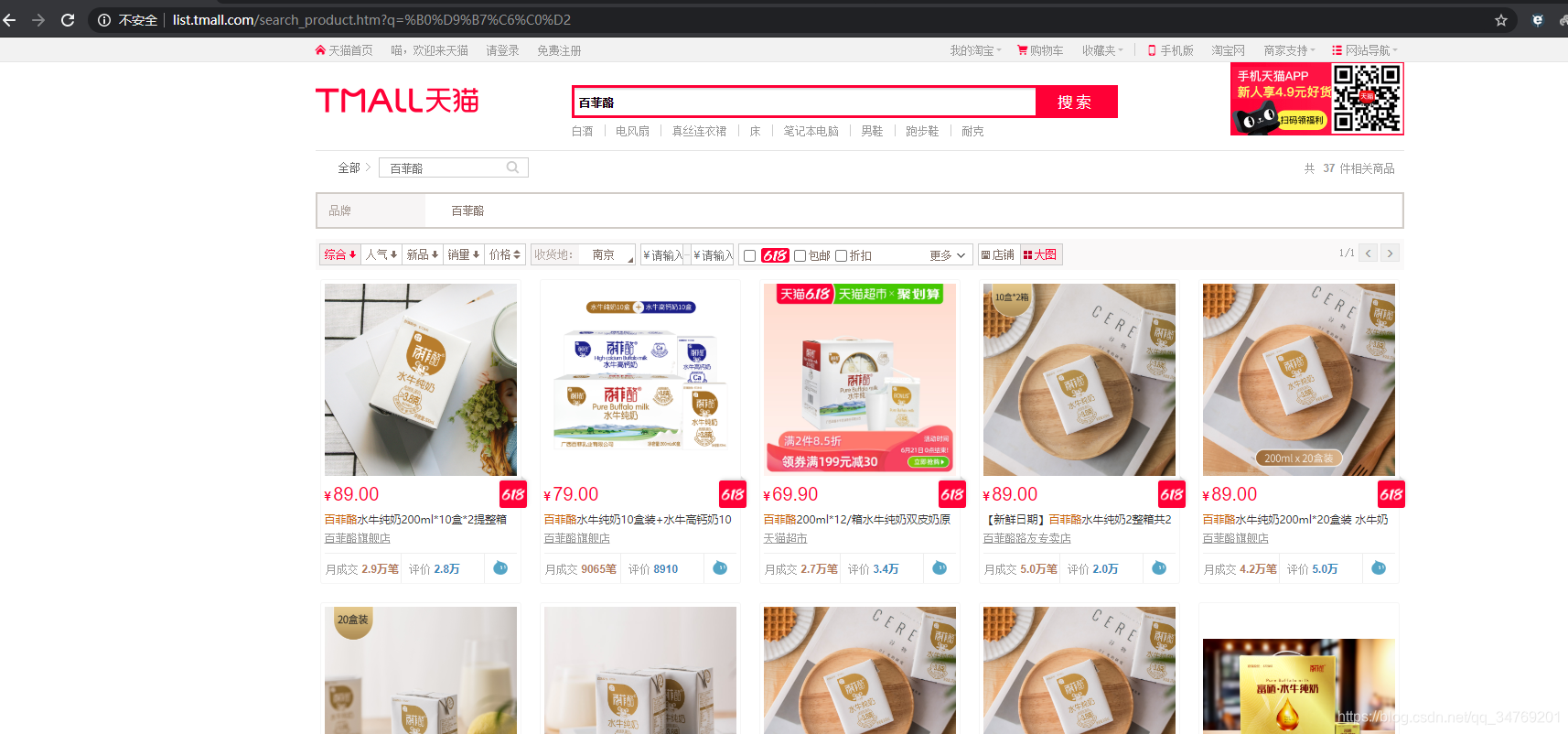
搜索关键词:百菲酪
得到这个页面:

后面的网址多了许多,其实可以去掉的。
网址变成了:
https://list.tmall.com/search_product.htm?q=%B0%D9%B7%C6%C0%D2
q=表示的是搜索的内容
找关键词
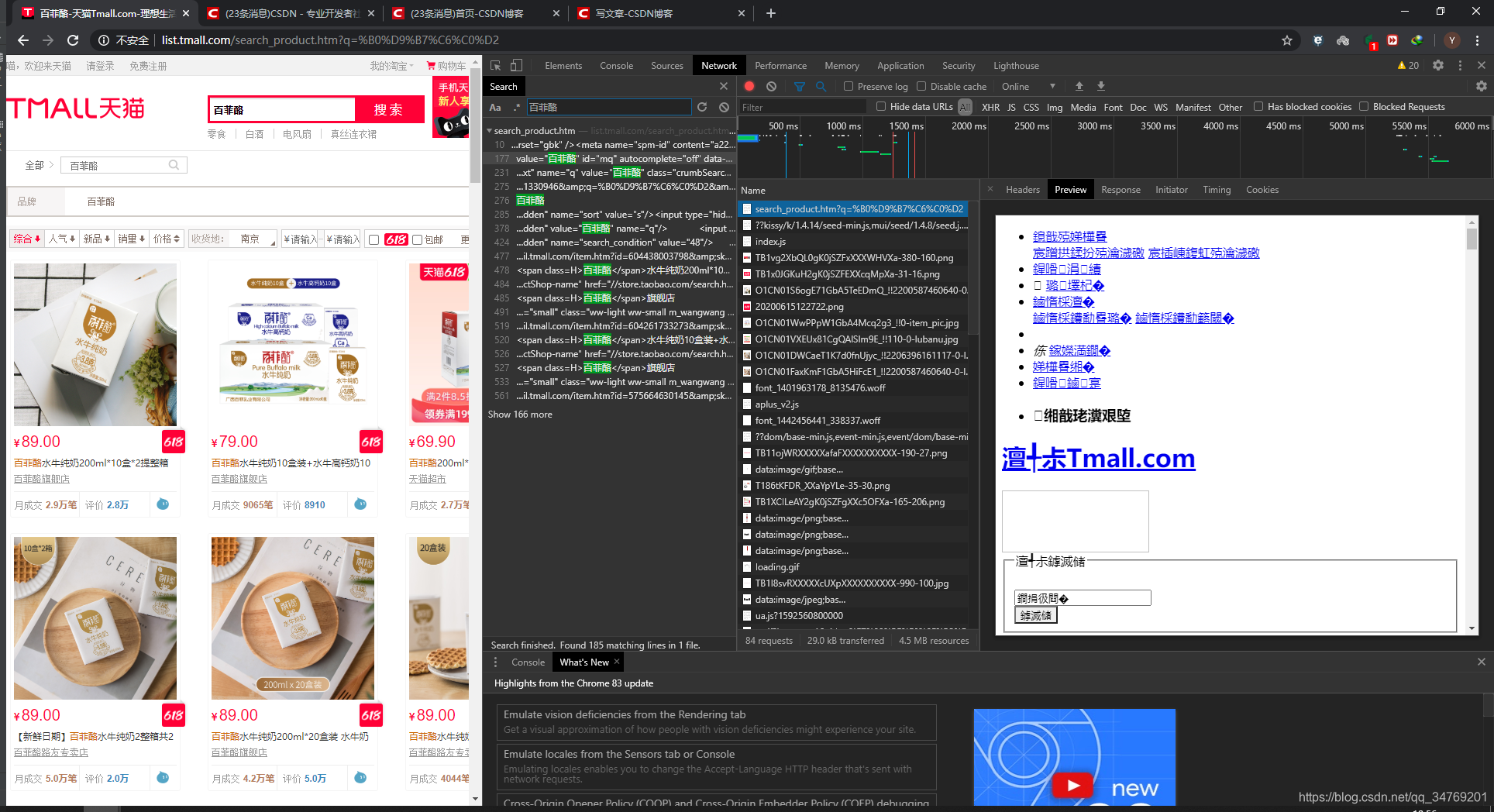
搜:百菲酪,得到这个页面,第一各搜索结果点开之后看preview的内容,是一个网页。
虽然是乱码,但是能知道,这个表示的就是我们要搜的内容了。
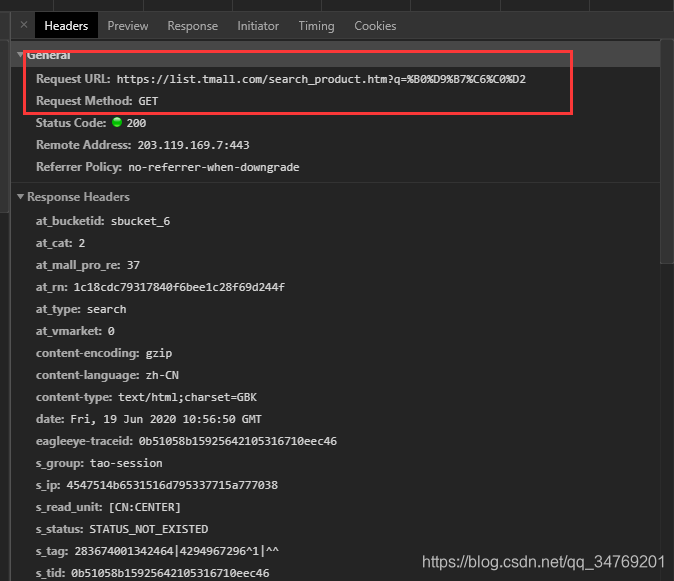
看headers
url与之前的一样,说明我们要的数据只能在这个页面中拿到,而不是以前那样调用接口,这时候就需要使用html的解析包了。
直接切到elements页面
鼠标放到这这里页面会变色
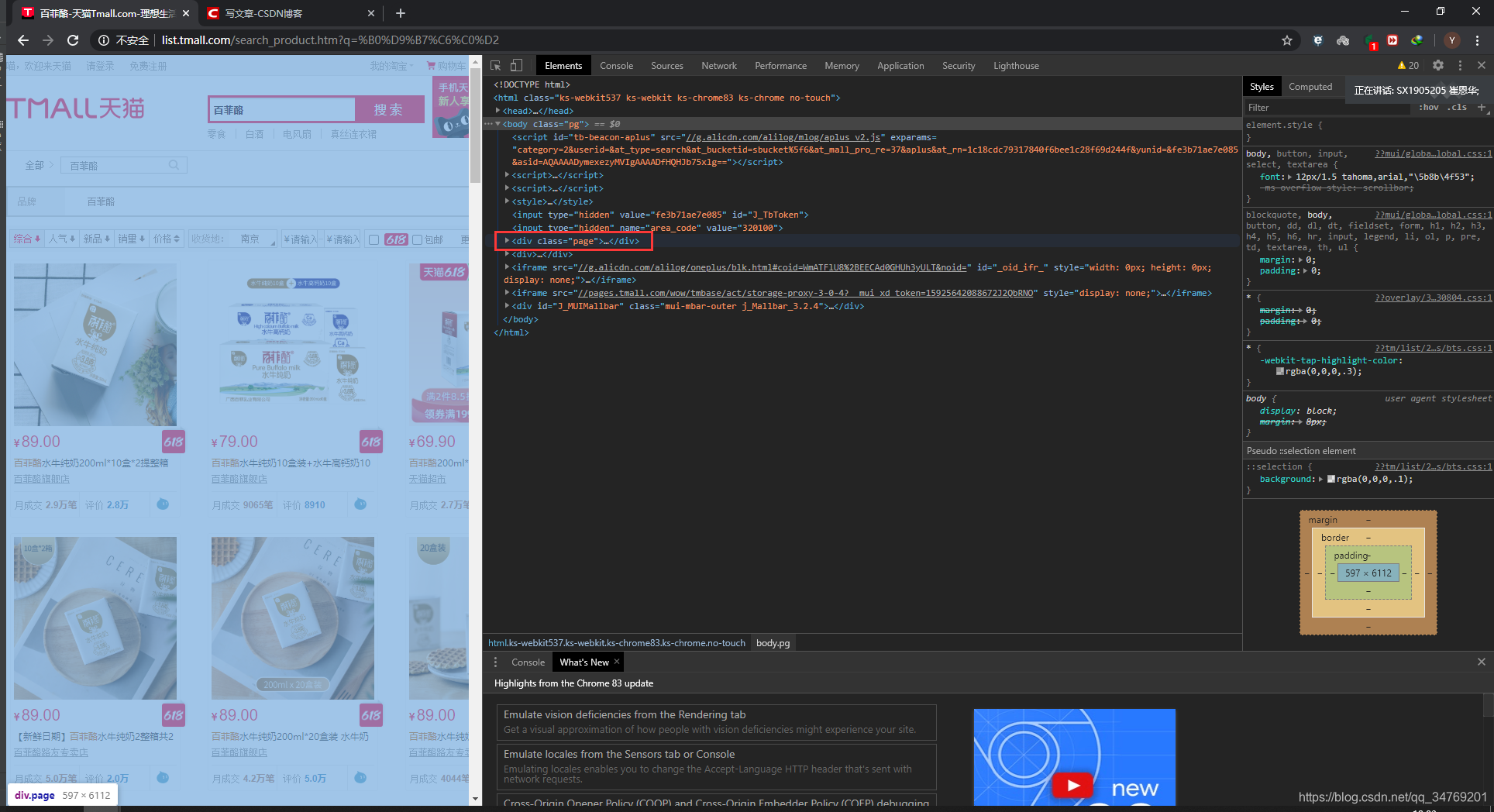
逐层点开:就会找到第一个页面
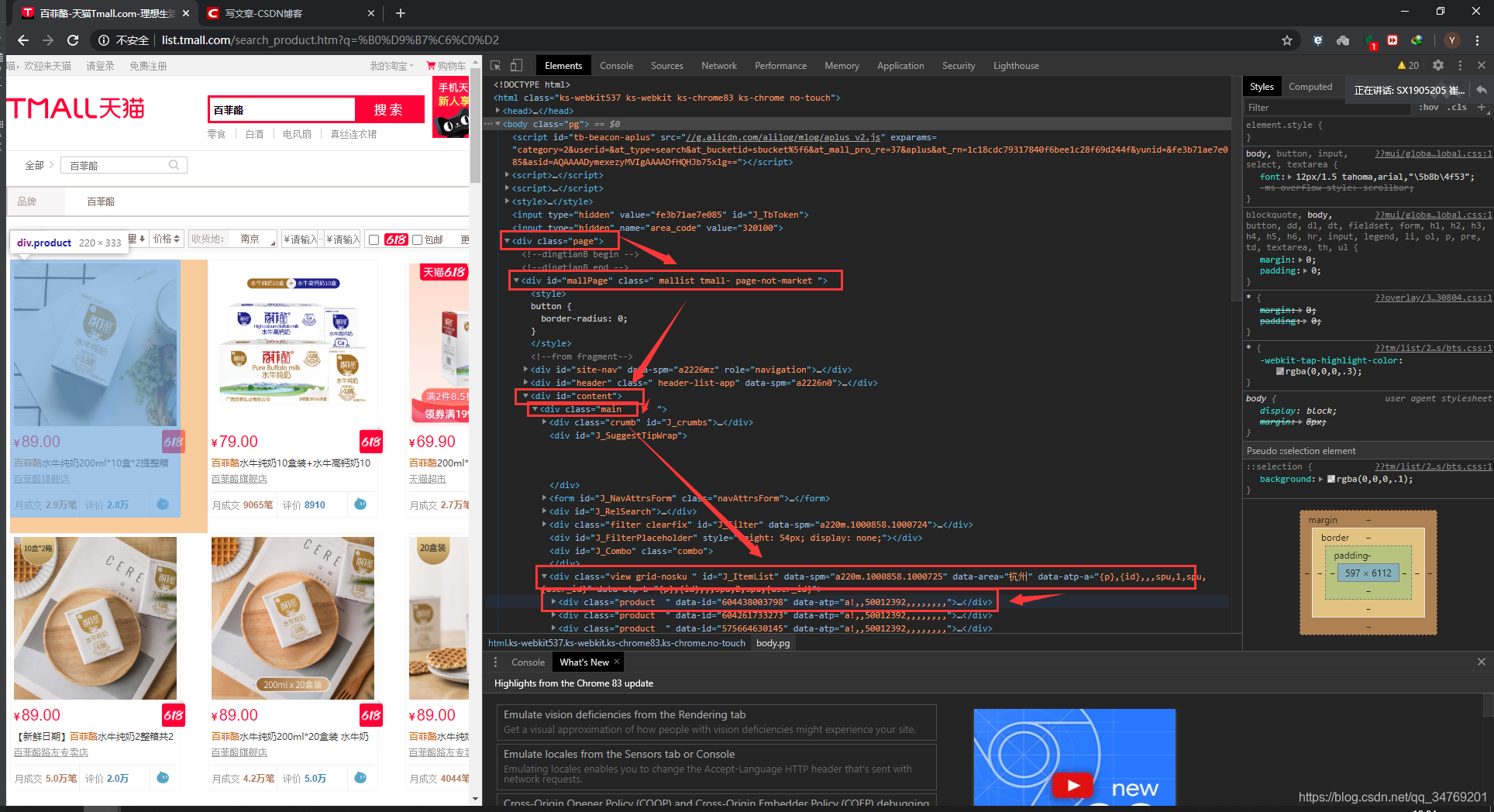
点开第一个,就可以看到下面的一些信息,名称,价格,销量,链接什么的。
代码编写
首先导入所有可能用到的库
import requests
from bs4 import BeautifulSoup
import pandas as pd
利用requests库获得网页
url = 'https://list.tmall.com/search_product.htm?q=%B0%D9%B7%C6%C0%D2'
cookie = 'lid=wxyz%E5%BC%A0%E5%B0%8F%E5%AE%87; cna=WmATFlU8+EECAd0GHUh3yULT; hng=CN%7Czh-CN%7CCNY%7C156; enc=ZNFhaIFW1p5Hq6wgvzAxS%2FzkjrOgydFJwNPEGw8iaOdO1WOM9lrq46Z%2FPybotav9nc7KguU0Zh%2FzwdeQXVv6%2BA%3D%3D; tfstk=cXwPBjswMTBPCO6Y6YHEA4dbej0RZ0ZuxKosZ5i9sOIw-SGliw8KmgVi0DgOnbf..; _m_h5_tk=c42005162ceb6674955af76a3fa4fda8_1591807211158; _m_h5_tk_enc=e8e001c2a1d122cb08efc2156abc66f0; sm4=320104; sgcookie=ELGGkuRkdAUdGrhpElf83; t=da3b00c614ce5a9700bda120fbf14e31; uc3=id2=UUjQmZ93YcL0xg%3D%3D&vt3=F8dBxGDcRZOmgG6aB9g%3D&lg2=V32FPkk%2Fw0dUvg%3D%3D&nk2=FOGMcn2hWzXWDg%3D%3D; tracknick=wxyz%5Cu5F20%5Cu5C0F%5Cu5B87; uc4=nk4=0%40Fmq1SyyK2xxNRSzRvt9%2Bhw2KAbsy&id4=0%40U2oyU0vPPgBqhNeXurMsPtoIo4yH; lgc=wxyz%5Cu5F20%5Cu5C0F%5Cu5B87; _tb_token_=ea18e30ee089; cookie2=1d4b6a6387c86358887cf038681d96db; _med=dw:1920&dh:1080&pw:1920&ph:1080&ist:0; res=scroll%3A1903*4685-client%3A1903*969-offset%3A1903*4685-screen%3A1920*1080; pnm_cku822=098%23E1hvNpvUvbpvUpCkvvvvvjiPnLzyljibRFLwsjD2PmPvljEmnLsUsjl8RFdy0jlWPFyCvvBvpvvv2QhvCvvvvvvEvpCWBjECv8RKfvyf8cc6%2BulQb7gmDfesRk9hEcqwaXTxEctAbqmxdByaUjCwD704d56OVAilK24Abyy6cbmD5316B53Z0f06WeCpJ1kHs4yCvv3vpvLE6YaZkOyCvvXmp99hjEetvpvIphvvvPMMKLDvpCQmvvC2kyCvjvUvvhBGphvwv9vvBHBvpCQmvvChxvhCvvXvppvvvvm5vpvhphvhHv%3D%3D; cq=ccp%3D1; l=eBE8gbs4q7iiWH-tBOfZhurza779pIRAguPzaNbMiOCP_R1p5UJNWZxDpB89CnGVh6cv53RILX7BBeYBqIY75O9StBALuSHmn; isg=BDc32GtBJe3qQ6JvosA28GlRxiuB_AteVQNiSInkYYZtOFd6lcvHr9EaHphm0OPW'
headers = {'User-Agent': 'Mozilla/5.0',
'Cookie': cookie}
r = requests.get(url, headers=headers)
text = r.text
可以把text输出看看
print(text)
会发现是这样的,是一个完整的网页:

此时需要使用bs4的库来解析
soup = BeautifulSoup(text, features="lxml") # 使用bs4解析
我们需要的数据只在body中,所以再获取一下body中的数据

body = soup.body # 只获取其中body部分
此时body就是刚刚整个网页,而这个标签就包含了所有我们需要的数据。
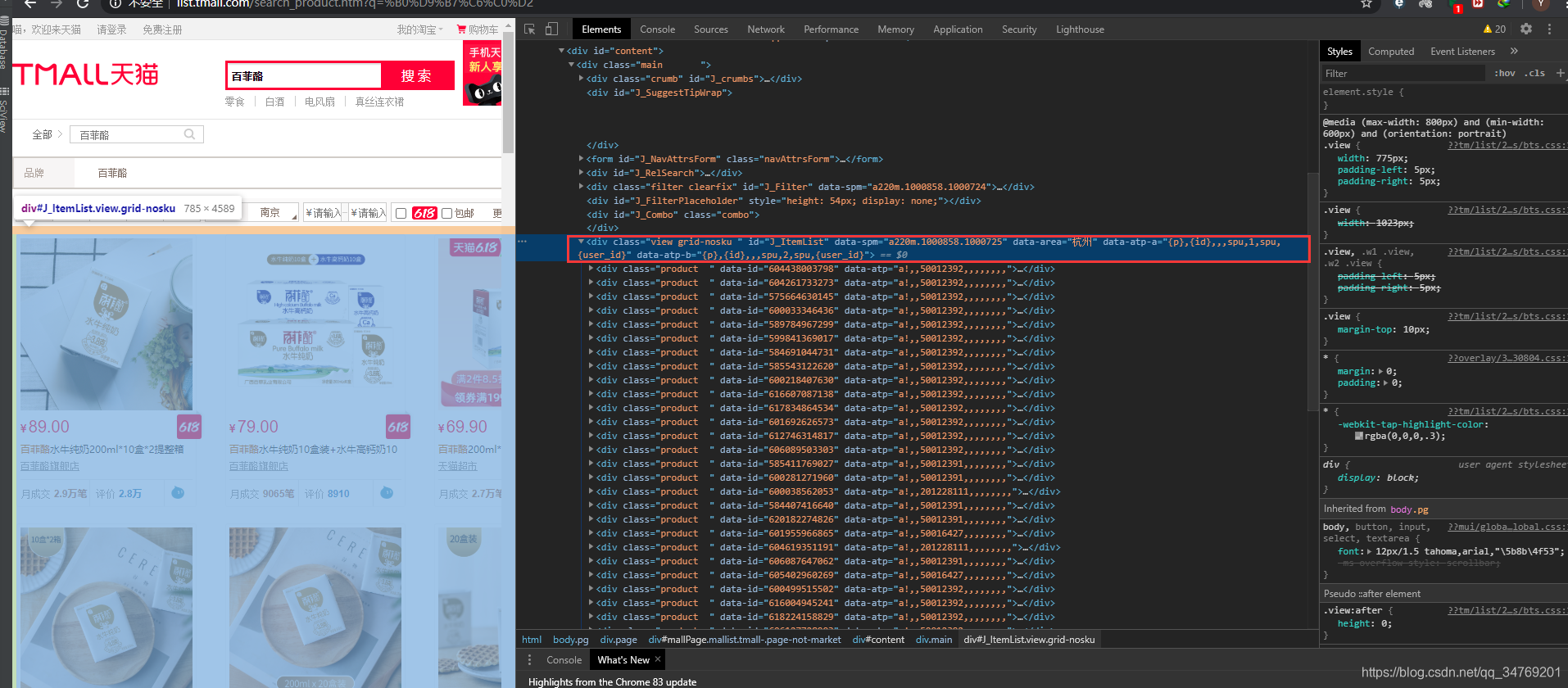
所以利用find_all函数来查找,'div’表示其类型,id="J_ItemList"是通过id来查找,这个函数返回的是一个列表,可以输出出来看看
result = soup.find_all('div', id="J_ItemList")
print(type(result))
print(len(result))
print(result)
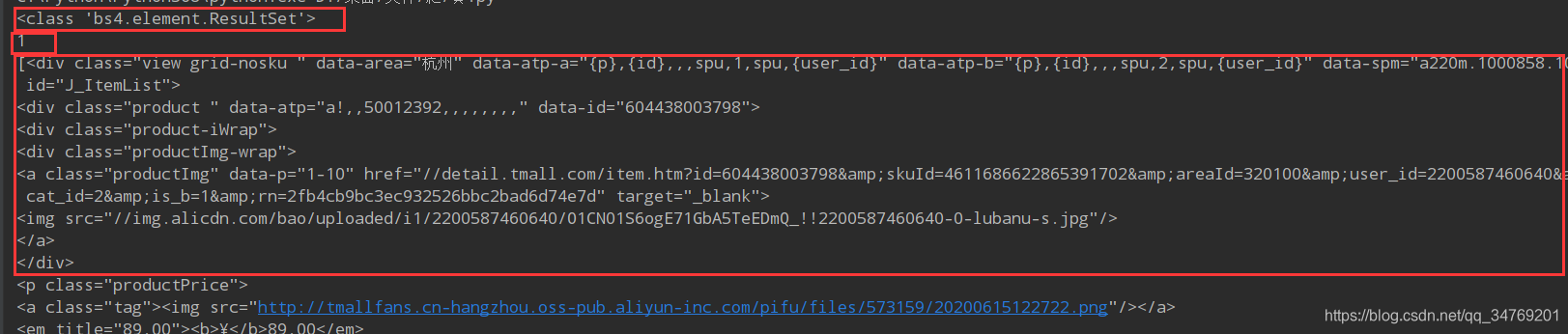
返回的分别是这三个
第一个是bs4里面的数据类型,实际上是一个列表
len表示它的长度为1
最后是内容。
说明还是有用的,只获取到了唯一一个查找内容,所以取它第一个就好了。因此
result = soup.find_all('div', id="J_ItemList")[0]
print(type(result))
再次输出它的类型,就是这个了,是bs4库里面的一个标准类型。
<class 'bs4.element.Tag'>
此时,result里面是这些个产品
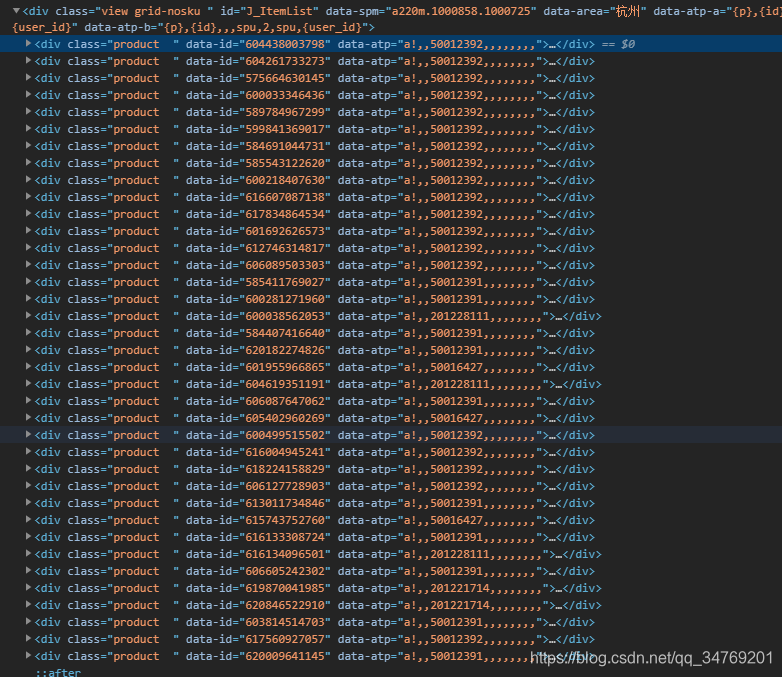
这个标签代表一个产品product-iWrap,所以查找这个标签就行
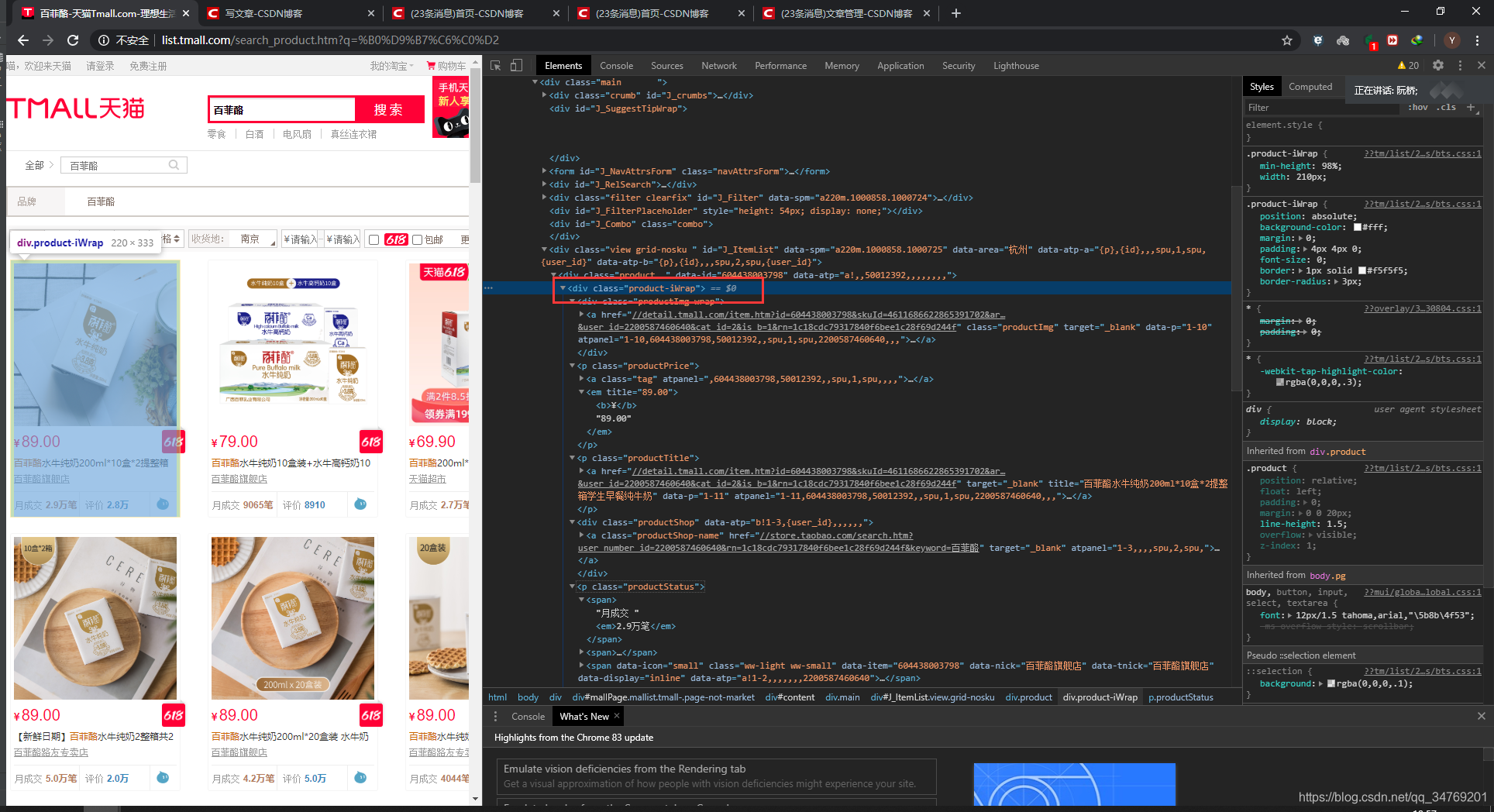
result2 = result.find_all('div', class_='product-iWrap') # 查找数据
print(len(result2)) # 看看数量
数量是37,说明是对的
37
Process finished with exit code 0
再看看他们的数据结构。
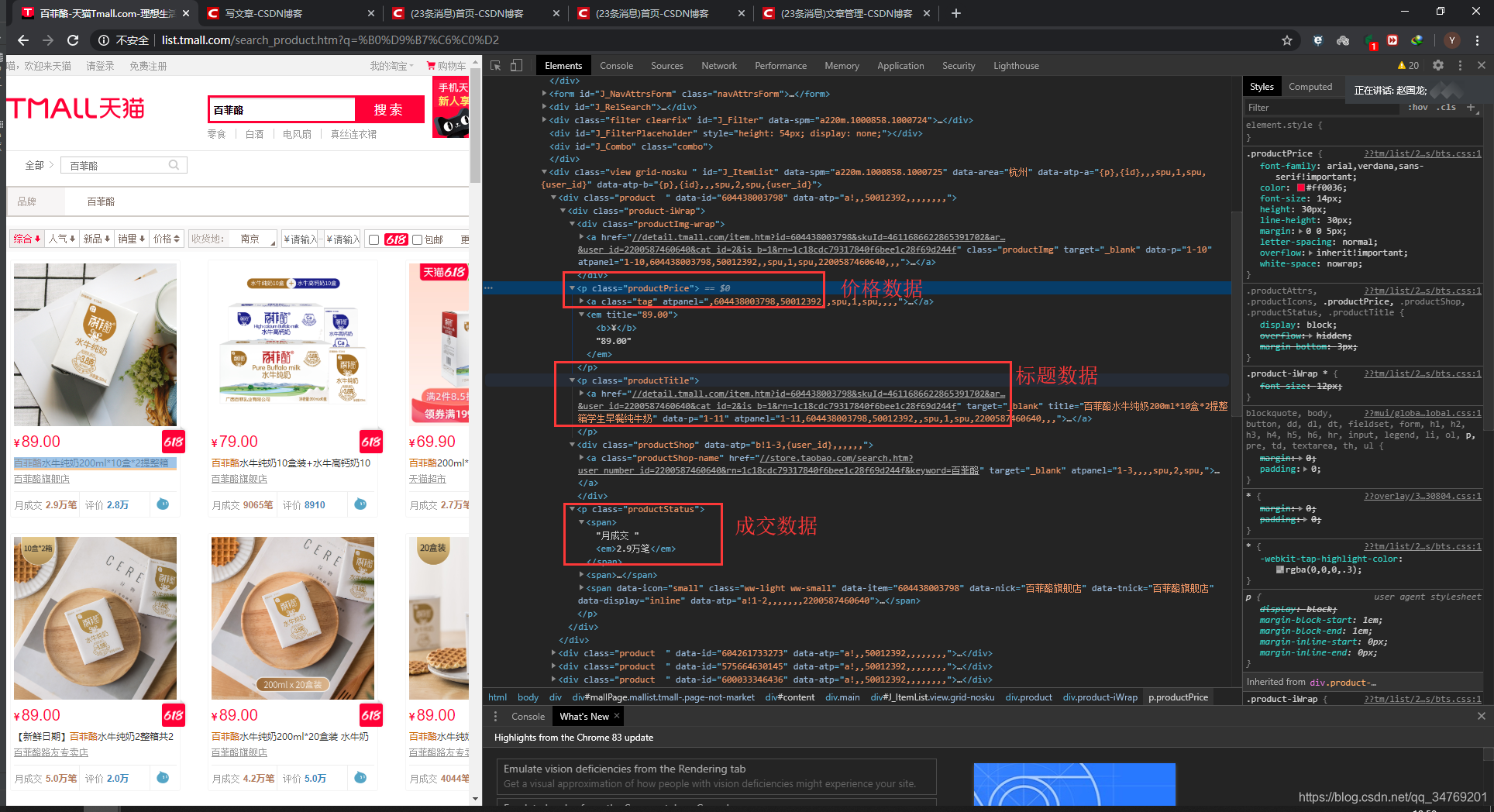
以第一个为例。
result3 = result2[0] # 此时result3就是第一个数据
查找标题:
productTitle = result3.find_all('p', class_='productTitle') # 查找数据
print(productTitle)
发现只查找到了一个数据,并且里面有我们需要的数据
[<p class="productTitle">
<a data-p="1-11" href="//detail.tmall.com/item.htm?id=604438003798&skuId=4611686622865391702&areaId=320100&user_id=2200587460640&cat_id=2&is_b=1&rn=4241a9b2e7ddcdf7b7acb4ad68e81054" target="_blank" title="百菲酪水牛纯奶200ml*10盒*2提整箱学生早餐纯牛奶">
<span class="H">百菲酪</span>水牛纯奶200ml*10盒*2提整箱学生早餐纯牛奶
</a>
</p>]
所以把代码改一下,就能获得数据了:
productTitle = result3.find_all('p', class_='productTitle')[0].text # 查找数据
print(productTitle)
百菲酪水牛纯奶200ml*10盒*2提整箱学生早餐纯牛奶
Process finished with exit code 0
查找价格:
productPrice = result3.find_all('em') # 查价格
print(productPrice)
[<em title="89.00"><b>¥</b>89.00</em>, <em>2.9万笔</em>]
Process finished with exit code 0
发现了两个数据,其中一个是价格,另一个是销量,为什么呢?
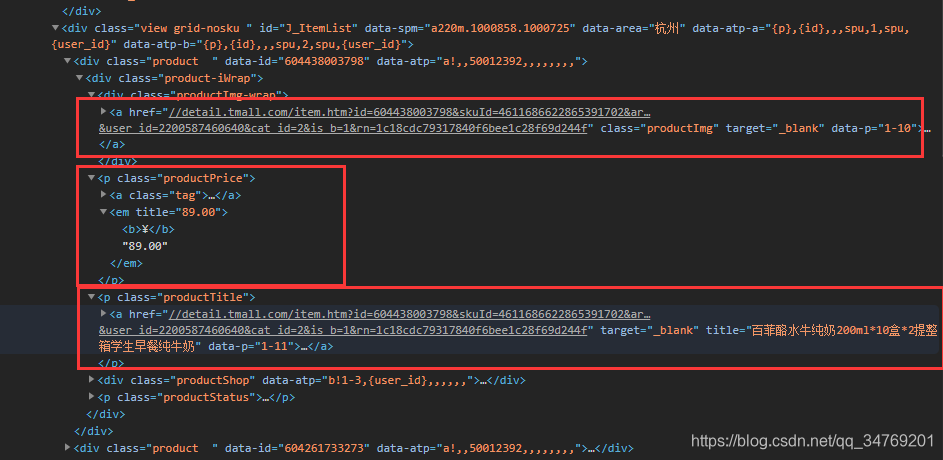
看图片:
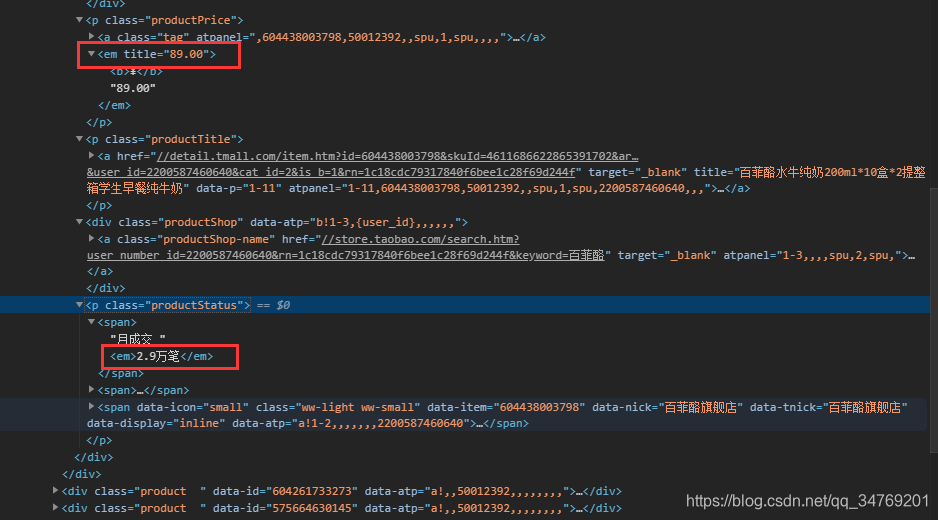
价格和销量的名字都是em,所以查到了两个,因此直接把两个都调用出来就好了。
productPrice = result3.find_all('em')[0].text # 查价格
productStatus = result3.find_all('em')[1].text # 查销量
print(productPrice)
print(productStatus)
¥89.00
2.9万笔
Process finished with exit code 0
最终,把整个放进一个循环。
for result3 in result2:
productTitle = result3.find_all('p', class_='productTitle')[0].text # 查找数据
print(productTitle)
productPrice = result3.find_all('em')[0].text # 查价格
productStatus = result3.find_all('em')[1].text # 查销量
print(productPrice)
print(productStatus)
发现程序报错:
百菲酪水牛高钙奶200ml*12纯奶冰淇淋口感优质乳蛋白
Traceback (most recent call last):
File "D:/桌面/文件/爬/黄.py", line 22, in <module>
productStatus = result3.find_all('em')[1].text # 查销量
IndexError: list index out of range
Process finished with exit code 1
说超出列表了,为什么呢?因为,不是所有的都有销量数据!
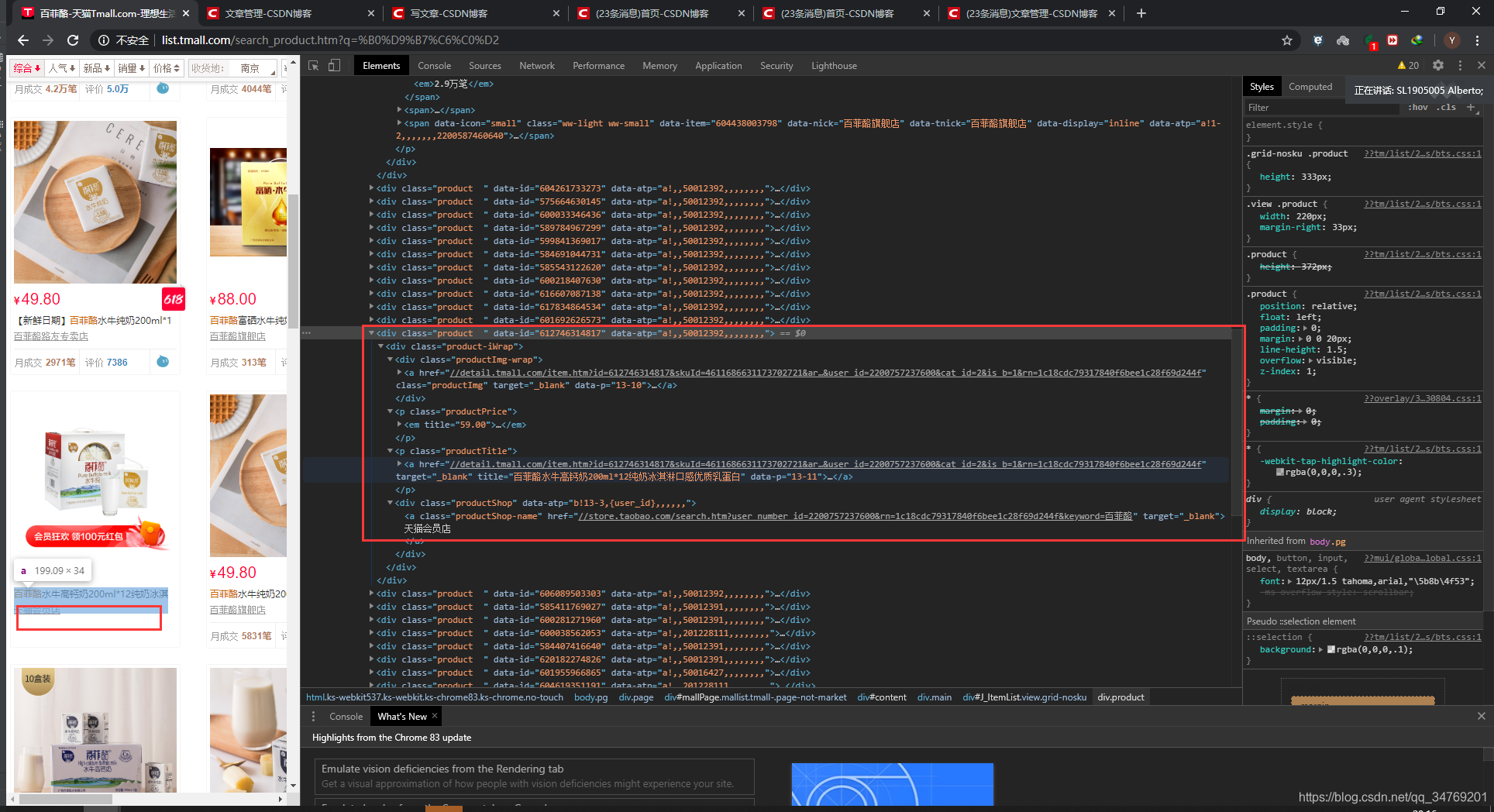
像这个,就没有销量数据,所以要进行处理,把没有销量的用None代替就好了。
for result3 in result2:
productTitle = result3.find_all('p', class_='productTitle')[0].text # 查找数据
print(productTitle)
if len(result3.find_all('em')) == 1:
productPrice = result3.find_all('em')[0].text # 查价格
print(productPrice)
else:
productPrice = result3.find_all('em')[0].text # 查价格
print(productPrice)
productStatus = result3.find_all('em')[1].text # 查销量
print(productStatus)
输出出来看看是没错的:
百菲酪200ml*12/箱水牛纯奶双皮奶原料奶适合中国胃
¥69.90
9笔
百菲酪高钙水牛奶200ml*10盒全脂青少年学生儿童成人早餐奶
¥42.90
Process finished with exit code 0
这里采用padas的数据结构进行处理,先生成一个DataFrame的空表:
product_information = pd.DataFrame(columns=['名字', '价格', '销量'])
然后对表格进行插入的操作就行了
for i, result3 in enumerate(result2):
productTitle = result3.find_all('p', class_='productTitle')[0].text # 查找数据
if len(result3.find_all('em')) == 1:
productPrice = result3.find_all('em')[0].text # 查价格
productStatus = None
else:
productPrice = result3.find_all('em')[0].text # 查价格
productStatus = result3.find_all('em')[1].text # 查销量
product_information = product_information.append(
pd.DataFrame([[productTitle, productPrice, productStatus]], index=[i], columns=['名字', '价格', '销量']))
print(product_information)
输出是这样的
26 \n\n【新鲜日期】百菲酪水牛纯奶200ml*20盒 网红常温牛奶早餐整箱\n\n ¥109.00 70笔
27 \n\n百菲酪水牛高钙奶200ml*10盒*2件装 牛奶整箱学生成长营养早餐奶\n\n ¥74.00 119笔
28 \n\n【新品上市】百菲酪原味水牛酸奶饮品125ml*12瓶益生菌发酵乳\n\n ¥44.80 58笔
29 \n\n百菲酪高钙水牛奶200ml*10盒装 牛奶整箱学生儿童成长营养早餐奶\n\n ¥44.80 71笔
30 \n\n【新品上市】百菲酪原味味水牛酸奶饮品125ml*12瓶益生菌发酵乳\n\n ¥49.90 34笔
31 \n\n百菲酪高钙水牛奶200ml*10盒装 牛奶整箱学生儿童成长营养早餐奶\n\n ¥44.80 10笔
32 \n\n百菲酪水牛纯奶200ml*12盒兑换卡 6次\n\n ¥316.80 3笔
33 \n\n百菲酪水牛纯奶200ml*12盒装兑换卡6次\n\n ¥316.80 8笔
34 \n\n百菲酪高钙水牛奶200ml*10盒全脂青少年学生儿童成人早餐奶\n\n ¥54.90 244笔
35 \n\n百菲酪200ml*12/箱水牛纯奶双皮奶原料奶适合中国胃\n\n ¥69.90 9笔
36 \n\n百菲酪高钙水牛奶200ml*10盒全脂青少年学生儿童成人早餐奶\n\n ¥42.90 None
Process finished with exit code 0
enumerate是枚举的意思,i代表序号,result3代表的是内容,然后发现名字有很多\n,可以通过字符串处理掉。
for i, result3 in enumerate(result2):
productTitle = result3.find_all('p', class_='productTitle')[0].text # 查找数据
productTitle = productTitle.replace("\n", "") # 去空格
if len(result3.find_all('em')) == 1:
productPrice = result3.find_all('em')[0].text # 查价格
productStatus = None
else:
productPrice = result3.find_all('em')[0].text # 查价格
productStatus = result3.find_all('em')[1].text # 查销量
product_information = product_information.append(
pd.DataFrame([[productTitle, productPrice, productStatus]], index=[i], columns=['名字', '价格', '销量'])) #在第i行插入数据
print(product_information)
最后得到的数据是这样的:
32 百菲酪水牛纯奶200ml*12盒兑换卡 6次 ¥316.80 3笔
33 百菲酪水牛纯奶200ml*12盒装兑换卡6次 ¥316.80 8笔
34 百菲酪高钙水牛奶200ml*10盒全脂青少年学生儿童成人早餐奶 ¥54.90 244笔
35 百菲酪200ml*12/箱水牛纯奶双皮奶原料奶适合中国胃 ¥69.90 9笔
36 百菲酪高钙水牛奶200ml*10盒全脂青少年学生儿童成人早餐奶 ¥42.90 None
Process finished with exit code 0
最终代码
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = 'https://list.tmall.com/search_product.htm?q=%B0%D9%B7%C6%C0%D2'
cookie = 'lid=wxyz%E5%BC%A0%E5%B0%8F%E5%AE%87; cna=WmATFlU8+EECAd0GHUh3yULT; hng=CN%7Czh-CN%7CCNY%7C156; enc=ZNFhaIFW1p5Hq6wgvzAxS%2FzkjrOgydFJwNPEGw8iaOdO1WOM9lrq46Z%2FPybotav9nc7KguU0Zh%2FzwdeQXVv6%2BA%3D%3D; tfstk=cXwPBjswMTBPCO6Y6YHEA4dbej0RZ0ZuxKosZ5i9sOIw-SGliw8KmgVi0DgOnbf..; _m_h5_tk=c42005162ceb6674955af76a3fa4fda8_1591807211158; _m_h5_tk_enc=e8e001c2a1d122cb08efc2156abc66f0; sm4=320104; sgcookie=ELGGkuRkdAUdGrhpElf83; t=da3b00c614ce5a9700bda120fbf14e31; uc3=id2=UUjQmZ93YcL0xg%3D%3D&vt3=F8dBxGDcRZOmgG6aB9g%3D&lg2=V32FPkk%2Fw0dUvg%3D%3D&nk2=FOGMcn2hWzXWDg%3D%3D; tracknick=wxyz%5Cu5F20%5Cu5C0F%5Cu5B87; uc4=nk4=0%40Fmq1SyyK2xxNRSzRvt9%2Bhw2KAbsy&id4=0%40U2oyU0vPPgBqhNeXurMsPtoIo4yH; lgc=wxyz%5Cu5F20%5Cu5C0F%5Cu5B87; _tb_token_=ea18e30ee089; cookie2=1d4b6a6387c86358887cf038681d96db; _med=dw:1920&dh:1080&pw:1920&ph:1080&ist:0; res=scroll%3A1903*4685-client%3A1903*969-offset%3A1903*4685-screen%3A1920*1080; pnm_cku822=098%23E1hvNpvUvbpvUpCkvvvvvjiPnLzyljibRFLwsjD2PmPvljEmnLsUsjl8RFdy0jlWPFyCvvBvpvvv2QhvCvvvvvvEvpCWBjECv8RKfvyf8cc6%2BulQb7gmDfesRk9hEcqwaXTxEctAbqmxdByaUjCwD704d56OVAilK24Abyy6cbmD5316B53Z0f06WeCpJ1kHs4yCvv3vpvLE6YaZkOyCvvXmp99hjEetvpvIphvvvPMMKLDvpCQmvvC2kyCvjvUvvhBGphvwv9vvBHBvpCQmvvChxvhCvvXvppvvvvm5vpvhphvhHv%3D%3D; cq=ccp%3D1; l=eBE8gbs4q7iiWH-tBOfZhurza779pIRAguPzaNbMiOCP_R1p5UJNWZxDpB89CnGVh6cv53RILX7BBeYBqIY75O9StBALuSHmn; isg=BDc32GtBJe3qQ6JvosA28GlRxiuB_AteVQNiSInkYYZtOFd6lcvHr9EaHphm0OPW'
headers = {'User-Agent': 'Mozilla/5.0',
'Cookie': cookie}
r = requests.get(url, headers=headers) # 爬取网页
text = r.text
soup = BeautifulSoup(text, features="lxml") # 使用bs4解析
body = soup.body # 只获取其中body部分
result = soup.find_all('div', id="J_ItemList")[0]
result2 = result.find_all('div', class_='product-iWrap') # 查找数据
product_information = pd.DataFrame(columns=['名字', '价格', '销量'])
for i, result3 in enumerate(result2):
productTitle = result3.find_all('p', class_='productTitle')[0].text # 查找数据
productTitle = productTitle.replace("\n", "") # 去空格
if len(result3.find_all('em')) == 1:
productPrice = result3.find_all('em')[0].text # 查价格
productStatus = None
else:
productPrice = result3.find_all('em')[0].text # 查价格
productStatus = result3.find_all('em')[1].text # 查销量
product_information = product_information.append(
pd.DataFrame([[productTitle, productPrice, productStatus]], index=[i], columns=['名字', '价格', '销量']))
print(product_information)