#coding:utf-8
import re
import xlrd
import xlwt
import time
import pandas as pds
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser=webdriver.Chrome() #驱动谷歌浏览器
#读取excel
def excel(fname):
data=pds.read_excel(fname)
return data
#进入网站
def go_url(url):
wait=WebDriverWait(browser,3)
try:
browser.get(url)
wait.until(
EC.presence_of_element_located((By.XPATH,'//div[@class="places-tab margin20"]//table')),
)
except TimeoutException:
print('Timeout')
#定位节点——点击
def click_locatin_element(element , text):
try:
button=browser.find_element_by_xpath(element)
button.click()
except:
print(text+"不可点击")
#根据文本——点击
def click_according_text(text):
try:
button=browser.find_element_by_link_text(text)
button.click()
except:
print(text+'不可点击')
#下拉+内容——点击
def pull_down_menu(down_element ,error_text1, text):
click_locatin_element(down_element , error_text1)
click_according_text(text)
#获取url中的表并写入文件
def write_table_data(url):
try:
data =pds.read_html(url)[0]
data.to_csv('C:/Users/Administrator/Desktop/一批文分数线.csv', sep=',', mode='a',index = False, )
except:
print('无数据')
#获取当前网页的url
def get_current_url():
url = browser.current_url
print(url)
return url
#获取url中的表并写入文件
def write_school(i , school):
writeschool=pds.DataFrame([[i,school]])
writeschool.to_csv('C:/Users/Administrator/Desktop/一批文分数线.csv', sep=',', mode='a',index = False,header = False)
#计算运行时间的装饰器
def my_time(func):
def wrapper():
s_time = time.time() #程序初始时间
func()
e_time = time.time()#程序运行完的时间
print('totally cost :{:.2f}'.format(e_time-s_time)+'秒') #获取总时间
return wrapper
@my_time #装饰器
def total():
data=excel("C:/Users/Administrator/Desktop/pandas.xls") #读数据
nrow=data.shape[0] #获取数据的行数
for i in range(0,nrow):
url=data.values[i][1]
school=data.values[i][0]
print("正在爬取第"+str(i)+"个学校")
write_school(i ,school) #写入学校
go_url(url) #进入初始网页
if (i ==0): #第一次进入网页要点击“湖北”
click_locatin_element('//div[@class="citybox clearfix"]//div[@province_code="42"]' ,'湖北') #点击湖北
pull_down_menu('//div[@class="li-selectDiv right"]//div[@id="schoolexamieetype"]' , '下拉框' , '文科') #点击文科所在的下拉框
url=get_current_url() #获取当前网页的url
write_table_data(url) #获取url中的表并写入文件
browser.close() #关闭浏览器
if __name__ == '__main__':
total()
爬取结果:
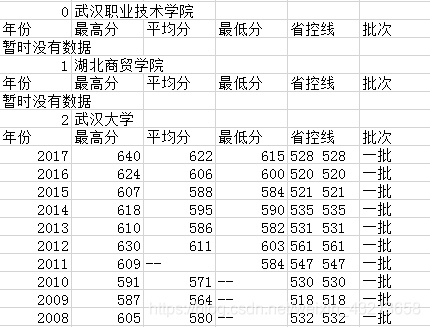
附:

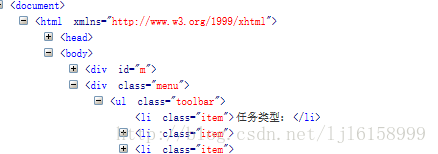
当定位其中的“任务类型”的li 标签时,这样写:.//li[text()=‘任务类型:’]
如果想使用contains(可以只指定部分包含的信息):.//li[contains(text(),‘任务类’)]
当定位其中的“任务类型”的li 标签时,这样写:.//li[text()=‘任务类型:’]
如果想使用contains(可以只指定部分包含的信息):.//li[contains(text(),‘任务类’)]
这里客串一下:.//li[starts-with(text(),‘任务类’)]、.//li[strats-with(.,‘任务类’)]
看起来很完美,就这么简单?并不是!,如下:

试试定位“单次预约任务§”的li 标签,发现上面的方法失效了!
那改怎么办?不急,说他最好用,那就当然有办法,look:.//li[contains(.,‘单次预约’)]
perfect!