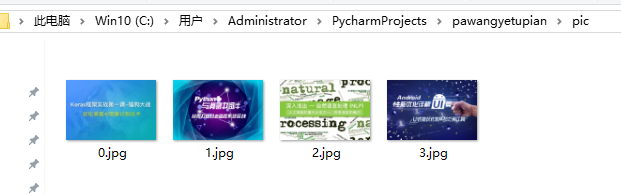
从极客学院首页爬几张图片:
一下为titita.txt内容,为极客学院首页源代码节选:
<div class="jk-uptodate"> <h2>最新课程</h2> <ul> <li class="uptodate"> <a href="/zhiye/course/135.html?type=50" target="_blank"> <img class="uptodate-img" src="https://jiuye-res.jikexueyuan.com/zhiye/showcase/attach-/20170928/8cc3edeb-0115-43ea-a46f-db6c6e9255ca.jpg" alt=""> <p class="uptodate-title">Keras框架入门实战</p> <p class="uptodate-info"> 初级 <span>|</span>5门课 </p> </a> </li> <li class="uptodate"> <a href="/zhiye/course/143.html?type=38" target="_blank"> <img class="uptodate-img" src="https://jiuye-res.jikexueyuan.com/zhiye/showcase/attach-/20171101/b12ae422-fd63-4b7d-a0d3-13c3ab4479c5.jpg" alt=""> <p class="uptodate-title">【实战】Python与消息中间件</p> <p class="uptodate-info"> 中级 <span>|</span>4门课 </p> </a> </li> <li class="uptodate"> <a href="/zhiye/course/134.html?type=50" target="_blank"> <img class="uptodate-img" src="https://jiuye-res.jikexueyuan.com/zhiye/showcase/attach-/20170928/85a3364e-47a3-41df-b5c8-daf48a57b7cd.jpg" alt=""> <p class="uptodate-title">深入浅出 — 自然语言处理</p> <p class="uptodate-info"> 初级 <span>|</span>8门课 </p> </a> </li> <li class="uptodate"> <a href="/zhiye/course/145.html?type=18" target="_blank"> <img class="uptodate-img" src="https://jiuye-res.jikexueyuan.com/zhiye/showcase/attach-/20171123/9625ede8-31e9-4edc-93e7-74bf5b752585.jpg" alt=""> <p class="uptodate-title">Android性能优化-UI篇</p> <p class="uptodate-info"> 中级 <span>|</span>7门课 </p> </a> </li> </ul> </div>
爬图片的Python程序如下:
import re import requests f=open('titita.txt','r') f1=f.read() f.close() htmls=re.findall('<img class="uptodate-img" src="(.*?)" alt="">',f1,re.S) i=0 for each in htmls: print('nowdoloading:'+each) pic=requests.get(each) fp=open('pic\\'+str(i)+'.jpg','wb') fp.write(pic.content) fp.close i+=1 #之前没安装requests,要新建项目
Pycharm输出为:
nowdoloading:https://jiuye-res.jikexueyuan.com/zhiye/showcase/attach-/20170928/8cc3edeb-0115-43ea-a46f-db6c6e9255ca.jpg
nowdoloading:https://jiuye-res.jikexueyuan.com/zhiye/showcase/attach-/20171101/b12ae422-fd63-4b7d-a0d3-13c3ab4479c5.jpg
nowdoloading:https://jiuye-res.jikexueyuan.com/zhiye/showcase/attach-/20170928/85a3364e-47a3-41df-b5c8-daf48a57b7cd.jpg
nowdoloading:https://jiuye-res.jikexueyuan.com/zhiye/showcase/attach-/20171123/9625ede8-31e9-4edc-93e7-74bf5b752585.jpg
爬到的图片在资源管理器中显示为: