简介
这里介绍一下Python的图像处理,其中使用了比较常见的库,一个是opencv另一个是PIL,都是功能很强大的图像处理库。
这算是我的一篇笔记文章,以往以后忘记。
首先介绍一下基本的图片操作,然后给大家一个OCR手写识别的例子。现在网络上卷积网络识别手写数字的代码简直多的不得了,我使用SVM和KNN进行判断分类,准确率最好可以达到1.8%。
图片基本操作
灰度转换
im = Image.open('test.jpg')
im_grayscale = im.convert("L")
plt.imshow(im_grayscale)
# im_grayscale.save('test_grayscale.jpg')
底片模式
import numpy as np
a = np.array(Image.open('test.jpg').convert('L'))
b = 255 - a
im_convert = Image.fromarray(b.astype('uint8'))
plt.imshow(im_convert)
filter
from PIL import ImageFilter
im3 = Image.open('test.jpg')
im3_tmp = im3.filter(ImageFilter.CONTOUR)
plt.imshow(im3_tmp)
opencv中的基本操作
import cv2 as cv
import matplotlib.pyplot as plt
img = cv.imread('test.jpg', 0)
# 显示
cv.imshow('image', img)
cv.waitKey(0)
cv.destoryAllWindows()
# 写
cv.imwrite('newImg.png', img)
图片属性
import cv2 as cv
img = cv.imread('test.jpg')
print(img.shape, img.size, img.dtype)
图片缩放
import numpy as np
import cv2 as cv
img = cv.imread('test.jpg')
smaller = cv.resize(img, None, fx=0.5, fy=0.5, interpolation=cv.INTER_CUBIC)
height, width = img.shape[:2]
bigger = cv.resize(img, (2 * height, 2 * width), interpolation=cv.INTER_CUBIC)
cv.imshow('smaller', smaller)
cv.waitKey(0)
仿射变换
仿射函数

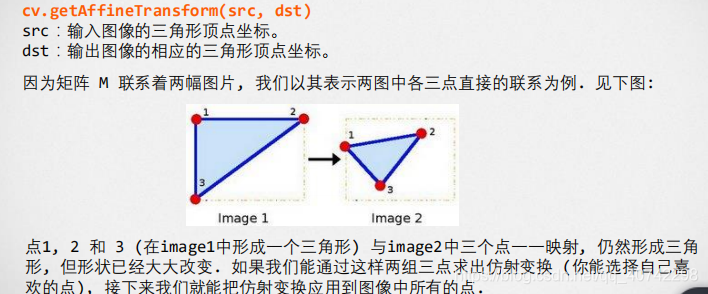
# 1.0
img = cv.imread('test.jpg',0)
rows,cols = img.shape
#Translation
M = np.float32([[1,0,100],[0,1,50]])
dst1 = cv.warpAffine(img,M,(cols,rows))
#Rotation
# cols-1 and rows-1 are the coordinate limits.
M = cv.getRotationMatrix2D(((cols-1)/2.0,(rows-1)/2.0),90,1)
dst2 = cv.warpAffine(img,M,(cols,rows))
#AffineTransform
pts1 = np.float32([[50,50],[200,50],[50,200]])
pts2 = np.float32([[10,100],[200,50],[100,250]])
M = cv.getAffineTransform(pts1,pts2)
dst3 = cv.warpAffine(img, M, (cols, rows))
cv.imshow('original',img)
cv.imshow('rotation',dst2)
cv.imshow('translation',dst1)
cv.imshow('Affine Transformation',dst3)
HSV
HSV空间是由美国的图形学专家A. R. Smith提出的一种颜色空间,HSV分别是色调
(Hue),饱和度(Saturation)和明度(Value)。
在HSV空间中进行调节就避免了直接在RGB空间中调节是还需要考虑三个通道的相关性。
OpenCV中H的取值是[0, 180),其他两个通道的取值都是[0, 256),通过HSV空间对图像进行调色更加方便:

import cv2
img = cv2.imread('test.jpg')
img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# H空间中,绿色比黄色的值高一点,所以给每个像素+15,黄色的树叶就会变绿
turn_green_hsv = img_hsv.copy()
print(turn_green_hsv.shape)
# turn_green_hsv[:, :, 0] = (turn_green_hsv[:, :, 0]+15) % 180
# turn_green_img = cv2.cvtColor(turn_green_hsv, cv2.COLOR_HSV2BGR)
# cv2.imwrite('turn_green.jpg', turn_green_img)
# # 减小饱和度会让图像损失鲜艳,变得更灰
# colorless_hsv = img_hsv.copy()
# colorless_hsv[:, :, 1] = 0.5 * colorless_hsv[:, :, 1]
# colorless_img = cv2.cvtColor(colorless_hsv, cv2.COLOR_HSV2BGR)
# cv2.imwrite('colorless.jpg', colorless_img)
# # 减小明度为原来一半
# darker_hsv = img_hsv.copy()
# darker_hsv[:, :, 2] = 0.5 * darker_hsv[:, :, 2]
# darker_img = cv2.cvtColor(darker_hsv, cv2.COLOR_HSV2BGR)
# cv2.imwrite('darker.jpg', darker_img)
Gamma变换
Gamma变换是矫正相机直接成像和人眼感受图像差别的一种常用手段,简单来说就是通过非线性
变换(因为人眼对自然的感知是非线性的)让图像从对曝光强度的线性响应变得更接近人眼感受到
的响应。Gamma压缩公式:
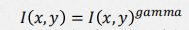
如果直方图中的成分过于靠近0或者255,可能就出现了暗部细节不足或者亮部细节丢失的情况。
一个常用方法是考虑用Gamma变换来提升/降低暗部细节。
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('test.jpg')
# 定义Gamma矫正的函数
def gamma_trans(img, gamma):
# 具体做法是先归一化到1,然后gamma作为指数值求出新的像素值再还原
gamma_table = [np.power(x / 255.0, gamma) * 255.0 for x in range(256)]
gamma_table = np.round(np.array(gamma_table)).astype(np.uint8)
# 实现这个映射用的是OpenCV的查表函数
return cv2.LUT(img, gamma_table)
# 执行Gamma矫正,小于1的值让暗部细节大量提升,同时亮部细节少量提升
img_corrected = gamma_trans(img, 2.2)
plt.imshow(img_corrected)
plt.show()
OCR
digits.png

#!/usr/bin/env python
'''
SVM and KNearest digit recognition.
Sample loads a dataset of handwritten digits from '../data/digits.png'.
Then it trains a SVM and KNearest classifiers on it and evaluates
their accuracy.
Following preprocessing is applied to the dataset:
- Moment-based image deskew (see deskew())
- Digit images are split into 4 10x10 cells and 16-bin
histogram of oriented gradients is computed for each
cell
- Transform histograms to space with Hellinger metric (see [1] (RootSIFT))
[1] R. Arandjelovic, A. Zisserman
"Three things everyone should know to improve object retrieval"
http://www.robots.ox.ac.uk/~vgg/publications/2012/Arandjelovic12/arandjelovic12.pdf
Usage:
digits.py
'''
# Python 2/3 compatibility
from __future__ import print_function
# built-in modules
from multiprocessing.pool import ThreadPool
import cv2 as cv
import numpy as np
from numpy.linalg import norm
# local modules
from common import clock, mosaic
SZ = 20 # size of each digit is SZ x SZ
CLASS_N = 10
DIGITS_FN = '../data/digits.png'
def split2d(img, cell_size, flatten=True):
h, w = img.shape[:2]
sx, sy = cell_size
cells = [np.hsplit(row, w//sx) for row in np.vsplit(img, h//sy)]
cells = np.array(cells)
if flatten:
cells = cells.reshape(-1, sy, sx)
return cells
def load_digits(fn):
print('loading "%s" ...' % fn)
digits_img = cv.imread(fn, 0)
digits = split2d(digits_img, (SZ, SZ))
labels = np.repeat(np.arange(CLASS_N), len(digits)/CLASS_N)
return digits, labels
def deskew(img):
m = cv.moments(img)
if abs(m['mu02']) < 1e-2:
return img.copy()
skew = m['mu11']/m['mu02']
M = np.float32([[1, skew, -0.5*SZ*skew], [0, 1, 0]])
img = cv.warpAffine(img, M, (SZ, SZ), flags=cv.WARP_INVERSE_MAP | cv.INTER_LINEAR)
return img
class StatModel(object):
def load(self, fn):
self.model.load(fn) # Known bug: https://github.com/opencv/opencv/issues/4969
def save(self, fn):
self.model.save(fn)
class KNearest(StatModel):
def __init__(self, k = 3):
self.k = k
self.model = cv.ml.KNearest_create()
def train(self, samples, responses):
self.model.train(samples, cv.ml.ROW_SAMPLE, responses)
def predict(self, samples):
_retval, results, _neigh_resp, _dists = self.model.findNearest(samples, self.k)
return results.ravel()
class SVM(StatModel):
def __init__(self, C = 1, gamma = 0.5):
self.model = cv.ml.SVM_create()
self.model.setGamma(gamma)
self.model.setC(C)
self.model.setKernel(cv.ml.SVM_RBF)
self.model.setType(cv.ml.SVM_C_SVC)
def train(self, samples, responses):
self.model.train(samples, cv.ml.ROW_SAMPLE, responses)
def predict(self, samples):
return self.model.predict(samples)[1].ravel()
def evaluate_model(model, digits, samples, labels):
resp = model.predict(samples)
err = (labels != resp).mean()
print('error: %.2f %%' % (err*100))
confusion = np.zeros((10, 10), np.int32)
for i, j in zip(labels, resp):
confusion[i, int(j)] += 1
print('confusion matrix:')
print(confusion)
print()
vis = []
for img, flag in zip(digits, resp == labels):
img = cv.cvtColor(img, cv.COLOR_GRAY2BGR)
if not flag:
img[...,:2] = 0
vis.append(img)
return mosaic(25, vis)
def preprocess_simple(digits):
return np.float32(digits).reshape(-1, SZ*SZ) / 255.0
def preprocess_hog(digits):
samples = []
for img in digits:
gx = cv.Sobel(img, cv.CV_32F, 1, 0) #sobel算子 边缘检测 一阶差分滤波器
gy = cv.Sobel(img, cv.CV_32F, 0, 1)
mag, ang = cv.cartToPolar(gx, gy) #极坐标变换 (模 角度)
bin_n = 16 #区间数
bin = np.int32(bin_n*ang/(2*np.pi))
bin_cells = bin[:10,:10], bin[10:,:10], bin[:10,10:], bin[10:,10:]
mag_cells = mag[:10,:10], mag[10:,:10], mag[:10,10:], mag[10:,10:]
hists = [np.bincount(b.ravel(), m.ravel(), bin_n) for b, m in zip(bin_cells, mag_cells)] #统计梯度直方图
hist = np.hstack(hists)
# transform to Hellinger kernel to quantify the similarity of two probability distributions
eps = 1e-7
hist /= hist.sum() + eps
hist = np.sqrt(hist)
hist /= norm(hist) + eps
samples.append(hist)
return np.float32(samples)
if __name__ == '__main__':
print(__doc__)
digits, labels = load_digits(DIGITS_FN) #图像切分 导入
print('preprocessing...')
# shuffle digits
rand = np.random.RandomState(321) #随机种子321
shuffle = rand.permutation(len(digits))
digits, labels = digits[shuffle], labels[shuffle] #打乱数字顺序
digits2 = list(map(deskew, digits)) #纠正图片倾斜
samples = preprocess_hog(digits2) #计算hog特征
train_n = int(0.9*len(samples)) #划分训练测试集
print(train_n)
cv.imshow('test set', mosaic(25, digits[train_n:]))
digits_train, digits_test = np.split(digits2, [train_n])
samples_train, samples_test = np.split(samples, [train_n])
labels_train, labels_test = np.split(labels, [train_n])
print('training KNearest...') #knn分类器
model = KNearest(k=4)
model.train(samples_train, labels_train)
vis = evaluate_model(model, digits_test, samples_test, labels_test)
cv.imshow('KNearest test', vis)
print('training SVM...') #SVM分类器
model = SVM(C=2.67, gamma=5.383)
model.train(samples_train, labels_train)
vis = evaluate_model(model, digits_test, samples_test, labels_test)
cv.imshow('SVM test', vis)
print('saving SVM as "digits_svm.dat"...')
model.save('digits_svm.dat')
cv.waitKey(0)
个人记录,大家共勉~