PU-Net: Point Cloud Upsampling Network
代码:https://github.com/yulequan/PU-Net
论文:请点击这里
参考:https://www.sohu.com/a/247735208_715754
一、摘要
由于点云数据的稀疏性和不规则性,所以用深度神经网络学习和分析3D点云一直以来是一个具有挑战性的工作。这篇文章中我们提出了一种数据驱动的点云上采样技术。核心思想是学习每个点的多层次特征,然后利用不同的卷积分支在特征空间的中进行扩充,然后将扩充后的特征进行分解并重建为上采样点云集。我们的网络应用于块状点云上,并且使用了联合的损失函数使得上采样后的点在潜在的曲面上分布一致。我们的方法在合成与真实的扫描数据上进行了大量的实验并且证明了它是一种比部分基础模型更加有效的基于优化的方法。实验结果显示,我们的上采样点云具有更好的一致性分布并且和潜在的曲面更加贴合。
二、模型介绍

图一是上采样网络的结构图(最好从颜色上观察):N个点输入网络,相应的有
个点输出网络,这里
是上采样率。 C表示特征通道数目。我们用插值恢复N个点不同特征层次特征然后利用卷积网络将不同层次的特征变为C. 点云特征集成模块中红色显示原来的和逐步降采样的点,绿色显示恢复的特征。我们联合使用重建损失函数和互斥损失函数用来端到端地训练上采样网络。
我们的网络架构(见图1)有四个组件:小块提取Patch Extraction、点特征嵌入Point Feature Embedding、特征扩展Feature Expansion和坐标重建 Coordinate Reconstruction。首先,我们从给定的一组先前的3D模型中提取不同比例和分布的点补丁(见2.1)。然后,点特征嵌入组件通过分层特征学习和多级特征聚集将原始3D坐标映射到特征空间。(见2.2)。之后,我们使用特征扩展组件扩展特征的数量(见2.3)并通过坐标重建组件中的一系列完全连接的层重建输出点云的3D坐标(见2.4)。
2.1 Patch Extraction
我们收集一组3D对象作为训练的先验信息。这些物体覆盖了各种各样的形状,从光滑的表面到棱角分明的形状。本质上,为了让我们的网络对点云进行上采样,它应该从对象中学习局部几何图形。这促使我们采取基于小块(patch)的方法来训练网络和学习几何语义。
详细来说,我们随机选择这些物体表面的M个点。从每个选定的点,我们生成一个一个曲面的小块(surface patch),使得这样小块上的任何点都在曲面上选定点一定的测地线距离(d)内。然后,我们使用Poisson disk采样的方法在每个小块上随机生成N个点,作为小块上的真实点分布。在我们的上采样任务中,局部和全局信息被被一起用来平滑和统一的输出。因此,我们用不同的尺寸设置d,这样我们就可以在先前的物体上提取不同比例和密度的点。
2.2 Point Feature Embedding
为了同时从小块学习局部与全局的几何信息,我们考虑了一下两种特征学习的策略,它们的优势互补:
Hierarchical feature learning
Multi-level feature aggregation
神经网络浅层特征一般反映着局部的小尺度特征,反之亦然。为了更好的上采样结果,我们采用skip-connection(参考资料ResNet)来聚集不同层的特征。但是在实验中我们发现,这样的设计让正向传播非常得不效率,因此我们直接拼接来自不同层的特征。
由于在分层特征提取中逐步对每个小块的输入(见图1中的Point Feature Embedding)进行二次下采样(
),我们通过PointNet++ 中的插值方法,首先从下采样的点特征中上采样恢复所有原始点的特征
,从而连接每个级别的点特征。具体而言,插值点
在
水平上的特征通过以下方式计算:
其中
,用距离的倒数作为权重,
是在
级别下
最近的三个临近点。我们利用1x1的卷积使得不同层面的特征具有一样的尺寸
,最后拼接这些不同层级的特征,得到最后的级联嵌入特征
。
2.3 Feature Expansion
在Point Feature Embedding之后,我们扩展了特征空间中的特征数量,这相当于扩展点的数量,因为点和特征是可以互换的。假设 的维数是 ,N是输入点的数目, 是级联嵌入特征的特征维数。特征扩展操作将输出维数为 的特征 ,其中 是上采样率, 是新的特征维数。本质上,这类似于图像相关任务中的特征上采样,这可以通过反卷积或插值来完成。然而,由于点的非规则性和无序特性,将这些操作应用于点云并不容易。
因此,我们提出了一种基于子像素卷积层的有效特征扩展操作 feature expansion operation based on the sub-pixel convolution laye。此操作可以表示为:
其中
和
是两组分开的1x1的卷积。意思就是通过两次卷积操作
和
将
先后变成
个
的特征层,再变成
个
的特征层,最后拼接成
的特征图。
是Reshape的操作,将
转换为
。
我们强调,Point Feature Embedding的特征已经通过高效的多级特征聚合封装了来自邻域点的相对空间信息,因此在执行此特征扩展操作时,我们不需要明确考虑空间信息。
值得一提的是,从每个集合中的第一卷积 生成的 个特征集合具有高相关性,这将导致最终重建的3D点彼此过于接近。因此,我们进一步为每个特征集添加另一个卷积(具有单独的权重)。由于我们训练网络学习 个特征集的r个不同卷积,这些新特征可以包含更多样的信息,从而减少它们的相关性。这种特征扩展操作可以通过对 个特征集应用分离的卷积来实现。它也可以通过计算效率更高的分组卷积来实现。
2.4 Coordinate Reconstruction
在这一部分中,我们从尺寸为 的扩展特征重建输出点的3D坐标。具体来说,我们通过一系列全连接层对每个点的特征进行三维坐标重建,特征的维度由 变为 。
三、模型训练
3.1 训练数据的生成
由于上采样点云的不确定性或模糊性,点云上采样是一个不确定的问题。给定稀疏的输入点云,有许多可行的输出分布。因此,我们没有将输入和输出作为 “correct pairs”的问题来对待。为了解决这个问题,我们提出了一种动态输入生成方案。具体而言,训练小块的ground truth分布是固定的,而输入点在每个训练时期以 的下采样速率从ground truth集中随机采样。直观地说,对于给定的稀疏输入点分布,该方案相当于模拟许多可行的输出点分布。此外,该方案可以进一步扩大训练数据集,允许我们依赖相对较小的数据集进行训练。
3.2 联合损失函数
我们提出了一种新的联合损失函数,以端到端的方式训练网络。正如我们前面提到的,函数应该鼓励生成的点以更均匀的分布位于底层物体表面上。因此,我们设计了一种结合重建损失Reconstruction loss和排斥损失Repulsion loss的联合损失函数。
Reconstruction loss
为了将点放在潜在的物体表面上,我们建议使用Earth Mover’s distance( EMD) 作为我们的重建损失,来评估预测点云
和实际点云
之间的相似性:
其中
为映射
。
实际上,Chamfer Distance(CD)是评估两个点集之间相似性的另一个候选。然而,与CD相比,EMD可以更好地捕捉形状,以鼓励输出点靠近底层物体表面。因此,我们选择在重建损失中使用EMD。
Repulsion loss
虽然具有重建损失的训练可以在底层物体表面上生成点,但是生成的点往往位于原始点附近。为了更均匀地分布生成的点,我们设计了排斥损失Repulsion loss,表示为:
其中
是上采样完了以后的输出点个数,
是点
的K近邻点,
代表二范数.
被称为排斥项,它是一个递减的函数,如果
距离他的K近邻
过于接近。为了使
只有过于接近他的K近邻点的时候才收到惩罚,我们增加了两条约束:(i)只考虑点
为
的K近邻时的情况;(ii)将快速衰减的权重函数
加入排斥损失中。
Joint Loss Function
联合损失函数具有如下的形式:
其中
代表整个网络的参数,
为正则化惩罚项。
四、实验
4.1 数据集
由于没有用于点云上采样的公共基准,我们从Visionair存储库收集了60种不同模型的数据集,从平滑的非刚性物体(如兔女郎)到陡峭的刚性物体(如椅子)。其中,我们随机选择40个用于训练,其余用于测试。我们为每个训练对象裁剪了100个小块,并且我们总共使用M=4000个小块来训练网络。对于测试对象,我们使用Monte-Carlo随机采样方法对每个对象上的5000个点进行采样作为输入。为了进一步展示我们网络的泛化能力,我们直接在SHREC15数据集上测试我们训练有素的网络,该数据集包含来自50个类别的1200个形状。详细来说,考虑到每个类别包含24个不同姿势的相似物体,我们从每个类别中随机选择一个模型进行测试。至于ModelNet40和ShapeNet,我们发现由于网格质量低(例如,孔洞、自相交等),很难从这些对象中提取补丁。因此,我们使用它们进行测试。
4.2 实现细节
每个补丁的默认点数 是4096,上采样率 是4。因此,每个输入小块有 点。为了避免过拟合,我们通过随机旋转、移动和缩放数据来扩充数据。我们在Point Feature Embedding中使用4个级别,分组半径分别为0.05、0.1、0.2和0.3,恢复特征的尺寸C为64。
排斥损失中的参数 和 分别设定为5和0.03, 和 分别设定为 和 。代码基于Tensorflow。为了优化,我们使用Adam算法对网络进行了120个epoch的训练,Batchsize为28,学习率为0.001。一般来说,在NVIDIA TITAN Xp GPU上进行培训需要大约4.5小时。
4.3 度量指标
为了定量评估输出点集的质量,我们制定了两个度量来测量输出点和ground truth之间的偏差,以及输出点的分布均匀性。对于表面偏差,我们为每个预测点 找到网格上最近的点 ,并计算它们之间的距离。然后,我们计算所有点的平均值和标准偏差,作为我们的度量之一。
至于均匀性度量,我们将D个大小相等的disk随机放在物体表面上(在我们的实验中D = 9000),并计算disk内部点数的标准偏差。我们进一步标准化每个对象的密度,然后计算测试数据集中所有对象上点集的整体均匀性。因此,我们将标准化均匀系数 normalized uniformity coefficient(NUC)与disk面积百分比
定义为:
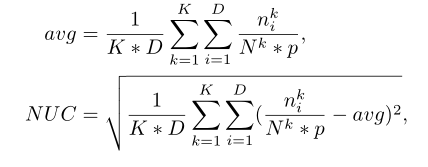
其中
是第k个物体第i个disk中点的个数,
是所有第k个物体中点的个数,K是物体的个数。p是disk区域占据整个物体表面的占比。需要注意的是我们使用的是geodesic距离而不是欧氏距离。其指标衡量的效果可以如下图参见:

4.4 模型比较

五、结论
在这篇论文中,我们提出了一个深度点云上采样网络,目标是从一组稀疏的点中生成一组更密集、更均匀的点。我们的网络是在小块级别使用多级特征聚合方式进行训练的,从而捕获局部和全局信息。我们的网络设计通过对包含非局部几何图形的单个特征进行操作来允许上下文感知的上采样,从而绕过了对点之间指定顺序的需求。我们的实验证明了我们方法的有效性。作为第一次使用深度网络的尝试,我们的方法仍然有许多局限性。毕竟,它不是为填补而设计的,所以我们的网络不能填补大的漏洞和缺失的部分。此外,我们的网络可能无法为采样严重不足的微小结构添加有意义的点。
将来,我们希望研究和开发更多的方法来处理不规则和稀疏的数据,既用于回归目的,也用于合成。一个直接的步骤是开发下采样方法。尽管下采样看起来更简单,但仍有余地设计适当的损耗和架构,最大限度地保留抽取点集中的信息。我们认为,总的来说,为不规则结构开发深度学习方法是一个可行的研究方向。