Flink WordCount
一、使用Socket传输数据
[root@bigdata111 flink-1.6.1]# bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9999
#另起一个Xshell客户端
[root@bigdata111 flink-1.6.1]# nc -l 9999
#查看日志输出
[root@bigdata111 flink-1.6.1]# vi log/flink-root-taskexecutor-1-bigdata111.out二、Java代码运行WordCount
(1)pom文件
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.12</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<hadoop.version>2.8.4</hadoop.version>
<flink.version>1.6.1</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.22</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-wikiedits_2.11</artifactId>
<version>1.6.1</version>
</dependency>
</dependencies>(2)在bigdata111中打开9000端口
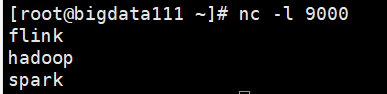
[root@bigdata111 flink-1.6.1]# nc -l 9000(3)运行以下代码,然后输入数据到以上的端口中
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
/**
* Author : WGH and wgh
* Version : 2020/5/23 $ 1.0
*/
public class WordCountStreaming {
public static void main(String[] args) throws Exception {
int port = 9000;
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> text = env.socketTextStream("192.168.1.121", port, "\n");
DataStream<WordWithCount> windowCount = text.flatMap(new FlatMapFunction<String, WordWithCount>() {
@Override
public void flatMap(String line, Collector<WordWithCount> out) throws Exception {
for(String word:line.split(" ")){
out.collect(new WordWithCount(word,1L));
}
}
}).keyBy("word")//timeWindow(Time size, Time slide)
.timeWindow(Time.seconds(2), Time.seconds(1))
.sum("count");
windowCount.print();
env.execute("Streaming word Count");
}
public static class WordWithCount{
public String word;
public long count;
public WordWithCount(){};
public WordWithCount(String word , long count){
this.word = word;
this.count = count;
}
public String toString(){
return "WordWithCount{" +
"word='" + word + '\'' +
", count=" + count +
'}';
}
}
}在端口输入:
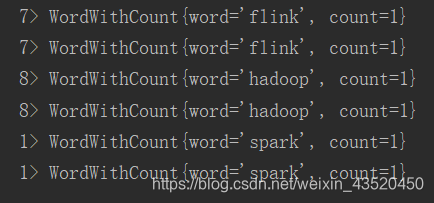
运行结果:
三、Scala代码运行WordCount
注意:导包用的
import org.apache.flink.streaming.api.scala._不然会有缺包的BUG
(1)代码如下:
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
object ScalaWordCount {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment;
val text = environment.socketTextStream("192.168.1.121",9000,'\n')
val windowCounts = text
.flatMap{w => w.split(" ")}
.map{w => WordWithCount(w,1L)}
.keyBy("word")
.timeWindow(Time.seconds(5),Time.seconds(1))
.sum("count")
windowCounts.print()
environment.execute("scala window")
}
case class WordWithCount(word: String, count: Long)
}
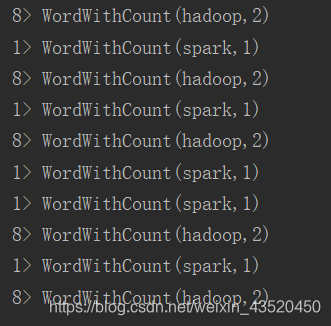
(2)在端口输入:

运行结果:
四、Flink 监控维基百科
(1)代码如下:
import org.apache.flink.api.common.functions.FoldFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.wikiedits.WikipediaEditEvent;
import org.apache.flink.streaming.connectors.wikiedits.WikipediaEditsSource;
public class WikipediaAnalysis {
public static void main(String[] args) throws Exception {
//创建一个streaming程序运行的上下文
StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();
//sowurce部分---数据来源部分
DataStream<WikipediaEditEvent> edits = see.addSource(new WikipediaEditsSource());
//获得修改词条的作者
KeyedStream<WikipediaEditEvent, String> keyedEdits = edits
.keyBy(new KeySelector<WikipediaEditEvent, String>() {
@Override
public String getKey(WikipediaEditEvent event) {
return event.getUser();
}
});
//获得修改的结果
DataStream<Tuple2<String, Long>> result = keyedEdits
.timeWindow(Time.seconds(5))
.fold(new Tuple2<>("", 0L), new FoldFunction<WikipediaEditEvent, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> fold(Tuple2<String, Long> acc, WikipediaEditEvent event) {
acc.f0 = event.getUser();
acc.f1 += event.getByteDiff();
return acc;
}
});
result.print();
see.execute();
}
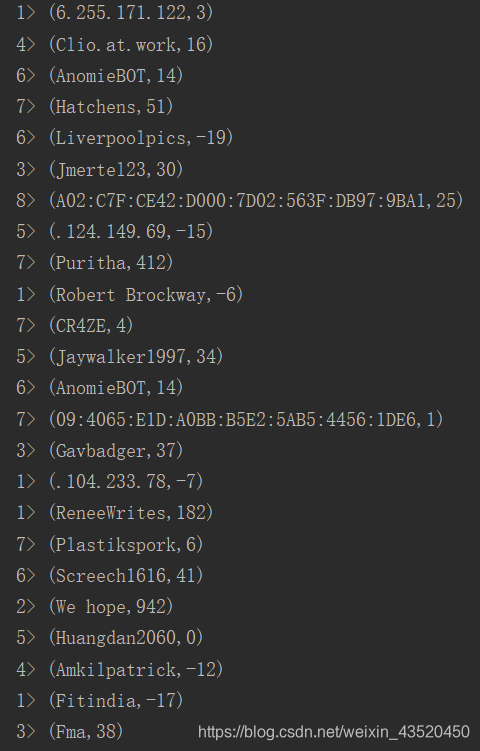
}(2)在IDEA中直接执行,稍等20S即可
五、Wiki To Kafka
(1)kafka主题创建
#在bigdata111上创建topic wiki-results
bin/kafka-topics.sh --create --zookeeper
localhost:2181 --replication-factor 1 --partitions 1 --topic wiki-results(2)在Flink的项目中创建子module,Pom如下
<dendencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-wikiedits_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
<version>1.6.1</version>
</dependency>
</dependencies>(3)代码如下
import org.apache.flink.api.common.functions.FoldFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer011;
import org.apache.flink.streaming.connectors.wikiedits.WikipediaEditEvent;
import org.apache.flink.streaming.connectors.wikiedits.WikipediaEditsSource;
public class WikipediaAnalysis {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<WikipediaEditEvent> edits = see.addSource(new WikipediaEditsSource());
KeyedStream<WikipediaEditEvent, String> keyedEdits = edits
.keyBy(new KeySelector<WikipediaEditEvent, String>() {
@Override
public String getKey(WikipediaEditEvent event) {
return event.getUser();
}
});
DataStream<Tuple2<String, Long>> result = keyedEdits
.timeWindow(Time.seconds(5))
.fold(new Tuple2<>("", 0L), new FoldFunction<WikipediaEditEvent, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> fold(Tuple2<String, Long> acc, WikipediaEditEvent event) {
acc.f0 = event.getUser();
acc.f1 += event.getByteDiff();
return acc;
}
});
result.print();
result
.map(new MapFunction<Tuple2<String,Long>, String>() {
@Override
public String map(Tuple2<String, Long> tuple) {
return tuple.toString();
}
})
.addSink(new FlinkKafkaProducer011<>("bigdata11:9092", "wiki-result", new SimpleStringSchema()));
see.execute();
}
}(4)启动Kafka的消费者
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic wiki-result六、Flink Source实战
6.1 Kafka + Flink Stream + MySQL
(1)创建student表
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(25) COLLATE utf8_bin DEFAULT NULL,
`password` varchar(25) COLLATE utf8_bin DEFAULT NULL,
`age` int(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8 COLLATE=utf8_bin;(2)插入数据
INSERT INTO `student` VALUES ('1', 'Andy','123456', '18'),
('2', 'Bndy', '000000', '17'),
('3', 'Cndy', '012345', '18'),
('4', 'Dndy', '123456', '16');
COMMIT;(3)pom文件
<dependencies>
<!--flink java-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<!--日志-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<scope>runtime</scope>
</dependency>
<!--flink kafka connector-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!--alibaba fastjson-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.51</version>
</dependency>
<!--alibaba fastjson-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.51</version>
</dependency>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
</dependencies>(4)Student Bean
public class Student {
public int id;
public String name;
public String password;
public int age;
public Student() {
}
public Student(int id, String name, String password, int age) {
this.id = id;
this.name = name;
this.password = password;
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
", password='" + password + '\'' +
", age=" + age +
'}';
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}注意:
使用lombok可能会导致其他报错
(5)SourceFromMySQL
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class SourceFromMySQL extends RichSourceFunction<Student> {
PreparedStatement ps;
private Connection connection;
/**
* open() 方法中建立连接,这样不用每次 invoke 的时候都要建立连接和释放连接。
*
* @param parameters
* @throws Exception
*/
@Override
public void open(Configuration parameters) throws Exception {
connection = getConnection();
String sql = "select * from student;";
ps = this.connection.prepareStatement(sql);
}
/**
* 程序执行完毕就可以进行,关闭连接和释放资源的动作了
*
* @throws Exception
*/
@Override
public void close() throws Exception {
if (connection != null) { //关闭连接和释放资源
connection.close();
}
if (ps != null) {
ps.close();
}
}
/**
* DataStream 调用一次 run() 方法用来获取数据
*
* @param ctx
* @throws Exception
*/
@Override
public void run(SourceContext<Student> ctx) throws Exception {
ResultSet resultSet = ps.executeQuery();
while (resultSet.next()) {
Student student = new Student(
resultSet.getInt("id"),
resultSet.getString("name").trim(),
resultSet.getString("password").trim(),
resultSet.getInt("age"));
ctx.collect(student);
}
}
@Override
public void cancel() {
}
private static Connection getConnection() {
Connection con = null;
try {
Class.forName("com.mysql.jdbc.Driver");
con = DriverManager.getConnection("jdbc:mysql://bigdata11:3306/Andy?useUnicode=true&characterEncoding=UTF-8", "root", "000000");
} catch (Exception e) {
}
return con;
}
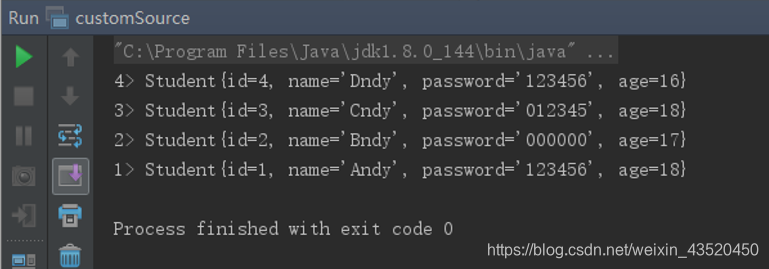
}(6)自定义Source的main方法
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class customSource {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.addSource(new SourceFromMySQL()).print();
env.execute("Flink add data sourc");
}
}
6.2 Flink Stream + Kafka
(1)pom文件如下
<dependencies>
<!--flink java-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<!--日志-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<scope>runtime</scope>
</dependency>
<!--flink kafka connector-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!--alibaba fastjson-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.51</version>
</dependency>
<!--alibaba fastjson-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.51</version>
</dependency>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
(2)Bean
import lombok.*;
import java.util.Map;
public class Metric {
private String name;
private long timestamp;
private Map<String, Object> fields;
private Map<String, String> tags;
public Metric() {
}
public Metric(String name, long timestamp, Map<String, Object> fields, Map<String, String> tags) {
this.name = name;
this.timestamp = timestamp;
this.fields = fields;
this.tags = tags;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public long getTimestamp() {
return timestamp;
}
public void setTimestamp(long timestamp) {
this.timestamp = timestamp;
}
public Map<String, Object> getFields() {
return fields;
}
public void setFields(Map<String, Object> fields) {
this.fields = fields;
}
public Map<String, String> getTags() {
return tags;
}
public void setTags(Map<String, String> tags) {
this.tags = tags;
}
}(3)Kafkautils
import com.alibaba.fastjson.JSON;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
public class KafkaUtils {
public static final String broker_list = "bigdata11:9092";
// kafka topic
public static final String topic = "metric";
//key 序列化
public static final String KEY = "org.apache.kafka.common.serialization.StringSerializer";
//value 序列化
public static final String VALUE = "org.apache.kafka.common.serialization.StringSerializer";
public static void writeToKafka() throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", broker_list);
props.put("key.serializer", KEY);
props.put("value.serializer", VALUE);
KafkaProducer producer = new KafkaProducer<String, String>(props);
Metric metric = new Metric();
metric.setName("mem");
long timestamp = System.currentTimeMillis();
metric.setTimestamp(timestamp);
Map<String, Object> fields = new HashMap<>();
fields.put("used_percent", 90d);
fields.put("max", 27244873d);
fields.put("used", 17244873d);
fields.put("init", 27244873d);
Map<String, String> tags = new HashMap<>();
tags.put("cluster", "Andy");
tags.put("host_ip", "192.168.1.51");
metric.setFields(fields);
metric.setTags(tags);
ProducerRecord record = new ProducerRecord<String, String>(topic, null, null, JSON.toJSONString(metric));
producer.send(record);
System.out.println("发送数据: " + JSON.toJSONString(metric));
producer.flush();
}
public static void main(String[] args) throws InterruptedException {
while (true) {
Thread.sleep(300);
writeToKafka();
}
}
}(4)main
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011;
import java.util.Properties;
public class Main {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
props.put("bootstrap.servers", "bigdata11:9092");
props.put("zookeeper.connect", "bigdata11:2181");
props.put("group.id", "metric-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); //key 反序列化
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "earliest"); //value 反序列化
DataStreamSource<String> dataStreamSource = env.addSource(new FlinkKafkaConsumer011<>(
"metric", //kafka topic
new SimpleStringSchema(), // String 序列化
props)).setParallelism(1);
dataStreamSource.print(); //把从 kafka 读取到的数据打印在控制台
env.execute("Flink add data source");
}
}注意:
kafka主题会自动创建Topic,无须手动创建。