Flink 是一个针对流数据和批数据的分布式处理引擎。它主要是由 Java 代码实现。
具体见官网介绍,我就不多说了
https://flink.apache.org/
根据自己hadoop和scala的版本安装对应版本的Flink
下载好解压缩到指定目录,cd进去bin目录
下面操作具体参考官方文档快速启动
https://ci.apache.org/projects/flink/flink-docs-release-1.6/quickstart/setup_quickstart.html
启动本地Flink
./start-cluster.sh
浏览器输入http://localhost:8081可以看到UI界面

单词统计实例:
jar包所在位置(安装包自带)
依次输入:

./flink run ../examples/batch/WordCount.jar \
--input file:///home/zq/Desktop/test.txt --output file:///home/zq/Desktop/flink_wordcount_out.txt
还可以加很多参数,达到不同的效果,还能跑在YARN上,见https://ci.apache.org/projects/flink/flink-docs-release-1.6/ops/cli.html
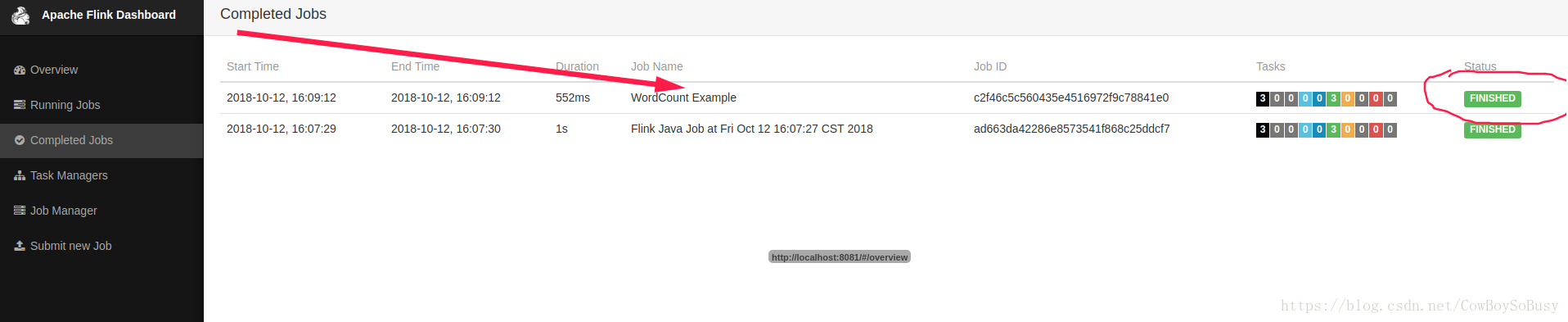
成功示范如下:
网页也显示对应job是finished


分析一波WordCount.jar这个jar包的scala源码,当然你也可以选择看java版的,看看Flink底层是怎么进行词频统计的,其实挺简单的,没有那么复杂.
源码github网址 https://github.com/apache/flink/blob/master/flink-examples/flink-examples-batch/src/main/scala/org/apache/flink/examples/scala/wordcount/WordCount.scala
我稍微注释了代码的关键部分如下

package org.apache.flink.examples.scala.wordcount
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.api.scala._
import org.apache.flink.examples.java.wordcount.util.WordCountData
/**
* Implements the "WordCount" program that computes a simple word occurrence histogram
* over text files.
*
* The input is a plain text file with lines separated by newline characters.
*
* Usage:
* {{{
* WordCount --input <path> --output <path>
* }}}
*
* If no parameters are provided, the program is run with default data from
* [[org.apache.flink.examples.java.wordcount.util.WordCountData]]
*
* This example shows how to:
*
* - write a simple Flink program.
* - use Tuple data types.
* - write and use user-defined functions.
*
*/
object WordCount {
def main(args: Array[String]) {
val params: ParameterTool = ParameterTool.fromArgs(args)
// set up execution environment
val env = ExecutionEnvironment.getExecutionEnvironment
// make parameters available in the web interface
// --input后接参数,代表分析的源文件位置
env.getConfig.setGlobalJobParameters(params)
val text =
if (params.has("input")) {
env.readTextFile(params.get("input"))
} else {
println("Executing WordCount example with default input data set.")
println("Use --input to specify file input.")
env.fromCollection(WordCountData.WORDS)
}
//核心代码,与Spark里面的分析代码意图一致
//flatMap的作用是将两层及以上的list推成一层
val counts = text.flatMap { _.toLowerCase.split("\\W+") filter { _.nonEmpty } }
.map { (_, 1) }
.groupBy(0)
.sum(1)
// --output后接参数,代表结果输出文件位置,如果没有这个参数会默认打印在终端上
if (params.has("output")) {
counts.writeAsCsv(params.get("output"), "\n", " ")
env.execute("Scala WordCount Example")
} else {
println("Printing result to stdout. Use --output to specify output path.")
counts.print()
}
}
}
核心代码
val counts = text.flatMap { _.toLowerCase.split("\\W+") filter { _.nonEmpty } }
.map { (_, 1) }
.groupBy(0)
.sum(1)
感觉Scala的代码风格是真的简洁优雅,哈哈
最后是结束本地Flink进程
./stop-cluster.sh