背景
Flink在消费到Kafka的数据后,我们经常会把数据转成POJO对象,方便后面对数据的处理,但是每个POJO类型是不一样的,每次需要新开发一个反序列化的类,这样就会有大量重复的代码,怎么实现一个通胀的反序列化类解决呢?
另一个场景,当flink同时订阅多个kafka的topic时,我们需要根据不同的topic做不同的逻辑处理,来源topic_A的数据,设置pojo的一个属性为1,来源topic_B的数据,设置POJO的属性为2,这要怎么处理呢?
方法
以上两个问题其实都只要实现KafkaDeserializationSchema这个接口就可以解决问题。
1、通用型反序列化
/**
* @desc 自定义实现kafka的消息反序列化
* @throws
*/
public class CustomKafkaDeserializationSchema<T> implements KafkaDeserializationSchema<T> {
@Override
public boolean isEndOfStream(T nextElement) {
return false;
}
@Override
public T deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception {
TypeReference<T> MAP_TYPE_REFERENCE =new TypeReference<T>(){};
T bTrack = JSON.parseObject(record.value(),MAP_TYPE_REFERENCE.getType());
return bTrack;
}
@Override
public TypeInformation<T> getProducedType() {
return TypeInformation.of(new TypeHint<T>() {
@Override
public TypeInformation<T> getTypeInfo() {
return super.getTypeInfo();
}
});
}
}2、自定义序列化
// kafka数据源
DataStreamSource<POJO> stream = env.addSource(
new FlinkKafkaConsumer<POJO>(topics, new CustomKafkaDeserializationSchema<POJO>(), PropertyFileUtils.readProFile("kafka.properties"))
.setCommitOffsetsOnCheckpoints(true)
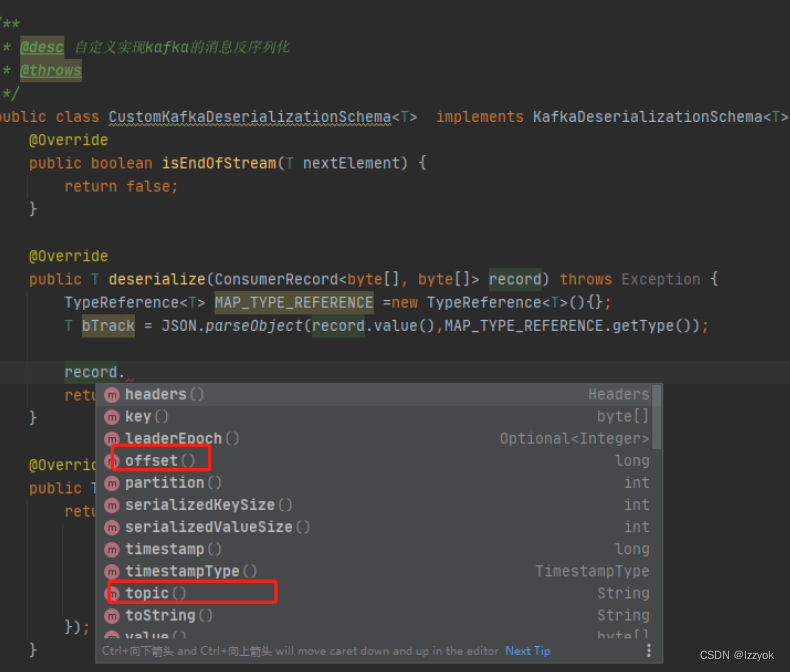
.setStartFromLatest());3、如果需要获取kafka相关信息,如下图方法就可以读取到