
1.概述
我们从一个简单的问题开始:在 Flink UI 中调查某个作业的子任务时,关于每个子任务处理的数据量,你可能会遇到如下这种奇怪的情况。
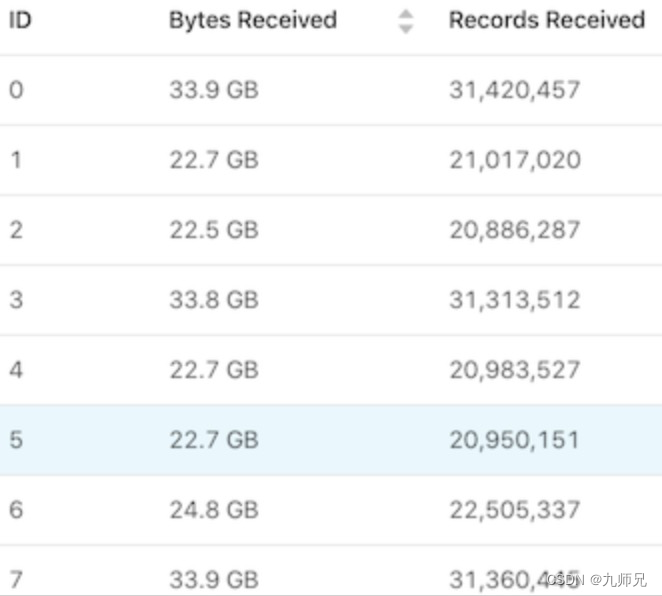
每个子任务的工作负载并不均衡
这表明每个子任务的算子没有收到相同数量的 Key Groups,它代表所有可能的 key 的一部分。如果一个算子收到了 1 个 Key Group,而另外一个算子收到了 2 个,则第二个子任务很可能需要完成两倍的工作。查看 Flink 的代码,我们可以找到以下函数:
* // 根据 maxParallelism、算子的并行度 parallelism 和 keyGroupId,
* // 计算 keyGroupId 对应的 subtask 的 index
*/
public static int computeOperatorIndexForKeyGroup(
int maxParallelism, int parallelism, int keyGroupId) {
return keyGroupId * parallelism / maxParallelism;
}
其目的是将所有 Key Groups 分发给实际的算子。Key Groups 的总数由 maxParallelism 参数决定,而算子的数量和 parallelism 相同。这里最大的问题是 maxParallelism 的默认值,它默认等于 operatorParallelism + (operatorParallelism / 2) [4]。假如我们设置 parallelism 为10,那么 maxParallelism 为 15 (实际最大并发度值的下限是 128 ,上限是 32768,这里只是为了方便举例)。这样,根据上面的函数,我们可以计算出哪些算子会分配给哪些 Key Group。
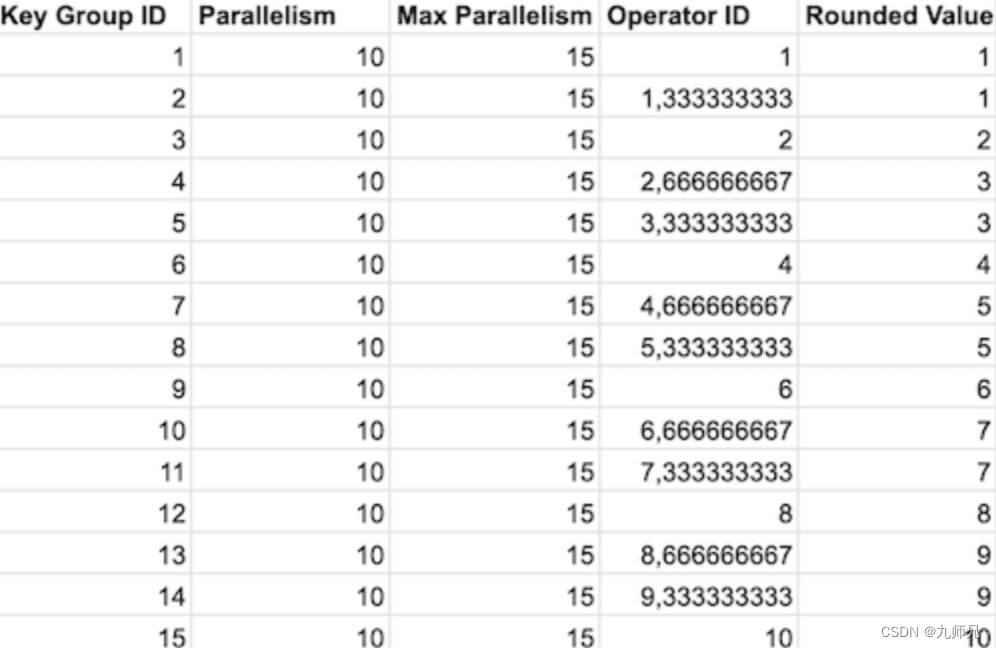
在默认配置下,部分算子分配了两个 Key Group,部分算子只分配了 1 个
解决这个问题非常容易:设置并发度的时候,还要为 maxParallelism 设置一个值,且该值为 parallelism 的倍数。这将让负载更加均衡,同时方便以后扩展。
搜嘎斯奈,我说我们公司的代码有一段是计算最大并行度的,然后设置了这个值,当初一直没找到相关的解释,也没去问,实在是不该呀。