MNIST是一个非常有名的手写数字识别数据集,在很多资料中,这个数据集都会被用作深度学习的入门案例。
MNIST数据集是NIST数据集的一个子集,它包含了60000张图片作为训练数据,10000张图片作为测试数据。在MNIST数据集中的每一张图片都代表了0~9中的一个数字。图片的大小都为28x28,且数字都会出现在图片的正中间。

数字图片及其像素矩阵:(MNIST数据集中图片的像素大小为28x28,为了更清楚的展示,图中显示的是14x14矩阵)

MNIST提供了四个文件:
train-images-idx3-ubyte.gz (训练图像数据60000个)
train-labels-idx1-ubyte.gz (训练图像数据标签60000个)
t10k-images-idx3-ubyte.gz (测试图像数据10000个)
t10k-labels-idx1-ubyte.gz (测试图像数据标签10000个)
PyTorch和TensorFlow都内置mnist数据集。
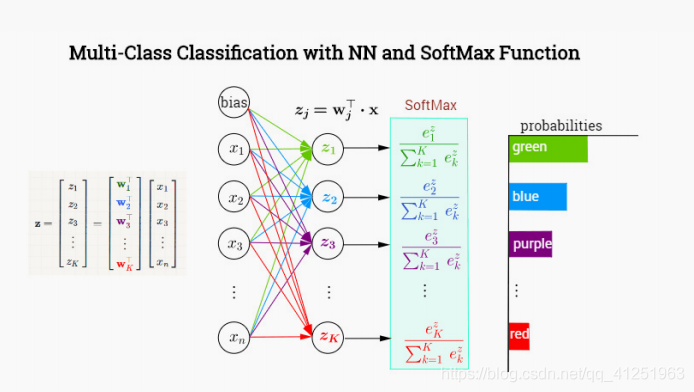
多分类问题,loss函数使用一个更加复杂的函数,叫交叉熵。
softmax
sigmoid函数可以将任何一个值转化到0~1之间,对于一个二分类问题,这样就足够了,如果不属于第一类,那么必定属于第二类,所以只需要用一个值来表示其属于其中一类概率,但是对于多分类问题,需要知道其属于每一类的概率,这个时候需要softmax函数。
MNIST
import numpy as np
import torch
from torchvision.datasets import mnist#导入pytorch内置的mnist数据集
from torch import nn
from torch.autograd import Variable
#使用内置函数下载mnist数据集
train_set=mnist.MNIST('/data',train=True,download=True)
test_set=mnist.MNIST('/data',train=False,download=True)
#查看其中的一个数据集
a_data,a_label=train_set[0]
print(a_data)
print(a_label)下载完后的文件:




#这里读入的数据是PIL库中的格式,可以非常方便地将其转化为numpy array
a_data=np.array(a_data,dtype='float32')
print(a_data.shape)
#我们可以看到这种图片的大小是28X28
print(a_data)
完整代码:
import numpy as np
import torch
from torchvision.datasets import mnist#导入pytorch内置的mnist数据集
from torch import nn
from torch.autograd import Variable
import matplotlib.pyplot as plt
#我们可以将数组展示出来,里面的0就表示黑色,255表示白色
#对于神经网络,我们第一层的输入就是28*28=784,所以必须将得到的数据做一个变换
#使用reshape将他们拉平成一个一维向量
def data_tf(x):
x=np.array(x,dtype='float32')/255
x=(x-0.5)/0.5#标准化
x=x.reshape((-1,))#拉平
x=torch.from_numpy(x)
return x
train_set=mnist.MNIST('data',train=True,transform=data_tf,download=True)#重新载入数据集,申明定义的数据变换
test_set=mnist.MNIST('data',train=False,transform=data_tf,download=True)
a,a_label=train_set[0]
print(a.shape)
print(a_label)
#使用pytorch自带的DataLoader定义一个数据迭代器
from torch.utils.data import DataLoader
train_data=DataLoader(train_set,batch_size=64,shuffle=True)
test_data=DataLoader(test_set,batch_size=128,shuffle=False)
#使用这样的数据迭代器是非常有必要的,如果数据量太大,就无法一次将他们全部读入内存,所以需要使用Python迭代器,每次生成一个批次的数据
a,a_label=next(iter(train_data))
print(a.shape)
print(a_label.shape)
#使用Sequential定义4层神经网络
net=nn.Sequential(
nn.Linear(784,400),
nn.ReLU(),
nn.Linear(400,200),
nn.ReLU(),
nn.Linear(200,100),
nn.ReLU(),
nn.Linear(100,10)
)
#交叉熵在pyTorch中已经内置了,交叉熵的数值稳定性更差,所以内置的函数
#帮我们解决了这个问题
#定义loss函数
criterion=nn.CrossEntropyLoss()
optimizer=torch.optim.SGD(net.parameters(),1e-1)#使用随机梯度下降,学习率0.1
#开始训练
losses=[]
acces=[]
eval_losses=[]
eval_acces=[]
for e in range(20):
train_loss=0
train_acc=0
net.train()
for im,label in train_data:
im=Variable(im)
label=Variable(label)
#前向传播
out=net(im)
loss=criterion(out,label)
#反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
#记录误差
train_loss+=loss.item()
#计算分类的准确率
_,pred=out.max(1)
num_correct=(pred==label).sum().item()
acc=num_correct/im.shape[0]
train_acc+=acc
losses.append(train_loss/len(train_data))
acces.append(train_acc/len(train_data))
#在测试集上检验效果
eval_loss=0
eval_acc=0
net.eval()#将模型改为预测模式
for im,label in test_data:
im=Variable(im)
label=Variable(label)
out=net(im)
loss=criterion(out,label)
#记录误差
eval_loss+=loss.item()
#记录准确率
_,pred=out.max(1)
num_correct=(pred==label).sum().item()
acc=num_correct/im.shape[0]
eval_acc+=acc
eval_losses.append(eval_loss/len(test_data))
eval_acces.append(eval_acc/len(test_data))
print('epoch:{},Train Loss:{:.6f},Train Acc:{:.6f},Eval Loss:{:.6f},Eval ACC:{:.6f}'
.format(e,train_loss/len(train_data),train_acc/len(train_data),
eval_loss/len(test_data),eval_acc/len(test_data)))
#画出loss曲线和准确率曲线
plt.title("train loss")
plt.plot(np.arange(len(losses)),losses)
plt.show()
plt.plot(np.arange(len(acces)),acces)
plt.title('train acc')
plt.show()
plt.plot(np.arange(len(eval_losses)),eval_losses)
plt.title('test loss')
plt.show()
plt.plot(np.arange(len(eval_acces)),eval_acces)
plt.title('test acc')
plt.show()
运行结果:




