普通的 pooling,是 channel 之间独立做的,只是在每个 feature map 空间维度上去做pooling,pooling 完 channel 数是不会改变的。
cross channel pooling,是在 channel 维度上去做,比如现在有 50 个 feature map,想通过 cross channel pooling 去得到5个feature map。做法就是把 50 个 feature map 分成 5 组,每组内的 10 个 feature map 在 channel 维度上做 pooling 生成 1 个新的 feature map。
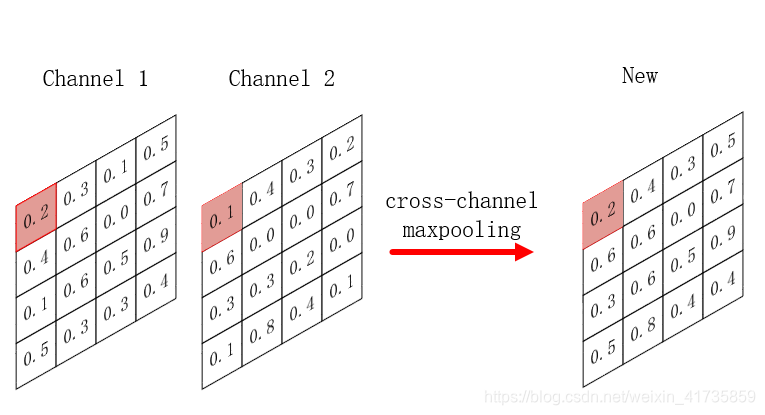
如上图所示:对 channel 1 的 4x4 特征图和 channel 2 的 4x4 特征图使用最大池化做 cross channel pooling,得到一张 4x4 的特征图。两个通道的左上角分别为 0.2,0.1,最大池化后,选出0.2。同理,依此类推,右下角是 0.4 和 0.1 比较,选出0.4。
cross channel pooling 是操作不同通道的同一个位置,而普通 pooling 是操作同一通道不同位置。
cross channel pooling 和1x1卷积的关系,一般 1x1 既可以用来升维也可以降维,但是 cross channel pooling 只能用来降维,而且没有参数可以学习,1x1 卷积相当于channel 之间的加权和。
代码实现:
import torch
import numpy as np
from torch.autograd import Variable
from torch.nn.modules.module import Module
import torch.nn.functional as F
class my_MaxPool2d(Module):
def __init__(self, kernel_size, stride):
super(my_MaxPool2d, self).__init__()
self.kernel_size = kernel_size
self.stride = stride
def forward(self, input):
# 如维度为(3, 6, 4, 4) 交换为 (3, 4, 4, 6)
print('input:',input.shape)
input = input.transpose(3,1)
print('input.transpose:',input.shape)
input = F.max_pool2d(input, self.kernel_size, self.stride)
print("max_pool.",input.shape)
input = input.transpose(3,1).contiguous()
print("final_cross",input.shape)
return input
# kernel 和 sride 都是二维的。表示不同方向池化尺寸不一样。
m = my_MaxPool2d((1, 2), stride=(1, 2))
input = Variable(torch.randn(3, 6, 4, 4))
output = m(input)'''
input: torch.Size([3, 6, 4, 4])
input.transpose: torch.Size([3, 4, 4, 6])
max_pool. torch.Size([3, 4, 4, 3])
final_cross torch.Size([3, 3, 4, 4])
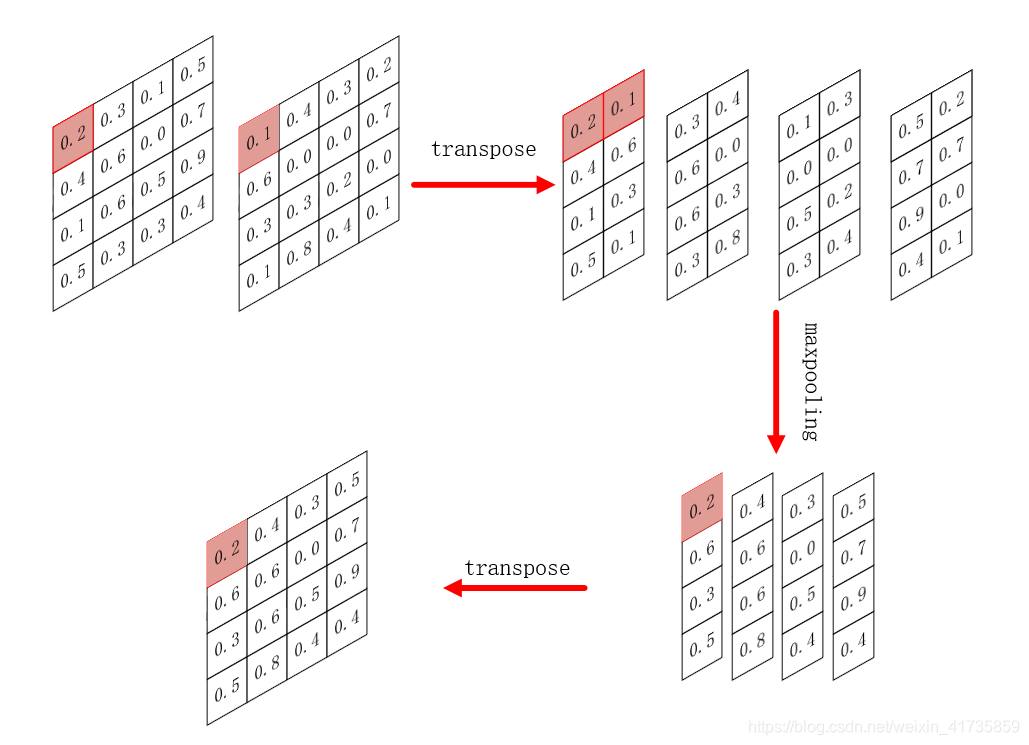
'''通过 cross channel pooling 后,原本 shape 为 [3, 6, 4, 4] 的 feature 变为 shape 为 [3, 3, 4, 4] 的 feature。其中,需要经过两次transpose转换维度,代码中 transpose 函数,参考另一篇博客:pytorch中reshape()、view()、permute()、transpose()总结。中间过程图示:
参考链接:
Cross channel pooling的理解?