什么是索引
众所周知,索引是用来加快数据库查询速度的,试想一条sql语句:select * from my_table where id = 10000,如果没有索引,那么就必须要遍历整张表,直到找到id=10000这一行数据,这样做无疑是低效的。而如果在id这一列上建立了索引,就可在索引中查找。由于索引是经过某种算法优化过的,因而查找次数要少的多。可以极大的提高查询速度。
索引的分类
普通索引:仅用来加速查询。
唯一索引:加速查询+列值唯一(允许为null)。
主键索引:加速查询+列值唯一(不允许为null),一张表只能由一个主键索引。
联合索引:多个列值组成一个索引,用于组合搜索,其效率大于索引合并。
全文索引:对文本的内容进行分词,解决判断字段是否包含的问题。(实际中使用较少)
索引的本质
mysql默认的索引方式是B+树,用户也可以选择HASH,下面依次介绍这两种方式
HASH
哈希函数会根据传入的关键字计算出其所在的位置,它会将关键字域映射到哈希表中的一个位置上。,我们在查询的时候,只需要进行一次运算后就可以找到该行数据对应的下标位置,时间复杂度为O(1),但是它有几个很明显的缺点:
- 浪费数据空间,HASH表中很多地方是没有存数据的。
- 不支持范围查询。
- 不支持排序。
基于以上几个缺点,虽然HASH进行查询时速度很快,但是Mysql不将它作为
默认索引方式。
B+树
m阶B+树的性质:
-
每个节点最多有m个子节点。
-
除根节点外,每个节点至少有m/2个子节点,注意如果结果除不尽,就向上取整,比如5/2=3。
-
根节点要么是空,要么是独根,否则至少有2个子节点。
-
有k个子节点的节点必有k个关键码。
-
叶节点的高度一致。
-
数据只存在于叶节点中。
下图给出了一个3阶的B+树的结构
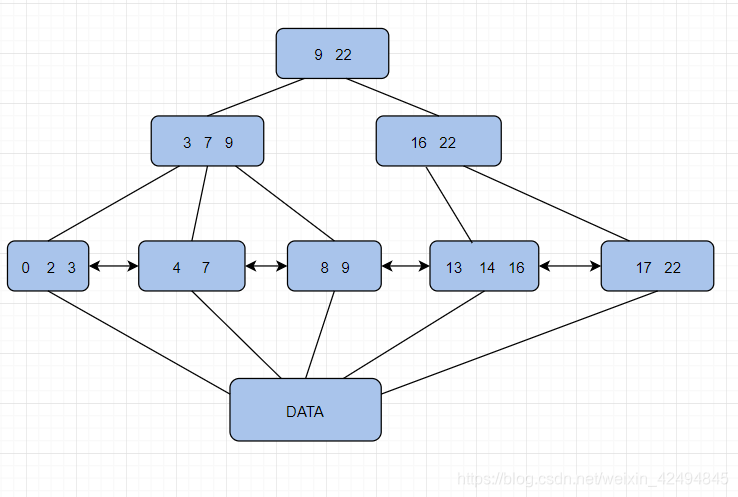
叶子节点顺序排列,数据全部存放在叶子节点中(也称为卫星数据),其余节点仅存放索引,同时叶子节点通过组成一个双向链表。
从图中可以看出,每一个子节点中的最大值都能在其父节点中找到,看着是不是有点像二叉搜索树呢?与之不同的是,B+树每一个节点都能存放多个数据。
这里举一个例子,假设我们想找大于5,小于16的数据,B+树从根节点像下找的过程如下:
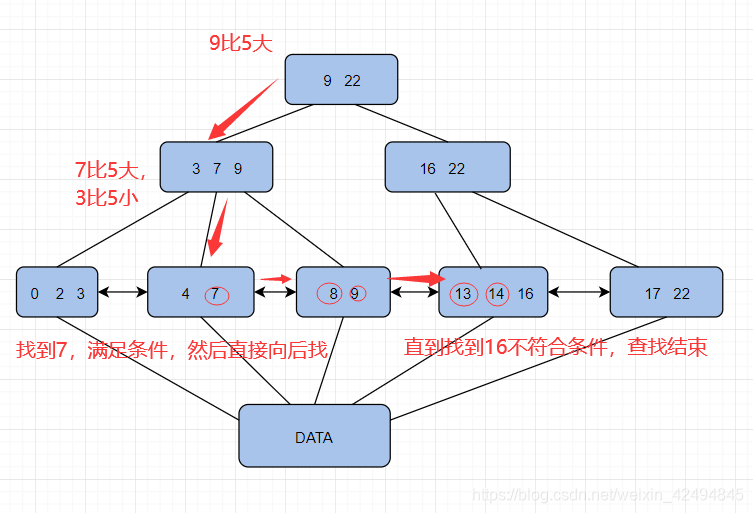
B+树的查询效率很高,而且很适合范围查询。
有点朋友可能会问了,我们应该如何选择B+树的阶数呢?
大家都知道,数据库查询的瓶颈在于磁盘IO,而数据是存在我们的磁盘上的,我们应该尽可能减少磁盘IO次数,那么应尽量把数据存在一个磁盘块中,由于磁盘块的大小一般是4KB,所以M阶B+树的M值应尽可能向它靠拢,我们一般取4KB的0.75倍。同时,由于除叶子节点外其余节点没有存卫星数据,所以这些节点能存放更多的索引。这也减小了磁盘的IO。
Mysql存储引擎
InnoDB
InnoDB是mysql默认的存储引擎,它采用聚集索引,支持事务。
这儿提到了聚集索引,那么什么是聚集索引呢?
聚集索引就是将数据文件和索引放在一起,也就是说当我们通过索引进行查询的时候,能够直接找到数据。
这里以主键ID对应的索引为例
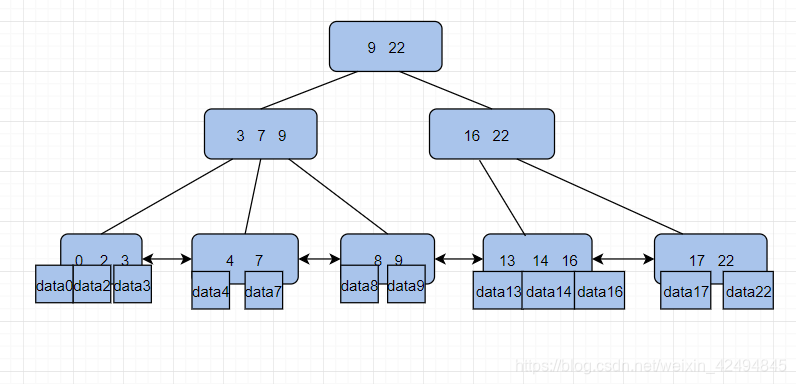
可以看到索引和数据文件是放在一起的。(这里的data指的是对应行包含所有列值的整行数据,不单单只是一个数据)
而当使用辅助索引(非主键字段建立的索引)进行查询时,索引值是和该行对应的主键值放在一起的,这就意味这查询时先找到该行主键ID,然后再通过这个主键ID值在主键的索引树下找到数据。
MyISAM
mysql也提供MyISAM存储引擎,MyISAM采用非聚集索引,查询效率高,但不支持事务。
什么是非聚集索引呢?
非聚集索引就是索引和数据是分开放的。
那么怎么通过索引找到数据呢?
请看下面的索引树
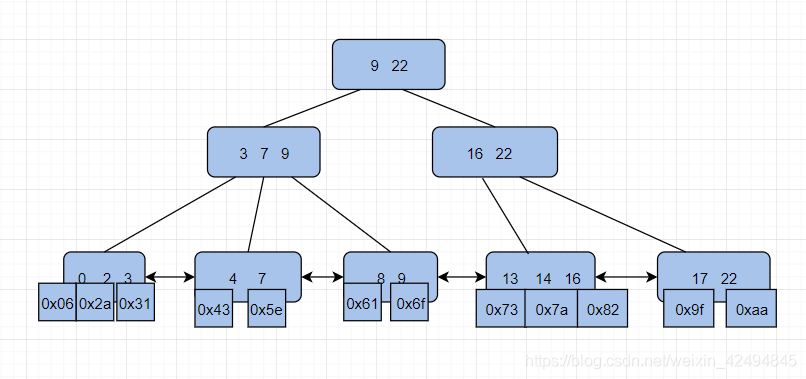
虽然数据和索引是分开的,但每一个索引下面存的是该行数据对应的地址,也就是说我们可以拿到该行数据的地址,那么直接寻址就可以找到数据。
试验
下面我们来通过一个试验直观的感受两个存储引擎的不同。
首先先创建一个数据库
create database test_db;
然后看到我的mysql安装目录的data文件夹下多了一个test_db文件夹,进入文件夹,现在文件夹是空的。
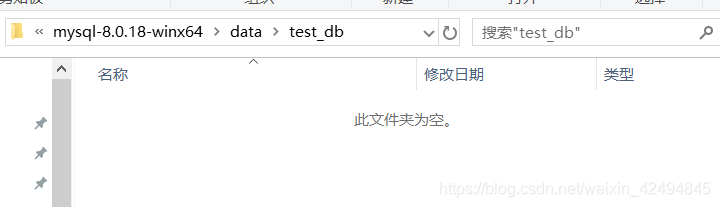
选择刚刚创建的数据库。
use test_db;
然后创建一张使用InnoDB存储引擎的表,由于mysql默认使用InnoDB,所以可以不指定引擎。
create table user1(id int primary key auto_increment,name varchar(20));
然后再看test_db文件夹。

可以看到多了一个user1.ibd文件,这个表的索引和数据是放在一个文件中的。
我们再创建一张使用MyISAM存储引擎的表,这里需要显示指定引擎。
create table user2(id int primary key auto_increment,name varchar(20))engine=myisam charset=utf8;
然后再看test_db文件夹。
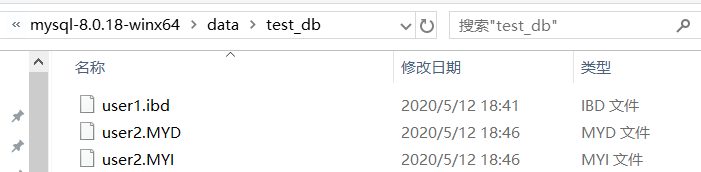
可以看到多了user2.MYD和user2.MYI
其中user2.MYD存放的的是表的数据文件,而user2.MYI存放的是表的索引文件。
结语
索引能大大的提高我们的工作效率,但索引是有开销的,当我们的数据量很小时也没有建索引的必要,希望这篇文章能让大家认识到索引的本质。