数据库索引:Index,是为了提高数据库查询效率而产生的一个对象。一个形象的比喻,有了索引的Mysql就是一辆兰博基尼,没有索引的Mysql就是一个人力三轮车。
特点:索引能提高查询的效率,但是,会降低增删改的效率,因为增删改数据后,因此导致增删改的效率会变低。所以并不是每一列都需要加索引的。
哪些列需要加索引?通常列具有唯一性的可以添加索引。主键/唯一键,Oracle默认给主键和唯一键加上了索引。
-- 创建索引
create index inx_id on tb_class(id);
create index 索引名 on 表名(列名);
-- 索引创建好后,在后续的所有的查询的where子句中,一但使用该条件,就会自动生效
select * from tb_class where id=2;-- 看着和不使用索引好像没什么区别
-- 删除索引
drop index inx_id on tb_class;
索引是帮助Mysql高效获取数据的排好序的数据结构。
索引数据结构:
二叉树
红黑树
Hash表
B-Tree
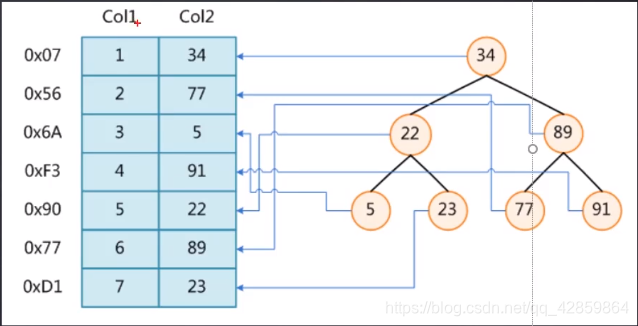
给Col2加索引就是把Col2中的数据放入某种数据结构中遍历,而未加索引Mysql的查找方式就是挨个比较
单表增加的二叉树实际上最终会变为链表,而此时如果依靠索引查询的话也是挨个比较,和该字段没有创建索引没有什么区别,故性能没有什么提高。
当二叉树差的太多,就会自动变成红黑树也就是平衡二叉树
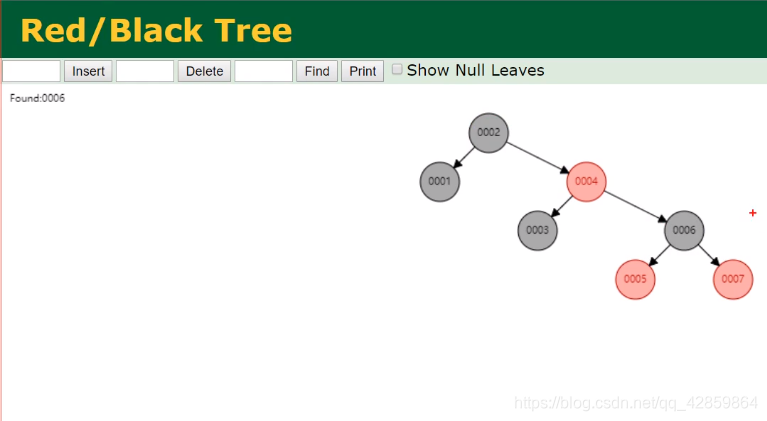
但是当数据量很大的时候,仍然会出现很大的树的高度。
那我们能不能控制树的高度,引出来B-Tree。
B-Tree
叶节点具有相同的深度,叶节点的指针为空
所有索引元素不重复
节点中的数据索引从左到右递增排序
B+Tree(B-Tree变种)
非叶子节点不存储data,只存储索引(冗余),可以放更多索引
叶子节点包含所有索引字段
叶子节点用指针链接,提高区间的访问性能
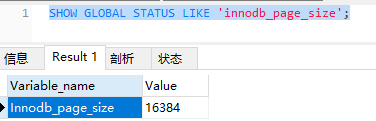
Mysql数据库的一个存储节点是16KB,那么为什么是16KB
我们知道B+Tree的深度为3,那么第一层的存储节点中每一个元素占用大小设为16B,那么第一层的存储节点可以放大概1142个元素,同理第二层节点可以放10001000,因为第三层的一个节点有打他数据我们假定一个元素占用大小为1kb,那么到第三层节点我们可以存放的元素是10001000*16=16000000个
那么B+Tree和B-Tree有什么不同?
数据库存储引擎MyISAM形容的是表
MyISAM索引文件和数据文件是分离的(非聚集)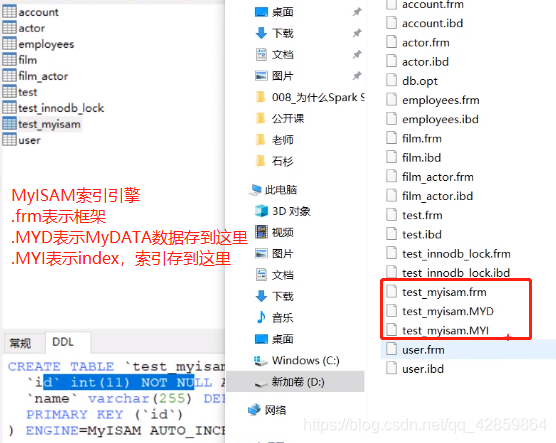
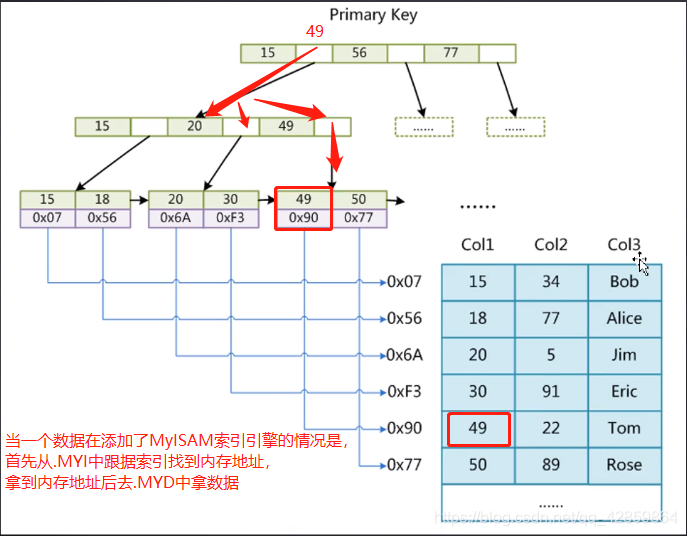
Innodb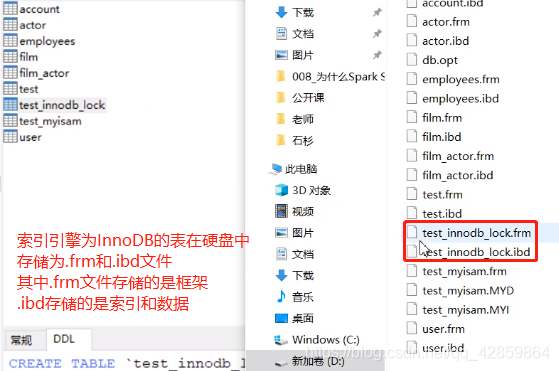
InnoDB索引实现(聚集)
表数据文件本身就是按B+Tree组织的一个索引结构文件
聚集索引-叶节点包含了完整的数据记录
为什么InnoDB必须有主键,并且推荐使用整型的自增主键?
因为InnoDB是通过主键来管理数据的,如果没有设置主键,那么InnoDB后台会去寻找一列元素唯一的值设为主键,如果没有这种列,那么InnoDB会默认创建一个列来作为主键,但是这个列我们看不到。
那么为什么会推荐使用整型自增?
首先说整型,拿uuid来做例子比较,第一点,节省磁盘内存空间,uuid是固定36位长度的字符串。第二点,查询效率,当我们遍历元素比较的时候,整型数字之间可以直接比较,但是uuid的字母需要查到char类型对应得数字再进行比较
为什么非主键索引结构叶子节点存储的是主键值(一致性和节省存储空间)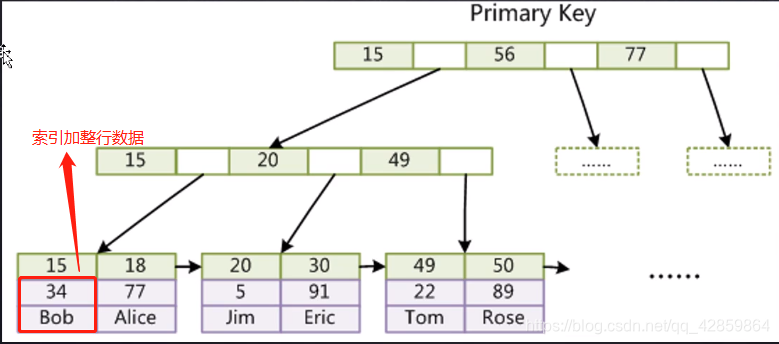
什么叫聚集索引和非聚集索引
聚集就是索引和数据存放一个文件的像InnoDB,非聚集索引就是不放到一个文件,比如说MyISAM就是放到两个文件,是拿到索引之后再去找的数据
索引方法:BTree和HASH
select * from where col1=6
HASH精确查找很快,但是不能按照范围查找,因为HASH表的特点就是无序。其实B-Tree也是按照范围查找慢,B+Tree树有个指针,当查找到6时,可以快速定位到第一个节点,从而快速确定范围。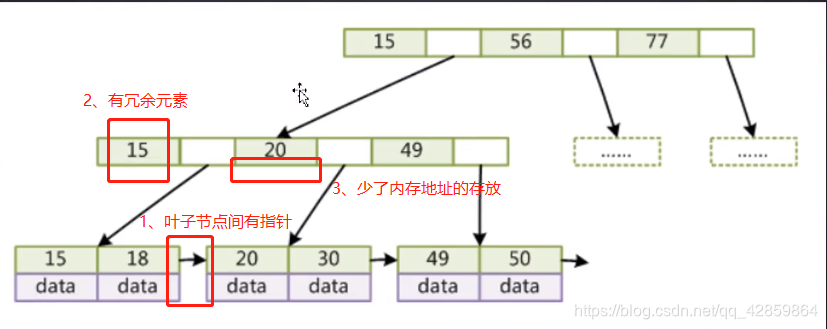
当我们此时需要插入数据8时,会发现我们之前的节点分裂并进行了树得再次平衡,对性能是有影响的,如果主键自增的话,一般就会直接在节点后边添加元素。
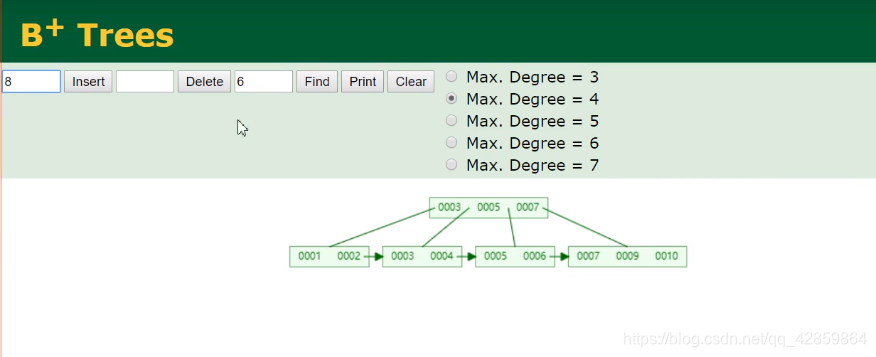
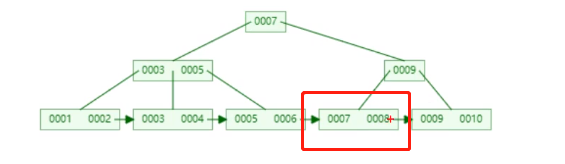
联合索引的底层存储结构
