关于InnoDB索引及相关知识的个人理解,如遇错误欢迎指正。
目录
InnoDB的索引
InnoDB的索引分为两类:
聚集索引(clustered index)
- 聚集索引的叶子节点存储行记录
- 一个InnoDB引擎的表,必须有且只有一个聚集索引
- 聚集索引的三种情况:
- 如果表定义了PK(primary key),则PK就是聚集索引;
- 如果表没有定义PK,则第一个not NULL unique列是聚集索引;
- 否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
普通索引(secondary index)
- 一个InnoDB引擎的表,可以有任意个普通索引
- 普通索引的叶子节点存储主键值(MyISAM的索引叶子节点存储记录指针,不要混淆)
- 普通索引也包含常见的索引种类:
- 唯一索引(Unique Indexes)
- 列索引(Column indexes,就是普通的INDEX)
- 联合/复合索引(Composite indexes,就是多字段的INDEX)
- 全文索引(FULLTEXT Indexes,MySQL5.6开始,InnoDB也有全文索引了)
- 空间索引(Spatial Indexes)
假设有表:
table name (
id PRIMARY KEY,
name KEY,
sex,
flag
);
其中:id是聚集索引,name是普通索引。
回表是什么
回表这个名词其实没有直接的英文翻译,我仅在《高性能MySQL》英文原版中找到几句相关的描述(大概都在第五章后半段):
“look up full rows from the table to retrieve columns”
" it will have to look up each row it finds in the index"
所以其实很简单,回表,就是表达当WHERE索引列的时候,无法直接获取到查询的列,从而导致我们需要再次回到表中去查询相应的内容,就是我们平常所说的“回表”
见下图
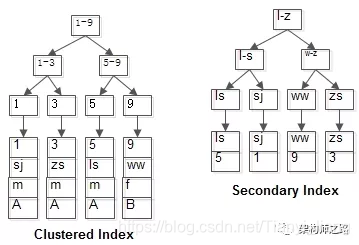
两个B+树索引分别如上图:
- id为PK(primary key),聚集索引,叶子节点存储行记录;
- name为KEY,普通索引,叶子节点存储主键值(id);
由此可见,普通索引的查询过程,需要扫码两遍索引树,这个行为也称之为回表
这里面做一个细化的区分:
- 当WHERE列是索引列的时候,SELECT该列就不需要回表
- 当WHERE列是索引列的时候,SELECT其他列就需要回表(主键查询除外,因为主键查询即可返回该行全部列,不需要回表)
- 当WHERE列没有索引的话,那就不用多提了,全表扫描
覆盖索引/索引覆盖(covering index)
以下截图来自于MySQL术语表

覆盖索引
覆盖索引是一次查询(query)便取回全部列的索引。它替代了使用索引值作为指针来查找全部表行,这种查询返回的值来自于索引结构,节省硬盘I/O。相比MyISAM,InnoDB可以将这项优化技术应用在更多的列上,因为InnoDB的普通索引还包括主键列。不过InnoDB不能应用这项技术于由事务修改的表的查询,直到事务结束
在正确的查询条件下,任何列索引(column index)或复合索引(composite index)都可以作为覆盖索引。尽可能设计索引和查询以利用这种优化技术。
回到普通索引(Secondary indexes)
上面引文有一句话让人耳目一新,就是“InnoDB secondary indexes also include the primary key columns”,InnoDB普通索引包含主键列?之前不是说主键列一般都是聚集索引吗?
这是一个语义误区,实际上MySQL官方文档对于Secondary indexes的定义是,除聚集索引以外的所有索引都称为辅助索引(或叫普通索引),见下图:

总结:也就是说,聚集索引通常为主键,但是普通索引除了包含自己的列以外,还会包含主键列的值,聚集索引在InnoDB引擎的表结构中必须要有,但是普通索引可能有任意个(0个,1个,甚至更多)
索引类型(Index types)
此索引类型非彼索引类型,所以有时候加上英文来区分定义是个很好的选择
以下是MySQL官网对于每种存储引擎所支持的索引类型:
(注意:这里看到MyISAM不支持HASH类型)
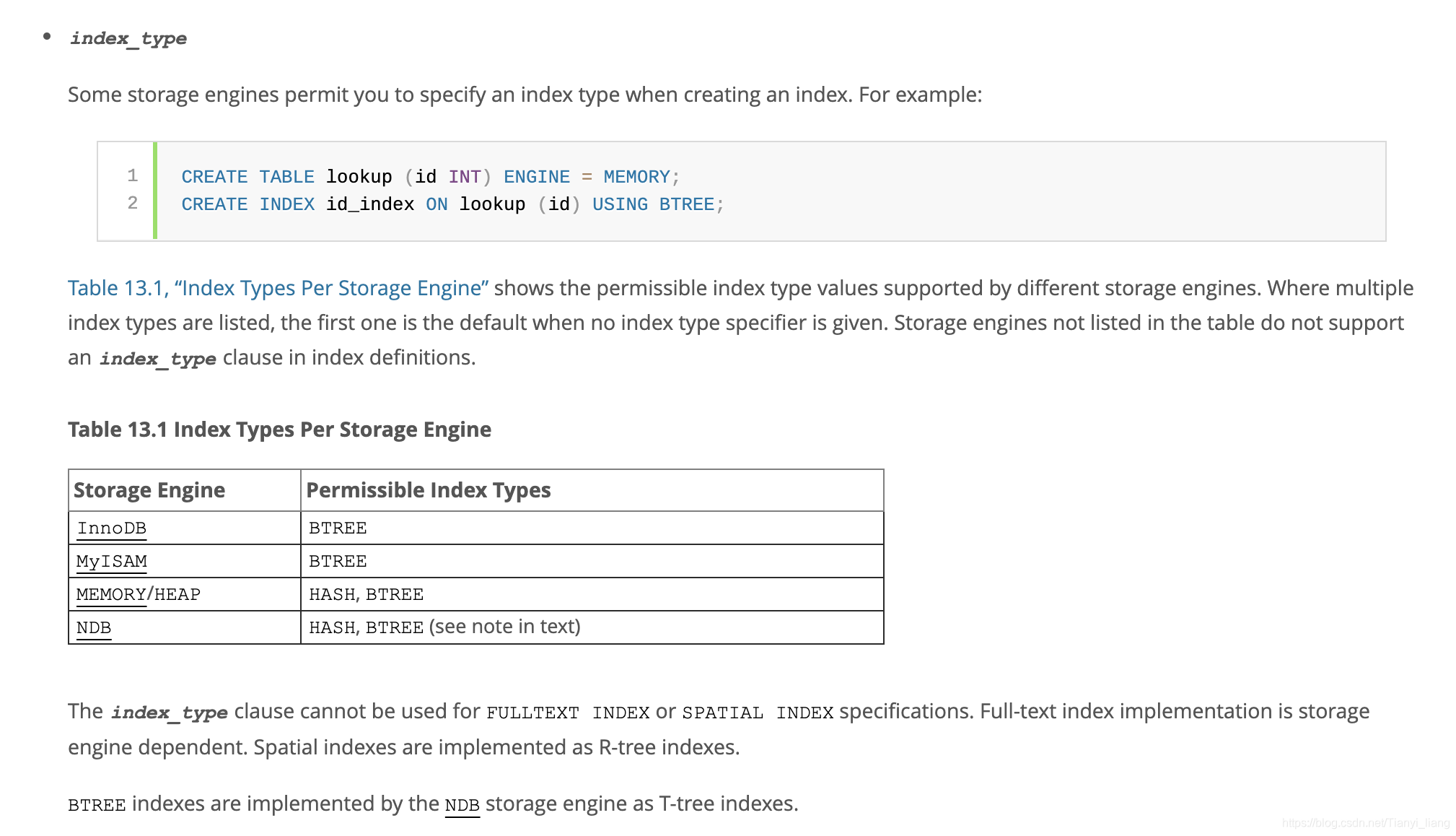
这里不翻译了,总结几个要点:
- 表中按顺序,第一个类型即为该引擎的默认类型,除非创建时指定其他的
- 表中以外的其他类型不支持使用CREATE……USING方式创建
- 全文索引不支持上述表中类型,它由存储引擎来决定
- 空间索引不支持上述表中类型,它由R-tree索引实现
面试经常遇到的提问
为什么InnoDB使用B+tree结构而不是HASH结构?
- 首先是InnoDB不支持设置为HASH结构
- 由于HASH结构数据存储没有顺序性,不好做范围查询和排序,比较适合定值查询
- B+tree很好的解决了上述问题
- B+tree是多路平衡查询树,节点是天然有序的,所以不需要做全表扫描
- (怎么个有序法?)左子节点小于父节点、父节点小于右子节点
- HASH结构索引不支持联合索引
- 说白了,除了定值查询快以外一无是处,而且当遇到不连续多处重复值的查询,更糟糕了
创建索引时需要考虑哪些点?
- 为经常查询、排序、分组的列创建索引
- 为数据量小的类型创建索引(比如各种数字类型而非字符串类型)
- 尽量选择区分度高的列,而非重复值比较多的列上创建索引(如gender、status、type)
- 在业务场景满足的条件下,唯一索引是个不错的选择
- 尽量不要在改动特别频繁的列创建索引(还是status、update_time之类的)
- 相比“%xxxx%”,“xxxx%” 是可以用到索引的
- 联合索引的创建要遵循最左前缀匹配原则
什么是最左匹配原则?
根据业务需求,where子句中使用最频繁的一列放在最左边,因为MySQL索引查询会遵循最左前缀匹配的原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。所以当我们创建一个联合索引的时候,如(key1,key2,key3),相当于创建了(key1)、(key1,key2)和(key1,key2,key3)三个索引,这就是最左匹配原则。
