一、基础知识
1.1 新建myemployees数据库


/*
Navicat Premium Data Transfer
Source Server : mysql0815
Source Server Type : MySQL
Source Server Version : 50562
Source Host : localhost:3306
Source Schema : myemployees
Target Server Type : MySQL
Target Server Version : 50562
File Encoding : 65001
Date: 06/11/2019 16:25:51
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for departments
-- ----------------------------
DROP TABLE IF EXISTS `departments`;
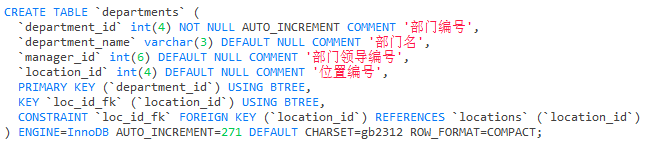
CREATE TABLE `departments` (
`department_id` int(4) NOT NULL AUTO_INCREMENT COMMENT '部门编号',
`department_name` varchar(3) CHARACTER SET gb2312 COLLATE gb2312_chinese_ci NULL DEFAULT NULL COMMENT '部门名',
`manager_id` int(6) NULL DEFAULT NULL COMMENT '部门领导编号',
`location_id` int(4) NULL DEFAULT NULL COMMENT '位置编号',
PRIMARY KEY (`department_id`) USING BTREE,
INDEX `loc_id_fk`(`location_id`) USING BTREE,
CONSTRAINT `loc_id_fk` FOREIGN KEY (`location_id`) REFERENCES `locations` (`location_id`) ON DELETE RESTRICT ON UPDATE RESTRICT
) ENGINE = InnoDB AUTO_INCREMENT = 271 CHARACTER SET = gb2312 COLLATE = gb2312_chinese_ci ROW_FORMAT = Compact;
-- ----------------------------
-- Records of departments
-- ----------------------------
INSERT INTO `departments` VALUES (10, 'Adm', 200, 1700);
INSERT INTO `departments` VALUES (20, 'Mar', 201, 1800);
INSERT INTO `departments` VALUES (30, 'Pur', 114, 1700);
INSERT INTO `departments` VALUES (40, 'Hum', 203, 2400);
INSERT INTO `departments` VALUES (50, 'Shi', 121, 1500);
INSERT INTO `departments` VALUES (60, 'IT', 103, 1400);
INSERT INTO `departments` VALUES (70, 'Pub', 204, 2700);
INSERT INTO `departments` VALUES (80, 'Sal', 145, 2500);
INSERT INTO `departments` VALUES (90, 'Exe', 100, 1700);
INSERT INTO `departments` VALUES (100, 'Fin', 108, 1700);
INSERT INTO `departments` VALUES (110, 'Acc', 205, 1700);
INSERT INTO `departments` VALUES (120, 'Tre', NULL, 1700);
INSERT INTO `departments` VALUES (130, 'Cor', NULL, 1700);
INSERT INTO `departments` VALUES (140, 'Con', NULL, 1700);
INSERT INTO `departments` VALUES (150, 'Sha', NULL, 1700);
INSERT INTO `departments` VALUES (160, 'Ben', NULL, 1700);
INSERT INTO `departments` VALUES (170, 'Man', NULL, 1700);
INSERT INTO `departments` VALUES (180, 'Con', NULL, 1700);
INSERT INTO `departments` VALUES (190, 'Con', NULL, 1700);
INSERT INTO `departments` VALUES (200, 'Ope', NULL, 1700);
INSERT INTO `departments` VALUES (210, 'IT ', NULL, 1700);
INSERT INTO `departments` VALUES (220, 'NOC', NULL, 1700);
INSERT INTO `departments` VALUES (230, 'IT ', NULL, 1700);
INSERT INTO `departments` VALUES (240, 'Gov', NULL, 1700);
INSERT INTO `departments` VALUES (250, 'Ret', NULL, 1700);
INSERT INTO `departments` VALUES (260, 'Rec', NULL, 1700);
INSERT INTO `departments` VALUES (270, 'Pay', NULL, 1700);
-- ----------------------------
-- Table structure for employees
-- ----------------------------
DROP TABLE IF EXISTS `employees`;
CREATE TABLE `employees` (
`employee_id` int(6) NOT NULL AUTO_INCREMENT COMMENT '员工编号',
`first_name` varchar(20) CHARACTER SET gb2312 COLLATE gb2312_chinese_ci NULL DEFAULT NULL COMMENT '姓',
`last_name` varchar(25) CHARACTER SET gb2312 COLLATE gb2312_chinese_ci NULL DEFAULT NULL COMMENT '名',
`email` varchar(25) CHARACTER SET gb2312 COLLATE gb2312_chinese_ci NULL DEFAULT NULL COMMENT '邮箱',
`phone_number` varchar(20) CHARACTER SET gb2312 COLLATE gb2312_chinese_ci NULL DEFAULT NULL COMMENT '电话',
`job_id` varchar(10) CHARACTER SET gb2312 COLLATE gb2312_chinese_ci NULL DEFAULT NULL COMMENT '工种编号',
`salary` double(10, 2) NULL DEFAULT NULL COMMENT '月工资',
`commission_pct` double(4, 2) NULL DEFAULT NULL COMMENT '奖金率',
`manager_id` int(6) NULL DEFAULT NULL COMMENT '领导编号',
`department_id` int(4) NULL DEFAULT NULL COMMENT '部门编号',
`hiredate` datetime NULL DEFAULT NULL COMMENT '入职时间',
PRIMARY KEY (`employee_id`) USING BTREE,
INDEX `dept_id_fk`(`department_id`) USING BTREE,
INDEX `job_id_fk`(`job_id`) USING BTREE,
CONSTRAINT `dept_id_fk` FOREIGN KEY (`department_id`) REFERENCES `departments` (`department_id`) ON DELETE RESTRICT ON UPDATE RESTRICT,
CONSTRAINT `job_id_fk` FOREIGN KEY (`job_id`) REFERENCES `jobs` (`job_id`) ON DELETE RESTRICT ON UPDATE RESTRICT
) ENGINE = InnoDB AUTO_INCREMENT = 207 CHARACTER SET = gb2312 COLLATE = gb2312_chinese_ci ROW_FORMAT = Compact;
-- ----------------------------
-- Records of employees
-- ----------------------------
INSERT INTO `employees` VALUES (100, 'Steven', 'K_ing', 'SKING', '515.123.4567', 'AD_PRES', 24000.00, NULL, NULL, 90, '1992-04-03 00:00:00');
INSERT INTO `employees` VALUES (101, 'Neena', 'Kochhar', 'NKOCHHAR', '515.123.4568', 'AD_VP', 17000.00, NULL, 100, 90, '1992-04-03 00:00:00');
INSERT INTO `employees` VALUES (102, 'Lex', 'De Haan', 'LDEHAAN', '515.123.4569', 'AD_VP', 17000.00, NULL, 100, 90, '1992-04-03 00:00:00');
INSERT INTO `employees` VALUES (103, 'Alexander', 'Hunold', 'AHUNOLD', '590.423.4567', 'IT_PROG', 9000.00, NULL, 102, 60, '1992-04-03 00:00:00');
INSERT INTO `employees` VALUES (104, 'Bruce', 'Ernst', 'BERNST', '590.423.4568', 'IT_PROG', 6000.00, NULL, 103, 60, '1992-04-03 00:00:00');
INSERT INTO `employees` VALUES (105, 'David', 'Austin', 'DAUSTIN', '590.423.4569', 'IT_PROG', 4800.00, NULL, 103, 60, '1998-03-03 00:00:00');
INSERT INTO `employees` VALUES (106, 'Valli', 'Pataballa', 'VPATABAL', '590.423.4560', 'IT_PROG', 4800.00, NULL, 103, 60, '1998-03-03 00:00:00');
INSERT INTO `employees` VALUES (107, 'Diana', 'Lorentz', 'DLORENTZ', '590.423.5567', 'IT_PROG', 4200.00, NULL, 103, 60, '1998-03-03 00:00:00');
INSERT INTO `employees` VALUES (108, 'Nancy', 'Greenberg', 'NGREENBE', '515.124.4569', 'FI_MGR', 12000.00, NULL, 101, 100, '1998-03-03 00:00:00');
INSERT INTO `employees` VALUES (109, 'Daniel', 'Faviet', 'DFAVIET', '515.124.4169', 'FI_ACCOUNT', 9000.00, NULL, 108, 100, '1998-03-03 00:00:00');
INSERT INTO `employees` VALUES (110, 'John', 'Chen', 'JCHEN', '515.124.4269', 'FI_ACCOUNT', 8200.00, NULL, 108, 100, '2000-09-09 00:00:00');
INSERT INTO `employees` VALUES (111, 'Ismael', 'Sciarra', 'ISCIARRA', '515.124.4369', 'FI_ACCOUNT', 7700.00, NULL, 108, 100, '2000-09-09 00:00:00');
INSERT INTO `employees` VALUES (112, 'Jose Manuel', 'Urman', 'JMURMAN', '515.124.4469', 'FI_ACCOUNT', 7800.00, NULL, 108, 100, '2000-09-09 00:00:00');
INSERT INTO `employees` VALUES (113, 'Luis', 'Popp', 'LPOPP', '515.124.4567', 'FI_ACCOUNT', 6900.00, NULL, 108, 100, '2000-09-09 00:00:00');
INSERT INTO `employees` VALUES (114, 'Den', 'Raphaely', 'DRAPHEAL', '515.127.4561', 'PU_MAN', 11000.00, NULL, 100, 30, '2000-09-09 00:00:00');
INSERT INTO `employees` VALUES (115, 'Alexander', 'Khoo', 'AKHOO', '515.127.4562', 'PU_CLERK', 3100.00, NULL, 114, 30, '2000-09-09 00:00:00');
INSERT INTO `employees` VALUES (116, 'Shelli', 'Baida', 'SBAIDA', '515.127.4563', 'PU_CLERK', 2900.00, NULL, 114, 30, '2000-09-09 00:00:00');
INSERT INTO `employees` VALUES (117, 'Sigal', 'Tobias', 'STOBIAS', '515.127.4564', 'PU_CLERK', 2800.00, NULL, 114, 30, '2000-09-09 00:00:00');
INSERT INTO `employees` VALUES (118, 'Guy', 'Himuro', 'GHIMURO', '515.127.4565', 'PU_CLERK', 2600.00, NULL, 114, 30, '2000-09-09 00:00:00');
INSERT INTO `employees` VALUES (119, 'Karen', 'Colmenares', 'KCOLMENA', '515.127.4566', 'PU_CLERK', 2500.00, NULL, 114, 30, '2000-09-09 00:00:00');
INSERT INTO `employees` VALUES (120, 'Matthew', 'Weiss', 'MWEISS', '650.123.1234', 'ST_MAN', 8000.00, NULL, 100, 50, '2004-02-06 00:00:00');
INSERT INTO `employees` VALUES (121, 'Adam', 'Fripp', 'AFRIPP', '650.123.2234', 'ST_MAN', 8200.00, NULL, 100, 50, '2004-02-06 00:00:00');
INSERT INTO `employees` VALUES (122, 'Payam', 'Kaufling', 'PKAUFLIN', '650.123.3234', 'ST_MAN', 7900.00, NULL, 100, 50, '2004-02-06 00:00:00');
INSERT INTO `employees` VALUES (123, 'Shanta', 'Vollman', 'SVOLLMAN', '650.123.4234', 'ST_MAN', 6500.00, NULL, 100, 50, '2004-02-06 00:00:00');
INSERT INTO `employees` VALUES (124, 'Kevin', 'Mourgos', 'KMOURGOS', '650.123.5234', 'ST_MAN', 5800.00, NULL, 100, 50, '2004-02-06 00:00:00');
INSERT INTO `employees` VALUES (125, 'Julia', 'Nayer', 'JNAYER', '650.124.1214', 'ST_CLERK', 3200.00, NULL, 120, 50, '2004-02-06 00:00:00');
INSERT INTO `employees` VALUES (126, 'Irene', 'Mikkilineni', 'IMIKKILI', '650.124.1224', 'ST_CLERK', 2700.00, NULL, 120, 50, '2004-02-06 00:00:00');
INSERT INTO `employees` VALUES (127, 'James', 'Landry', 'JLANDRY', '650.124.1334', 'ST_CLERK', 2400.00, NULL, 120, 50, '2004-02-06 00:00:00');
INSERT INTO `employees` VALUES (128, 'Steven', 'Markle', 'SMARKLE', '650.124.1434', 'ST_CLERK', 2200.00, NULL, 120, 50, '2004-02-06 00:00:00');
INSERT INTO `employees` VALUES (129, 'Laura', 'Bissot', 'LBISSOT', '650.124.5234', 'ST_CLERK', 3300.00, NULL, 121, 50, '2004-02-06 00:00:00');
INSERT INTO `employees` VALUES (130, 'Mozhe', 'Atkinson', 'MATKINSO', '650.124.6234', 'ST_CLERK', 2800.00, NULL, 121, 50, '2004-02-06 00:00:00');
INSERT INTO `employees` VALUES (131, 'James', 'Marlow', 'JAMRLOW', '650.124.7234', 'ST_CLERK', 2500.00, NULL, 121, 50, '2004-02-06 00:00:00');
INSERT INTO `employees` VALUES (132, 'TJ', 'Olson', 'TJOLSON', '650.124.8234', 'ST_CLERK', 2100.00, NULL, 121, 50, '2004-02-06 00:00:00');
INSERT INTO `employees` VALUES (133, 'Jason', 'Mallin', 'JMALLIN', '650.127.1934', 'ST_CLERK', 3300.00, NULL, 122, 50, '2004-02-06 00:00:00');
INSERT INTO `employees` VALUES (134, 'Michael', 'Rogers', 'MROGERS', '650.127.1834', 'ST_CLERK', 2900.00, NULL, 122, 50, '2002-12-23 00:00:00');
INSERT INTO `employees` VALUES (135, 'Ki', 'Gee', 'KGEE', '650.127.1734', 'ST_CLERK', 2400.00, NULL, 122, 50, '2002-12-23 00:00:00');
INSERT INTO `employees` VALUES (136, 'Hazel', 'Philtanker', 'HPHILTAN', '650.127.1634', 'ST_CLERK', 2200.00, NULL, 122, 50, '2002-12-23 00:00:00');
INSERT INTO `employees` VALUES (137, 'Renske', 'Ladwig', 'RLADWIG', '650.121.1234', 'ST_CLERK', 3600.00, NULL, 123, 50, '2002-12-23 00:00:00');
INSERT INTO `employees` VALUES (138, 'Stephen', 'Stiles', 'SSTILES', '650.121.2034', 'ST_CLERK', 3200.00, NULL, 123, 50, '2002-12-23 00:00:00');
INSERT INTO `employees` VALUES (139, 'John', 'Seo', 'JSEO', '650.121.2019', 'ST_CLERK', 2700.00, NULL, 123, 50, '2002-12-23 00:00:00');
INSERT INTO `employees` VALUES (140, 'Joshua', 'Patel', 'JPATEL', '650.121.1834', 'ST_CLERK', 2500.00, NULL, 123, 50, '2002-12-23 00:00:00');
INSERT INTO `employees` VALUES (141, 'Trenna', 'Rajs', 'TRAJS', '650.121.8009', 'ST_CLERK', 3500.00, NULL, 124, 50, '2002-12-23 00:00:00');
INSERT INTO `employees` VALUES (142, 'Curtis', 'Davies', 'CDAVIES', '650.121.2994', 'ST_CLERK', 3100.00, NULL, 124, 50, '2002-12-23 00:00:00');
INSERT INTO `employees` VALUES (143, 'Randall', 'Matos', 'RMATOS', '650.121.2874', 'ST_CLERK', 2600.00, NULL, 124, 50, '2002-12-23 00:00:00');
INSERT INTO `employees` VALUES (144, 'Peter', 'Vargas', 'PVARGAS', '650.121.2004', 'ST_CLERK', 2500.00, NULL, 124, 50, '2002-12-23 00:00:00');
INSERT INTO `employees` VALUES (145, 'John', 'Russell', 'JRUSSEL', '011.44.1344.429268', 'SA_MAN', 14000.00, 0.40, 100, 80, '2002-12-23 00:00:00');
INSERT INTO `employees` VALUES (146, 'Karen', 'Partners', 'KPARTNER', '011.44.1344.467268', 'SA_MAN', 13500.00, 0.30, 100, 80, '2002-12-23 00:00:00');
INSERT INTO `employees` VALUES (147, 'Alberto', 'Errazuriz', 'AERRAZUR', '011.44.1344.429278', 'SA_MAN', 12000.00, 0.30, 100, 80, '2002-12-23 00:00:00');
INSERT INTO `employees` VALUES (148, 'Gerald', 'Cambrault', 'GCAMBRAU', '011.44.1344.619268', 'SA_MAN', 11000.00, 0.30, 100, 80, '2002-12-23 00:00:00');
INSERT INTO `employees` VALUES (149, 'Eleni', 'Zlotkey', 'EZLOTKEY', '011.44.1344.429018', 'SA_MAN', 10500.00, 0.20, 100, 80, '2002-12-23 00:00:00');
INSERT INTO `employees` VALUES (150, 'Peter', 'Tucker', 'PTUCKER', '011.44.1344.129268', 'SA_REP', 10000.00, 0.30, 145, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (151, 'David', 'Bernstein', 'DBERNSTE', '011.44.1344.345268', 'SA_REP', 9500.00, 0.25, 145, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (152, 'Peter', 'Hall', 'PHALL', '011.44.1344.478968', 'SA_REP', 9000.00, 0.25, 145, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (153, 'Christopher', 'Olsen', 'COLSEN', '011.44.1344.498718', 'SA_REP', 8000.00, 0.20, 145, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (154, 'Nanette', 'Cambrault', 'NCAMBRAU', '011.44.1344.987668', 'SA_REP', 7500.00, 0.20, 145, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (155, 'Oliver', 'Tuvault', 'OTUVAULT', '011.44.1344.486508', 'SA_REP', 7000.00, 0.15, 145, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (156, 'Janette', 'K_ing', 'JKING', '011.44.1345.429268', 'SA_REP', 10000.00, 0.35, 146, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (157, 'Patrick', 'Sully', 'PSULLY', '011.44.1345.929268', 'SA_REP', 9500.00, 0.35, 146, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (158, 'Allan', 'McEwen', 'AMCEWEN', '011.44.1345.829268', 'SA_REP', 9000.00, 0.35, 146, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (159, 'Lindsey', 'Smith', 'LSMITH', '011.44.1345.729268', 'SA_REP', 8000.00, 0.30, 146, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (160, 'Louise', 'Doran', 'LDORAN', '011.44.1345.629268', 'SA_REP', 7500.00, 0.30, 146, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (161, 'Sarath', 'Sewall', 'SSEWALL', '011.44.1345.529268', 'SA_REP', 7000.00, 0.25, 146, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (162, 'Clara', 'Vishney', 'CVISHNEY', '011.44.1346.129268', 'SA_REP', 10500.00, 0.25, 147, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (163, 'Danielle', 'Greene', 'DGREENE', '011.44.1346.229268', 'SA_REP', 9500.00, 0.15, 147, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (164, 'Mattea', 'Marvins', 'MMARVINS', '011.44.1346.329268', 'SA_REP', 7200.00, 0.10, 147, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (165, 'David', 'Lee', 'DLEE', '011.44.1346.529268', 'SA_REP', 6800.00, 0.10, 147, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (166, 'Sundar', 'Ande', 'SANDE', '011.44.1346.629268', 'SA_REP', 6400.00, 0.10, 147, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (167, 'Amit', 'Banda', 'ABANDA', '011.44.1346.729268', 'SA_REP', 6200.00, 0.10, 147, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (168, 'Lisa', 'Ozer', 'LOZER', '011.44.1343.929268', 'SA_REP', 11500.00, 0.25, 148, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (169, 'Harrison', 'Bloom', 'HBLOOM', '011.44.1343.829268', 'SA_REP', 10000.00, 0.20, 148, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (170, 'Tayler', 'Fox', 'TFOX', '011.44.1343.729268', 'SA_REP', 9600.00, 0.20, 148, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (171, 'William', 'Smith', 'WSMITH', '011.44.1343.629268', 'SA_REP', 7400.00, 0.15, 148, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (172, 'Elizabeth', 'Bates', 'EBATES', '011.44.1343.529268', 'SA_REP', 7300.00, 0.15, 148, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (173, 'Sundita', 'Kumar', 'SKUMAR', '011.44.1343.329268', 'SA_REP', 6100.00, 0.10, 148, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (174, 'Ellen', 'Abel', 'EABEL', '011.44.1644.429267', 'SA_REP', 11000.00, 0.30, 149, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (175, 'Alyssa', 'Hutton', 'AHUTTON', '011.44.1644.429266', 'SA_REP', 8800.00, 0.25, 149, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (176, 'Jonathon', 'Taylor', 'JTAYLOR', '011.44.1644.429265', 'SA_REP', 8600.00, 0.20, 149, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (177, 'Jack', 'Livingston', 'JLIVINGS', '011.44.1644.429264', 'SA_REP', 8400.00, 0.20, 149, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (178, 'Kimberely', 'Grant', 'KGRANT', '011.44.1644.429263', 'SA_REP', 7000.00, 0.15, 149, NULL, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (179, 'Charles', 'Johnson', 'CJOHNSON', '011.44.1644.429262', 'SA_REP', 6200.00, 0.10, 149, 80, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (180, 'Winston', 'Taylor', 'WTAYLOR', '650.507.9876', 'SH_CLERK', 3200.00, NULL, 120, 50, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (181, 'Jean', 'Fleaur', 'JFLEAUR', '650.507.9877', 'SH_CLERK', 3100.00, NULL, 120, 50, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (182, 'Martha', 'Sullivan', 'MSULLIVA', '650.507.9878', 'SH_CLERK', 2500.00, NULL, 120, 50, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (183, 'Girard', 'Geoni', 'GGEONI', '650.507.9879', 'SH_CLERK', 2800.00, NULL, 120, 50, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (184, 'Nandita', 'Sarchand', 'NSARCHAN', '650.509.1876', 'SH_CLERK', 4200.00, NULL, 121, 50, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (185, 'Alexis', 'Bull', 'ABULL', '650.509.2876', 'SH_CLERK', 4100.00, NULL, 121, 50, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (186, 'Julia', 'Dellinger', 'JDELLING', '650.509.3876', 'SH_CLERK', 3400.00, NULL, 121, 50, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (187, 'Anthony', 'Cabrio', 'ACABRIO', '650.509.4876', 'SH_CLERK', 3000.00, NULL, 121, 50, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (188, 'Kelly', 'Chung', 'KCHUNG', '650.505.1876', 'SH_CLERK', 3800.00, NULL, 122, 50, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (189, 'Jennifer', 'Dilly', 'JDILLY', '650.505.2876', 'SH_CLERK', 3600.00, NULL, 122, 50, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (190, 'Timothy', 'Gates', 'TGATES', '650.505.3876', 'SH_CLERK', 2900.00, NULL, 122, 50, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (191, 'Randall', 'Perkins', 'RPERKINS', '650.505.4876', 'SH_CLERK', 2500.00, NULL, 122, 50, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (192, 'Sarah', 'Bell', 'SBELL', '650.501.1876', 'SH_CLERK', 4000.00, NULL, 123, 50, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (193, 'Britney', 'Everett', 'BEVERETT', '650.501.2876', 'SH_CLERK', 3900.00, NULL, 123, 50, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (194, 'Samuel', 'McCain', 'SMCCAIN', '650.501.3876', 'SH_CLERK', 3200.00, NULL, 123, 50, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (195, 'Vance', 'Jones', 'VJONES', '650.501.4876', 'SH_CLERK', 2800.00, NULL, 123, 50, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (196, 'Alana', 'Walsh', 'AWALSH', '650.507.9811', 'SH_CLERK', 3100.00, NULL, 124, 50, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (197, 'Kevin', 'Feeney', 'KFEENEY', '650.507.9822', 'SH_CLERK', 3000.00, NULL, 124, 50, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (198, 'Donald', 'OConnell', 'DOCONNEL', '650.507.9833', 'SH_CLERK', 2600.00, NULL, 124, 50, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (199, 'Douglas', 'Grant', 'DGRANT', '650.507.9844', 'SH_CLERK', 2600.00, NULL, 124, 50, '2014-03-05 00:00:00');
INSERT INTO `employees` VALUES (200, 'Jennifer', 'Whalen', 'JWHALEN', '515.123.4444', 'AD_ASST', 4400.00, NULL, 101, 10, '2016-03-03 00:00:00');
INSERT INTO `employees` VALUES (201, 'Michael', 'Hartstein', 'MHARTSTE', '515.123.5555', 'MK_MAN', 13000.00, NULL, 100, 20, '2016-03-03 00:00:00');
INSERT INTO `employees` VALUES (202, 'Pat', 'Fay', 'PFAY', '603.123.6666', 'MK_REP', 6000.00, NULL, 201, 20, '2016-03-03 00:00:00');
INSERT INTO `employees` VALUES (203, 'Susan', 'Mavris', 'SMAVRIS', '515.123.7777', 'HR_REP', 6500.00, NULL, 101, 40, '2016-03-03 00:00:00');
INSERT INTO `employees` VALUES (204, 'Hermann', 'Baer', 'HBAER', '515.123.8888', 'PR_REP', 10000.00, NULL, 101, 70, '2016-03-03 00:00:00');
INSERT INTO `employees` VALUES (205, 'Shelley', 'Higgins', 'SHIGGINS', '515.123.8080', 'AC_MGR', 12000.00, NULL, 101, 110, '2016-03-03 00:00:00');
INSERT INTO `employees` VALUES (206, 'William', 'Gietz', 'WGIETZ', '515.123.8181', 'AC_ACCOUNT', 8300.00, NULL, 205, 110, '2016-03-03 00:00:00');
-- ----------------------------
-- Table structure for job_grades
-- ----------------------------
DROP TABLE IF EXISTS `job_grades`;
CREATE TABLE `job_grades` (
`grade_level` varchar(3) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`lowest_sal` int(11) NULL DEFAULT NULL,
`highest_sal` int(11) NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
-- ----------------------------
-- Records of job_grades
-- ----------------------------
INSERT INTO `job_grades` VALUES ('A', 1000, 2999);
INSERT INTO `job_grades` VALUES ('B', 3000, 5999);
INSERT INTO `job_grades` VALUES ('C', 6000, 9999);
INSERT INTO `job_grades` VALUES ('D', 10000, 14999);
INSERT INTO `job_grades` VALUES ('E', 15000, 24999);
INSERT INTO `job_grades` VALUES ('F', 25000, 40000);
-- ----------------------------
-- Table structure for jobs
-- ----------------------------
DROP TABLE IF EXISTS `jobs`;
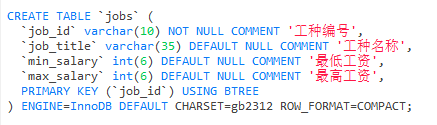
CREATE TABLE `jobs` (
`job_id` varchar(10) CHARACTER SET gb2312 COLLATE gb2312_chinese_ci NOT NULL COMMENT '工种编号',
`job_title` varchar(35) CHARACTER SET gb2312 COLLATE gb2312_chinese_ci NULL DEFAULT NULL COMMENT '工种名称',
`min_salary` int(6) NULL DEFAULT NULL COMMENT '最低工资',
`max_salary` int(6) NULL DEFAULT NULL COMMENT '最高工资',
PRIMARY KEY (`job_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = gb2312 COLLATE = gb2312_chinese_ci ROW_FORMAT = Compact;
-- ----------------------------
-- Records of jobs
-- ----------------------------
INSERT INTO `jobs` VALUES ('AC_ACCOUNT', 'Public Accountant', 4200, 9000);
INSERT INTO `jobs` VALUES ('AC_MGR', 'Accounting Manager', 8200, 16000);
INSERT INTO `jobs` VALUES ('AD_ASST', 'Administration Assistant', 3000, 6000);
INSERT INTO `jobs` VALUES ('AD_PRES', 'President', 20000, 40000);
INSERT INTO `jobs` VALUES ('AD_VP', 'Administration Vice President', 15000, 30000);
INSERT INTO `jobs` VALUES ('FI_ACCOUNT', 'Accountant', 4200, 9000);
INSERT INTO `jobs` VALUES ('FI_MGR', 'Finance Manager', 8200, 16000);
INSERT INTO `jobs` VALUES ('HR_REP', 'Human Resources Representative', 4000, 9000);
INSERT INTO `jobs` VALUES ('IT_PROG', 'Programmer', 4000, 10000);
INSERT INTO `jobs` VALUES ('MK_MAN', 'Marketing Manager', 9000, 15000);
INSERT INTO `jobs` VALUES ('MK_REP', 'Marketing Representative', 4000, 9000);
INSERT INTO `jobs` VALUES ('PR_REP', 'Public Relations Representative', 4500, 10500);
INSERT INTO `jobs` VALUES ('PU_CLERK', 'Purchasing Clerk', 2500, 5500);
INSERT INTO `jobs` VALUES ('PU_MAN', 'Purchasing Manager', 8000, 15000);
INSERT INTO `jobs` VALUES ('SA_MAN', 'Sales Manager', 10000, 20000);
INSERT INTO `jobs` VALUES ('SA_REP', 'Sales Representative', 6000, 12000);
INSERT INTO `jobs` VALUES ('SH_CLERK', 'Shipping Clerk', 2500, 5500);
INSERT INTO `jobs` VALUES ('ST_CLERK', 'Stock Clerk', 2000, 5000);
INSERT INTO `jobs` VALUES ('ST_MAN', 'Stock Manager', 5500, 8500);
-- ----------------------------
-- Table structure for locations
-- ----------------------------
DROP TABLE IF EXISTS `locations`;
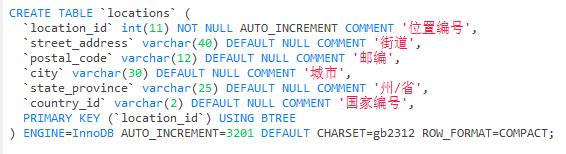
CREATE TABLE `locations` (
`location_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '位置编号',
`street_address` varchar(40) CHARACTER SET gb2312 COLLATE gb2312_chinese_ci NULL DEFAULT NULL COMMENT '街道',
`postal_code` varchar(12) CHARACTER SET gb2312 COLLATE gb2312_chinese_ci NULL DEFAULT NULL COMMENT '邮编',
`city` varchar(30) CHARACTER SET gb2312 COLLATE gb2312_chinese_ci NULL DEFAULT NULL COMMENT '城市',
`state_province` varchar(25) CHARACTER SET gb2312 COLLATE gb2312_chinese_ci NULL DEFAULT NULL COMMENT '州/省',
`country_id` varchar(2) CHARACTER SET gb2312 COLLATE gb2312_chinese_ci NULL DEFAULT NULL COMMENT '国家编号',
PRIMARY KEY (`location_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 3201 CHARACTER SET = gb2312 COLLATE = gb2312_chinese_ci ROW_FORMAT = Compact;
-- ----------------------------
-- Records of locations
-- ----------------------------
INSERT INTO `locations` VALUES (1000, '1297 Via Cola di Rie', '00989', 'Roma', NULL, 'IT');
INSERT INTO `locations` VALUES (1100, '93091 Calle della Testa', '10934', 'Venice', NULL, 'IT');
INSERT INTO `locations` VALUES (1200, '2017 Shinjuku-ku', '1689', 'Tokyo', 'Tokyo Prefecture', 'JP');
INSERT INTO `locations` VALUES (1300, '9450 Kamiya-cho', '6823', 'Hiroshima', NULL, 'JP');
INSERT INTO `locations` VALUES (1400, '2014 Jabberwocky Rd', '26192', 'Southlake', 'Texas', 'US');
INSERT INTO `locations` VALUES (1500, '2011 Interiors Blvd', '99236', 'South San Francisco', 'California', 'US');
INSERT INTO `locations` VALUES (1600, '2007 Zagora St', '50090', 'South Brunswick', 'New Jersey', 'US');
INSERT INTO `locations` VALUES (1700, '2004 Charade Rd', '98199', 'Seattle', 'Washington', 'US');
INSERT INTO `locations` VALUES (1800, '147 Spadina Ave', 'M5V 2L7', 'Toronto', 'Ontario', 'CA');
INSERT INTO `locations` VALUES (1900, '6092 Boxwood St', 'YSW 9T2', 'Whitehorse', 'Yukon', 'CA');
INSERT INTO `locations` VALUES (2000, '40-5-12 Laogianggen', '190518', 'Beijing', NULL, 'CN');
INSERT INTO `locations` VALUES (2100, '1298 Vileparle (E)', '490231', 'Bombay', 'Maharashtra', 'IN');
INSERT INTO `locations` VALUES (2200, '12-98 Victoria Street', '2901', 'Sydney', 'New South Wales', 'AU');
INSERT INTO `locations` VALUES (2300, '198 Clementi North', '540198', 'Singapore', NULL, 'SG');
INSERT INTO `locations` VALUES (2400, '8204 Arthur St', NULL, 'London', NULL, 'UK');
INSERT INTO `locations` VALUES (2500, 'Magdalen Centre, The Oxford Science Park', 'OX9 9ZB', 'Oxford', 'Oxford', 'UK');
INSERT INTO `locations` VALUES (2600, '9702 Chester Road', '09629850293', 'Stretford', 'Manchester', 'UK');
INSERT INTO `locations` VALUES (2700, 'Schwanthalerstr. 7031', '80925', 'Munich', 'Bavaria', 'DE');
INSERT INTO `locations` VALUES (2800, 'Rua Frei Caneca 1360 ', '01307-002', 'Sao Paulo', 'Sao Paulo', 'BR');
INSERT INTO `locations` VALUES (2900, '20 Rue des Corps-Saints', '1730', 'Geneva', 'Geneve', 'CH');
INSERT INTO `locations` VALUES (3000, 'Murtenstrasse 921', '3095', 'Bern', 'BE', 'CH');
INSERT INTO `locations` VALUES (3100, 'Pieter Breughelstraat 837', '3029SK', 'Utrecht', 'Utrecht', 'NL');
INSERT INTO `locations` VALUES (3200, 'Mariano Escobedo 9991', '11932', 'Mexico City', 'Distrito Federal,', 'MX');
-- Table structure for beauty
-- ----------------------------
DROP TABLE IF EXISTS `beauty`;
CREATE TABLE `beauty` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '姓名',
`sex` char(1) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT 'Ů' COMMENT '性别',
`borndate` datetime NULL DEFAULT '1987-01-01 00:00:00' COMMENT '出生日期',
`phone` varchar(11) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '手机号',
`photo` blob NULL COMMENT '照片',
`boyfriend_id` int(11) NULL DEFAULT NULL COMMENT '男朋友id',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 13 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
-- ----------------------------
-- Records of beauty
-- ----------------------------
INSERT INTO `beauty` VALUES (1, '柳岩', '女', '1988-02-03 00:00:00', '18209876577', NULL, 8);
INSERT INTO `beauty` VALUES (2, '苍老师', '女', '1987-12-30 00:00:00', '18219876577', NULL, 9);
INSERT INTO `beauty` VALUES (3, 'Angelababy', '女', '1989-02-03 00:00:00', '18209876567', NULL, 3);
INSERT INTO `beauty` VALUES (4, '热巴', '女', '1993-02-03 00:00:00', '18209876579', NULL, 2);
INSERT INTO `beauty` VALUES (5, '周冬雨', '女', '1992-02-03 00:00:00', '18209179577', NULL, 9);
INSERT INTO `beauty` VALUES (6, '周芷若', '女', '1988-02-03 00:00:00', '18209876577', NULL, 1);
INSERT INTO `beauty` VALUES (7, '岳灵珊', '女', '1987-12-30 00:00:00', '18219876577', NULL, 9);
INSERT INTO `beauty` VALUES (8, '小昭', '女', '1989-02-03 00:00:00', '18209876567', NULL, 1);
INSERT INTO `beauty` VALUES (9, '双儿', '女', '1993-02-03 00:00:00', '18209876579', NULL, 9);
INSERT INTO `beauty` VALUES (10, '王语嫣', '女', '1992-02-03 00:00:00', '18209179577', NULL, 4);
INSERT INTO `beauty` VALUES (11, '夏雪', '女', '1993-02-03 00:00:00', '18209876579', NULL, 9);
INSERT INTO `beauty` VALUES (12, '赵敏', '女', '1992-02-03 00:00:00', '18209179577', NULL, 1);
-- ----------------------------
-- Table structure for boys
-- ----------------------------
DROP TABLE IF EXISTS `boys`;
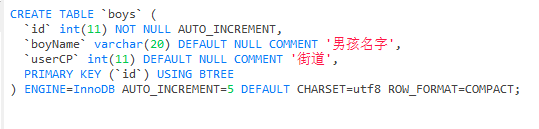
CREATE TABLE `boys` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`boyName` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '男孩名字',
`userCP` int(11) NULL DEFAULT NULL COMMENT '街道',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 5 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
-- ----------------------------
-- Records of boys
-- ----------------------------
INSERT INTO `boys` VALUES (1, '张无忌', 100);
INSERT INTO `boys` VALUES (2, '鹿晗', 800);
INSERT INTO `boys` VALUES (3, '黄晓', 50);
INSERT INTO `boys` VALUES (4, '段誉', 300);
SET FOREIGN_KEY_CHECKS = 1;
1.2 基础查询
select 查询列表 from 表名;
特点:
1.查询的结果集是一个虚拟表
2.select 查询列表 类似于System.out.println(打印内容);
select 后面跟的查询列表,可以有多个部分组成,中间用逗号隔开
例如: select 字段1,字段2,表达式 from 表;
System.out.println()的打印内容,只能有一个
3.执行顺序
select first_name from emplyees;
1)from字句
2)select字句
4. 查询列表可以是:字段、表达式、常量、函数等
select first_name from employees;
-- 一、查询常量
select 100;
-- 二、查询表达式
select 100%3;
-- 三、查询单个字段
select last_name from employees;
-- 四、查询多个字段
select last_name, email, employee_id from employees;
-- 五、查询所有字段
select * from employees;
-- 六、查询函数(调用函数,获取返回值)
select database();
select version();
select user();
-- 七、起别名
-- 方式一:使用as关键字
select user() as 用户名;
select user() as "用户名";
select user() as '用户名';
select last_name as "姓 名" from employees
-- 方式二:使用空格
select user() 用户名;
select user() "用户名";
select user() '用户名';
select last_name "姓 名" from employees
-- 八、需求:查询first_name和last_name拼接成的全名,最终起别名为:姓名
-- 方案1:使用+ passx
select first_name+last_name as '姓 名' from employees;
-- 方案2:使用concat拼接函数
select concat(first_name, last_name) as '姓 名' from employees;
/*
Java中+的作用
1.加法运算
100+1.5 'a'+2 1.3+2
2.拼接符
至少有一个操作数为字符串
"hello"+'a'
mysql中+的作用:
1.加法运算
a:两个操作数都是数值型
100+1.5
b:其中一个操作数为字符型
将字符型数据强制转换成数值型,如果无法转换,则直接当做0处理
'张无忌'+100 ==>100
c:其中一个操作数为null
null + null ===> null
null + 100 ===> null
*/
-- 九、distinct的使用
-- 需求:查询员工涉及到的部门编号有哪些
select distinct department_id from employees;
-- 十、查看表的结构
desc employees;
show columns from employees;
-- 十一、练习
ifnull(a,b)如果不是空显示a,如果是空显示b
/*
ifnull(表达式1,表达式2)
表达式1:可能为null的字段或表达式
表达式2:如果表达式1为null,则最终结果显示的值
功能:如果表达式1为null,则显示表达式2,否则显示表达式1
*/
select commission_pct, ifnull(commission_pct, '空') from employees;
select concat(first_name, ',',last_name, ',',ifnull(commission_pct, 'empty')) as out_put from employees;1.3 条件查询
进阶二:条件查询
/*
语法:
select 查询列表
from 表名
where 筛选条件;
执行顺序:
1.from子句
2.where子句
3.select子句
select last_name from employees where salary>20000;
特点:
1、按关系表达式筛选
关系运算符:> < >= <= = <>
补充:也可以使用!=,但不建议
2.按逻辑表达式筛选
逻辑运算符:and or not
补充:也可以使用 && || !,但不建议
3.模糊查询
like
in between and
is null
*/
-- 一、按关系表达式筛选
-- 案例1:查询部门编号不是100的员工信息
select * from employees where department_id <> 100;
-- 案例2:查询工资<15000的姓名、工资
select last_name,salary from employees where salary<15000;
-- 二、按逻辑表达式筛选
-- 案例1:查询部门编号不是50-100之间员工姓名、部门编号、邮箱
-- 方式1:
select last_name,department_id, email from employees where department_id < 50 or department_id > 100;
-- 方式2:
select last_name,department_id, email from employees where not(department_id>=50 and department_id<=100);
-- 案例2:查询奖金率>0.03 或者员工编号在60-110之间的员工信息
select * from employees where commission_pct > 0.03 or (employee_id >= 60 and employee_id <=100);
-- 三、模糊查询
-- 1.like
/*
功能:一般和通配符搭配使用,对字符型数据进行部分匹配查询
常见的通配符:
_ 任意单个字符
% 任意多个字符
*/
-- 案例1:查询姓名中包含字符a的员工信息
select * from employees where last_name like '%a%';
-- 案例2:查询姓名中包含最后一个字符a的员工信息
select * from employees where last_name like '%a';
-- 案例3:查询姓名中包含第一个字符a的员工信息
select * from employees where last_name like 'a%';
-- 案例1:查询姓名中包含第三个字符a的员工信息
select * from employees where last_name like '__a%';
-- 案例1:查询姓名中包含第二个字符为_的员工信息
select * from employees where last_name like '_\_%';
select * from employees where last_name like '_$_%' escape '$'; #设置$为转义字符
-- 2. in
/*
功能:查询某字段的值是否属于指定的列表之内
a in (常量值1,常量值2,常量值3...)
a not in (常量值1,常量值2,常量值3...)
in/not in
*/
-- 案例1:查询部门编号是30/50/90的员工名、部门编号
select last_name, department_id from employees where department_id in (30,50,90);
-- 案例2:查询工种编号不是SH_CLERK或IT_PROG的员工信息
select * from employees where job_id not in ('SH_CLERK','IT_PROG');
-- 3. between and
/*
功能:判断某个字段的值是否介于xx之间
between and/not between and
*/
-- 案例1:查询部门编号是30-90之间的部门编号、员工姓名
select department_id,last_name from employees where department_id between 30 and 90;
-- 案例2:查询年薪不是100000-200000之间的员工姓名、工资、年薪
select last_name,salary,salary*12*(1+ifnull(commission_pct,0)) 年薪 from employees where salary*12*(1+ifnull(commission_pct,0)) not between 100000 and 200000;
-- 4. is null/is not null
-- 案例1:查询没有奖金的员工信息
select * from employees where commission_pct is null;
-- 案例2: 查询有奖金的员工信息
select * from employees where commission_pct is not null;
-- = 只能判断普通的内容
-- is 只能判断null值
-- <=> 安全等于,既能判断普通内容,又能判断null值
select * from employees where commission_pct <=> null;
select * from employees where salary <=> 10000;
1.4 排序查询
-- 进阶3;排序查询
/*
语法:
select 查询列表
from 表名
【where 筛选条件】
order by 排序列表
执行顺序:
1.from子句
2. where子句
3. select子句
4. order by子句
特点:
1.排序列表可以是单个字段、多个字段、表达式、函数、列数、以及以上的组合
2.升序,通过asc,默认行为
降序,通过desc
*/
-- 一、按单个字段排序
-- 案例1:将员工编号>120的员工信息进行工资的升序
select * from employees where employee_id>120 order by salary asc;
-- 案例2:将员工编号>120的员工信息进行工资的降序
select * from employees where employee_id>120 order by salary desc;
-- 二、按表达式排序
-- 案例1:对有奖金的员工,按年薪降序
select *, salary*12*(1+ifnull(commission_pct,0)) 年薪 from employees where commission_pct is not null order by salary*12*(1+ifnull(commission_pct,0)) desc;
-- 三、按别名排序
-- 案例1:对有奖金的员工,按年薪降序
select *, salary*12*(1+ifnull(commission_pct,0)) 年薪 from employees where commission_pct is not null order by 年薪 desc;
-- 四、按函数的结果排序
-- 案例1:按姓名的字数长度进行升序
select last_name from employees order by length(last_name);
-- 五、按多个字段排序
-- 案例1:查询员工的姓名、工资、部门编号、先按工资升序,再按部门编号降序
select last_name, salary, department_id from employees order by salary asc, department_id desc;
-- 六、按列数排序
select * from employees order by 2 desc;
select * from employees order by first_name;1.5 分组函数
进阶5:分组函数/聚合函数
/*
说明:分组函数/聚合函数往往用于实现将一组数据进行统计计算,最终得到一个值,又称为聚合函数或统计函数
分组函数清单:
sum(字段名):求和
avg(字段名): 求平均数
max(字段名):求最大值
min(字段名): 求最小值
count(字段名): 计算非空字段值的个数
*/
-- 案例1: 查询员工信息表中,所有员工的工资和、工资平均值、最低工资、最高工资、有工资的个数
select sum(salary),avg(salary),min(salary),max(salary),count(salary) from employees;
-- 案例2:添加筛选条件
-- 1.查询emp表中记录数
select count(employee_id) from employees;
-- 2.查询emp表中有佣金的人数
select count(salary) from employees;
-- 3.查询emp表中月薪大于2500的人数
select count(salary) from employees where salary>2500;
-- 4.查询有领导的人数
select count(manager_id) from employees;
-- count的补充介绍
-- count(*):查看行数,每一个字段如果都不是空就算一行
-- count(1):加了一个常量列,都是1,数了数多少行
-- count(str):加了一个常量列,都是str,数了数多少行
-- 1.统计结果集的行数,推荐使用count(*)
select count(*) from employees;
select count(*) from employees where department_id = 30;
select count(1) from employees;
select count(1) from employees where department_id = 30;
select count(2) from employees;
select count(2) from employees where department_id = 30;
-- 2. 搭配distinct实现去重的统计
-- 需求:查询有员工的部门个数
select count(distinct department_id) from employees;
-- 思考:每个部门的总工资、平均工资
select sum(salary) from employees where department_id = 30;
select sum(salary) from employees where department_id = 50;
-- 分组查询group by
-- 一般来说,和分组函数一同查询的字段,就是你分组的字段
select sum(salary), department_id from employees group by department_id;1.6 分组查询
当需要分组查询时需要使用group by子句,例如查询每个部门的工资和,这说明要使用部门来分组。

-- 进阶6:分组查询
/*
语法:
select 查询列表
from 表名
where 筛选条件
group by 分组列表
having 分组后筛选
order by 排序列表;
执行顺序:
1.from字句
特点:
1.查询列表往往是分组函数和被分组的字段
2.分组查询中的筛选分为两类
筛选的基表 使用的关键词 位置
分组前筛选 原始表 where group by的前面
分组后筛选 分组后的结果集 having group by的后面
where--group by --having
问题:分组函数做条件只可能放在having后面
*/
-- 1)简单的分组
-- 案例1:查询每个工种的员工平均工资
select avg(salary), job_id from employees group by job_id;
-- 案例2:查询每个领导的手下人数
select count(*), manager_id from employees where manager_id is not null group by manager_id;
-- 2) 可以实现分组前的筛选
-- 案例1:查询邮箱中包含a字符的 每个部门的最高工资
select max(salary) 最高工资,department_id from employees where email like '%a%' group by department_id;
-- 案例2:查询每个领导手下有奖金的员工的平均工资
select avg(salary) 平均工资, manager_id from employees where commission_pct is not null group by manager_id;
-- 3)可以实现分组后的筛选
-- 案例1:查询哪个部门的员工个数>5
-- 分析1:查询每个部门的员工个数
select count(*) 员工个数, department_id from employees group by department_id;
-- 分析2:在刚才的结果基础上,筛选哪个部门的员工个数>5
select count(*) 员工个数, department_id from employees where count(*)>5 group by department_id; #报错,where条件执行是在select前,不认识count(*)
select count(*) 员工个数, department_id from employees group by department_id having count(*)>5;
-- 案例2:每个工种有奖金的员工的最高工资>12000的工种编号和最高工资
select job_id,max(salary) from employees where commission_pct is not null group by job_id having max(salary)>12000;
-- 案例3:领导编号>102的 每个领导手下的最低工资 大于5000的最低工资
-- 分析1:每个领导手下的最低工资
select min(salary) 最低工资, manager_id from employees group by manager_id;
-- 分析2:筛选刚才1的结果
select min(salary) 最低工资, manager_id from employees where manager_id>102 group by manager_id having min(salary)>5000;
select min(salary) 最低工资, manager_id from employees group by manager_id having min(salary)>5000 and manager_id>102;
-- 4) 可以实现排序
-- 案例:查询没有奖金的员工的最高工资>6000的工种编号和最高工资,按最高公司升序
-- 分析1:按工种分组,查询每个工种有奖金的员工的最高工资
select max(salary) 最高工资, job_id from employees where commission_pct is null group by job_id;
-- 分析2:筛选刚才的结果,看哪个最高工资>6000
select max(salary) 最高工资, job_id from employees where commission_pct is null group by job_id having max(salary)>6000;
-- 分析3:按最高工资升序
select max(salary) 最高工资, job_id from employees where commission_pct is null group by job_id having max(salary)>6000 order by max(salary) asc;
-- 5) 按多个字段分组
-- 案例:查询每个工种每个部门的最低工资,并按最低工资降序
-- 提示:工种和部门都一样的才算一组
-- 工种 部门 工资
-- 1 10
-- 1 20
-- 2 20
-- 3 20
-- 1 10
-- 2 20
select min(salary) 最低工资, job_id, department_id from employees group by job_id, department_id;
1.7 SQL92语法
-- 一、内连接
-- 一)等值连接
/*
语法:
select 查询列表
from 表名1 别名1,表名2 别名2,...
where 等值连接的连接条件
特点:
1.为了解决多表中的字段名重名问题,往往为表起别名,提高语义性
2.表的顺序无要求
*/
-- 1.简单的两表连接
-- 案例:查询员工名和部门名
select last_name, department_name from employees e, departments d where e.department_id = d.department_id;
-- 2.添加筛选条件
-- 案例1:查询部门编号>100的部门名和所在的城市名
select department_name, city from departments d, locations l where d.location_id = l.location_id and d.department_id > 100;
-- 案例2.查询有奖金的员工名、部门名
select last_name, department_name from departments d, employees e where d.department_id = e.department_id and e.commission_pct is not null;
-- 案例3. 查询城市名中第二个字符为o的部门名和城市名
select department_name, city from departments d, locations l where d.location_id = l.location_id and city like '_o%';
-- 3.添加分组+筛选
-- 案例1:查询每个城市的部门个数
select count(*) 部门个数, l.city from departments d, locations l where d.location_id = l.location_id group by l.city;
-- 4.添加分组、筛选、排序
-- 案例:查询哪个部门的员工个数>5,并按员工个数进行降序
select department_name, count(*) 个数 from employees e, departments d where e.department_id = d.department_id
group by e.department_id having 个数>5 order by 个数 desc;1.8 SQL99语法
-- 一、内连接
-- 语法:
/*
select 查询列表 1
from 表名1 别名 2
[inner] join 表名2 别名 on 连接条件 3
[inner] join 表名3 别名 on 连接条件
where 筛选条件 4
group by 分组列表 5
having 分组后筛选 6
order by 排序列表; 7
执行顺序:
2345617
SQL92和SQL99的区别:
SQL99,使用JOIN关键字代替了之前的逗号,并且将连接条件和筛选条件进行了分离,提高阅读性!
*/
-- 一、等值连接
-- 1.简单连接
-- 案例: 查询员工名和部门名
select last_name, department_name from employees e inner join departments d on e.department_id = d.department_id;
-- 2.添加筛选条件
-- 案例1:查询部门编号>100的部门名和所在的城市名
select department_name, city from departments d join locations l on d.location_id = l.location_id where d.department_id >100;
-- 3.添加分组+筛选
-- 案例1:查询每个城市的部门个数
select count(*) 部门个数, l.city from departments d join locations l on d.location_id = l.location_id group by l.city;
-- 4.添加分组+筛选+排序
-- 案例1:查询部门中员工个数>10的部门名,并按员工个数降序
select count(*) 员工个数, d.department_name from employees e join departments d on e.department_id = d.department_id
group by d.department_id having 员工个数>10 order by 员工个数 desc;
-- 二) 非等值连接
案例:查询部门编号在10-90之间的员工的工资级别,并按级别进行分组
select count(*) 个数, grade_level from employees e join job_grades g on e.salary between g.lowest_sal and g.highest_sal
where e.department_id between 10 and 90 group by g.grade_level;
-- 三、自连接
-- 案例:查询员工名和对应的领导名
select e.last_name, m.last_name from employees e join employees m on e.manager_id = m.employee_id;
1.9 外连接
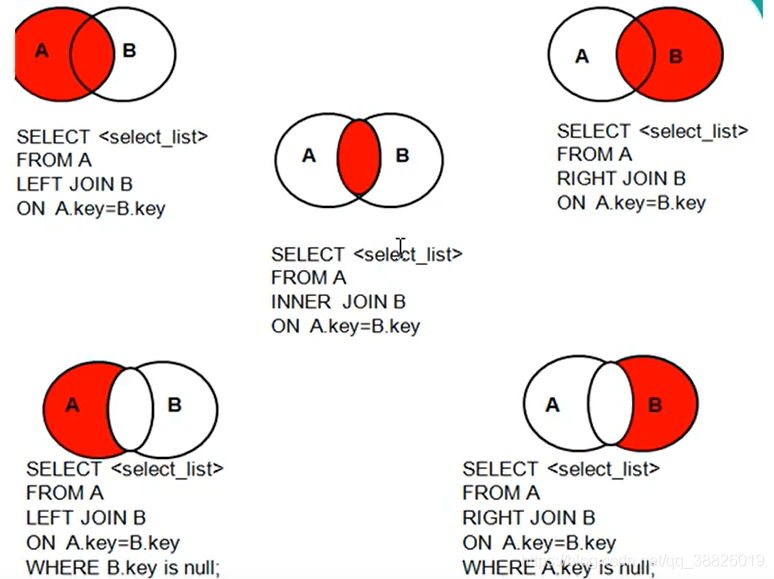
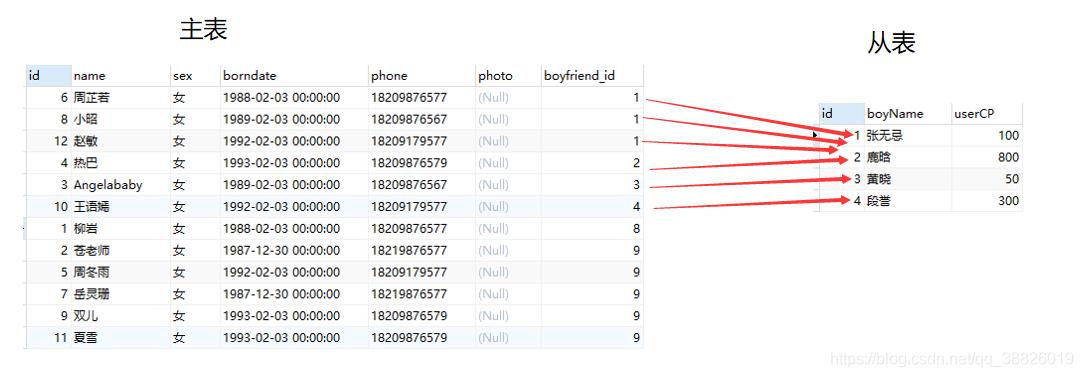
内连接不分主表从表,可以颠倒表的顺序,结果一直,显示两个表匹配的行
select * from beauty b
inner join boys on b.boyfriend_id = boys.id
order by b.boyfriend_id;
左连接,左边表为主表,右边表为从表,显示主表所有行,和右边匹配的行,不匹配的为null
select * from beauty b
left join boys on b.boyfriend_id = boys.id
order by b.boyfriend_id;
-- 二、外连接
/*
说明:查询结果为主表中所有的记录,如果从表有匹配项,则显示匹配项;如果从表没有匹配项,则显示null
应用场景:一般用于查询主表中有但从表没有的记录
特点:
1.外连接分主从表,两表的顺序不能任意调换
2.左连接的话,left join左边为主表
右连接的话,right join右边为主表
语法:
select 查询列表
from 表1 别名
left|right [outer] join 表2 别名
on 连接条件
where 筛选条件;
*/
-- 案例1: 查询所有女神记录,以及对应的男神名,如果没有对应的男神,则显示null
-- 左连接
select b.*, bo.*
from beauty b left join boys bo on b.boyfriend_id = bo.id order by b.boyfriend_id;
-- 右连接
select b.*, bo.*
from beauty b right join boys bo on b.boyfriend_id = bo.id order by b.boyfriend_id;
-- 案例2: 查询哪个女神没有男神
select b.name
from beauty b left join boys bo on b.boyfriend_id = bo.id where bo.id is null order by b.boyfriend_id;
-- 案例3:查询哪个部门没有员工,并显示其部门编号和部门名
select d.department_id, d.department_name
from departments d
left join employees e on d.department_id = e.department_id
where e.employee_id is null;
-- 一、查询编号>3的女神的男朋友信息,如果有则列出详细,如果没有,用null填充
select b.id, b.name,bo.*
from beauty b
left join boys bo on b.boyfriend_id = bo.id where b.id >3;
-- 二、查询哪个城市没有部门
select l.city, d.*
from departments d
right join locations l on l.location_id = d.location_id
where d.department_id is null;
-- 三、查询部门名为SAL或IT的员工信息
select d.*,e.*
from departments d
left join employees e on d.department_id = e.department_id
where d.department_name = 'SAL' or d.department_name = 'IT';1.10 子查询
-- 子查询
/*
说明:当一个查询语句中又嵌套了另一个完整的select语句,则被嵌套的select语句称为子查询或内查询
外面的select语句称为主查询或外查询.
分类:
按子查询出现的位置进行分类:
1.select后面
要求:子查询的结果为单行单列(标量子查询)
2.from后面
要求:子查询的结果可以为多行多列
3.where或having后面
要求:子查询的结果必须为单列
单行子查询
多行子查询
4.exists后面
要求:子查询结果必须为单列(相关子查询)
特点:
1. 子查询放在条件中,要求必须放在条件的右侧
2. 子查询一般放在小括号中
3. 子查询的执行优先于主查询
4. 单行子查询对应了 单行操作符:> < >= <= = <>
多行子查询对应了 多行操作符:any/some all in
*/
-- 1. 查询和Zlotkey相同部门的员工姓名和工资
-- 1)查询Zlotkey的部门编号
select department_id from employees where last_name = 'Zlotkey';
-- 2)查询department_id = 1)的员工姓名和工资
select last_name, salary from employees where department_id = (select department_id from employees where last_name = 'Zlotkey');
-- 2. 查询工资比公司平均工资高的员工的员工号,姓名和工资
-- 1)查询平均工资
select avg(salary) from employees;
-- 2) 查询salary>1)的信息
select employee_id, last_name, salary from employees where salary>(select avg(salary) from employees);
-- 二)多行子查询
/*
in: 判断某字段是否在指定列表内
x in (10, 30, 50)
any/some:判断某字段的值是否满足其中任意一个
x>any(10,30,50)
x>min()
x=any(10,30,50)
x in (10,30,50)
all:判断某字段的值是否满足里面所有的
x > all(10,30,50)
x > max()
*/
-- 案例1:返回location_id是1400或1700的部门中的所有员工姓名
-- 1)查询location_id是1400或1700的部门
select department_id from departments where location_id in(1400,1700);
-- 2) 查询department_id=1)的姓名
select last_name from employees where department_id in(select department_id from departments where location_id in(1400,1700));
-- 案例2:返回其他部门中比job_id为'IT_PROG'部门任一工资低的员工的员工号、姓名、job_id以及salary
-- 1) 查询job_id为'IT_PROG'部门的工资
select distinct salary from employees where job_id = 'IT_PROG';
-- 2) 查询其他部门的工资<任意一个1)的结果
select employee_id, last_name, job_id, salary from employees where salary<any(select distinct salary from employees where job_id = 'IT_PROG');
-- 案例3:返回其它部门中比job_id为'IT_PROG'部门所有工资低的员工的员工号、姓名、job_id以及salary
-- 1) 查询job_id为'IT_PROG'部门的工资
select distinct salary from employees where job_id = 'IT_PROG';
-- 2)查询其它部门的工资<所有1)的结果
select employee_id, last_name, job_id, salary from employees where salary<all(select distinct salary from employees where job_id = 'IT_PROG');
-- 案例4:查询各部门中工资比本部门平均工资高的员工的员工号,姓名和工资
-- 1.查询各部门的平均工资
select department_id,avg(salary) ag from employees group by department_id;
-- 2.将1结果和employees表连接查询
select employee_id,last_name,salary from employees e join (select department_id,avg(salary) ag from employees group by department_id) dep_ag on e.department_id = dep_ag.department_id where e.salary>dep_ag.ag;
-- 案例5:查询和姓名中包含字母u的员工在相同部门的员工的员工号和姓名
-- 1.查询姓名中包含字母u的员工的部门编号
select distinct department_id from employees where last_name like '%u%';
-- 2.查询部门号是1的员工号和姓名
select employee_id,last_name from employees where department_id in (select distinct department_id from employees where last_name like '%u%');
-- 案例6:查询管理者是King的员工姓名和工资
-- 1.查询管理者是king的编号
select employee_id from employees where last_name = 'k_ing';
-- 2.查询哪个员工的领导编号是1
select last_name,salary from employees where manager_id in (select employee_id from employees where last_name = 'k_ing');
-- 案例7:查询平均工资最低的部门信息和该部门的平均工资
-- 1.查询各部门的平均工资
select avg(salary) ag, department_id from employees group by department_id;
-- 2.查询哪个部门的平均工资最低
select avg(salary) ag, department_id from employees group by department_id order by ag limit 1;
-- 3.连接2和departments表
select d.*, dep_ag.ag from departments d join (select avg(salary) ag, department_id from employees group by department_id order by ag limit 1) dep_ag on d.department_id = dep_ag.department_id;
-- 案例8:各个部门中,最高工资中最低的那个部门的最低工资是多少
-- 1.查询各部门的最高工资
select max(salary) mx, department_id from employees group by department_id;
-- 2.查询各部门的最高工资最低的那个部门
select department_id from employees group by department_id order by max(salary) limit 1;
-- 3.查询部门编号是2的部门的最低工资
select min(salary), department_id from employees where department_id = (select department_id from employees group by department_id order by max(salary) limit 1);
-- 二、放在select后面
-- 案例:查询部门编号是50的员工个数
select count(*) from employees where department_id = 50;
select (select count(*) from employees where department_id = 50) 个数;
-- 三、放在from后面
-- 案例:查询每个部门的平均工资的工资级别
-- 1)查询每个部门的平均工资
select avg(salary), department_id from employees group by department_id;
-- 2)2将1和job_grades两表连接查询
select dep_ag.department_id, dep_ag.ag, g.grade_level
from job_grades g
inner join (
select avg(salary) ag, department_id from employees group by department_id) dep_ag on dep_ag.ag between g.lowest_sal and g.highest_sal;
-- 四、放在exists后面
-- 案例1:查询有无名字叫"张三丰"的员工信息
select * from employees where last_name = '张三丰';
select exists(select * from employees where last_name = '张三丰') 有无张三丰;1.11分页查询
-- 进阶8:分页查询
/*
应用场景:
当页面上的数据,一页显示不全,则需要分页显示
分页查询的sql命令请求数据库服务器->服务器响应查询到的多条数据->前台页面
语法:
select 查询列表
from 表1 别名
join 表2 别名
on 连接条件
where 筛选条件
group by 分组
having 分组后筛选
order by 排序列表
limit 起始条目索引,显示的条目数
执行顺序:
1.from子句
2.join子句
3.on子句
4.where子句
5.group by子句
6.having子句
7.select子句
8.order by子句
9.limit子句
特点:
1.起始条目索引如果不写,默认是0
2.limit后面支持两个参数
参数1:显示的起始条目索引
参数2:条目数
公式:
假如要显示的页数是page, 每页显示的条目数为size
select *
from employees
limit (page-1)*size, size
page size=10
1 limit 0,10
2 limit 10,10
3 limit 20,10
4 limit 30,10
*/
-- 案例1:查询员工信息表的前5条
select * from employees limit 0,5;
-- 完全等价于
select * from employees limit 5;
-- 案例2:查询有奖金的,且工资较高的第11名到第20名
select * from employees where commission_pct is not null order by salary desc limit 10,10;
1.12联合查询
-- 进阶9:联合查询
/*
说明:当查询结果来自于多张表,但多张表之间没有关联,这个时候往往使用联合查询,也称为union查询
说法:
select 查询列表 from 表1 where 筛选条件
union
select 查询列表 from 表2 where 筛选条件
特点:
1.多条待联合的查询语句的查询列数必须一致,查询类型、字段意义最好一致
2.union实现去重查询
union all实现全部查询,包含重复项
*/
-- 案例1:查询所有国家的年龄>20岁的用户信息
select * from chinese where age>20
union
select * from usa where uage>20;
-- 案例2:查询所有国家的用户姓名和年龄
-- 列数必须一致,不一致
-- select uname,uage from usa
-- union
-- select age, name from chinese;
-- 案例3:union自动去重/union all可以支持重复项
select 1, '范冰冰'
union
select 1, '范冰冰'
union
select 1, '范冰冰'
union
select 1, '范冰冰';
select 1, '范冰冰'
union all
select 1, '范冰冰'
union all
select 1, '范冰冰'
union all
select 1, '范冰冰';二、DDL语言
-- DDL语言
/*
说明:Data Define Language数据定义语言,用于对数据库和表的管理和操作
*/
-- 库的管理
-- 一、创建数据库
create database stuDB;
create database if not exists stuDB;
-- 二、删除数据库
drop database stuDB;
drop database if exists stuDB;
-- 表的管理
-- 一、创建表
/*
语法:
create table [if not exists] 表名(
字段名 字段类型 【字段约束】,
字段名 字段类型 【字段约束】,
字段名 字段类型 【字段约束】
);
*/
-- 案例:
create table if not exists stuinfo(
stuid int,
stuname varchar(20),
stugender char,
email varchar(20),
borndate datetime
);
desc stuinfo;
-- 数据类型:
-- 1.整型
tinyint smallint int bigint
-- 2.浮点型
float(m,n)
double(m,n)
decimal(m,n)
m和n可选
-- 3.字符型
char(n):n可选
varchar(n):n必选
-- text
n表示表示最多字符个数
-- 4.日期型
Date time datetime timestamp
-- 5.二进制型
blob 存储图片数据
-- 二、常见约束
说明:用于限制表中字段的数据的,从而进一步保证数据表的数据是一致的、准确的、可靠的
not null非空:用于限制该字段为必填项
default 默认:用于限制该字段没有显示插入值,则直接显示默认值
primary key主键:用于限制该字段值不能重复,设置为主键列的字段默认不能为空,一个表只能由一个主键,当然可以是组合主键
unique 唯一:用于限制该字段值不能重复
字段是否可以为空 一个表可以有几个
主键 不可以 1个
唯一 可以 n个
check 检查:用于限制该字段值必须满足指定条件 check(age between 1 and 100)
foreign key外键:用于限制两个表的关系,要求外键列的值必须来自于主表的关联列
要求:
1.主表的关联列和从表的关联列的类型必须一致,意思一样,名称无要求
2.主表的关联列要求必须是主键
-- 案例:添加约束
drop table if exists stuinfo;
create table if not exists stuinfo(
stuid int primary key, #添加了主键约束
stuname varchar(20) unique not null,#添加了唯一约束+非空
stugender char(1) default '男', #添加了默认约束
email varchar(20) not null,
age int check(age between 0 and 100),#添加了检查约束,mysql不支持
majorid int,
constraint fk_stuinfo_major foreign key (majorid) references major(id) #添加了外键约束
);
-- 二、修改表
语法:alter table 表名 add|modify|change|drop| column 字段名 字段类型 【字段约束】;
-- 1.修改表名
alter table stuinfo rename to students;
-- 2.添加字段
alter table students add column borndate timestamp not null;
desc students;
-- 3. 修改字段名
alter table students change column borndate birthday datetime null;
-- 4.修改字段类型
alter table students modify column birthday timestamp;
-- 5.删除字段
alter table students drop column birthday;
-- 三、删除表
drop table if exists students;
-- 四、复制表
-- 仅仅复制表的结构
create table newTable like major;
-- 复制表的结构+数据
create table newTable select * from girls.beauty;
-- 案例:复制employees表中的last_name,department_id,salary 字段到新表 emp表,但不复制数据
create table emp
select last_name,department_id, salary
from myemployees.employees where 1=2;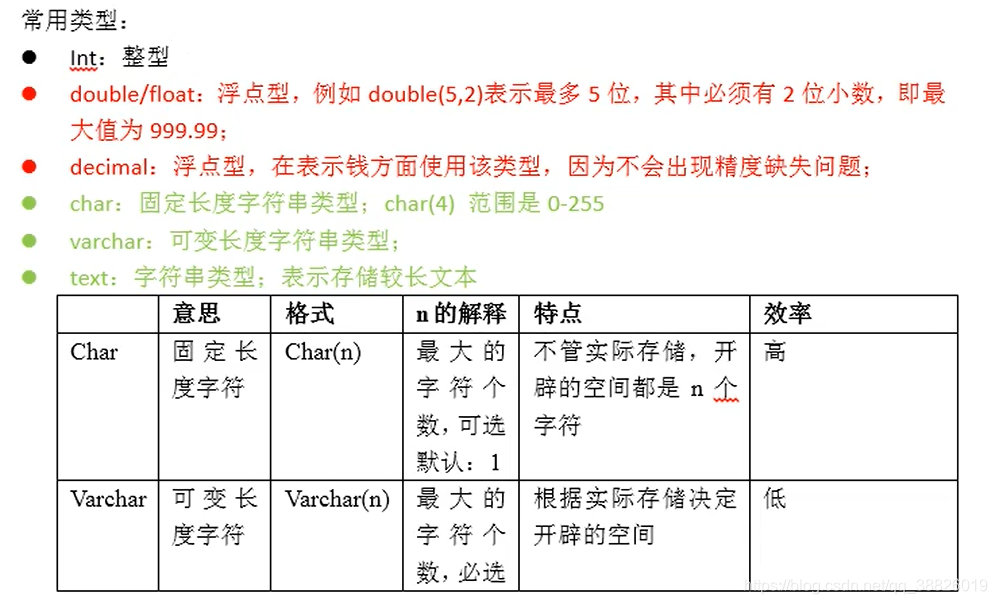

三、DML语言
-- DML
/*
DML(Data Manipulation Language)数据操纵语言:insert update delete
对表中的数据的增删改
*/
-- 一、数据的插入
/*
语法:
插入单行:
insert into 表名(字段名1, 字段名2, ...) values (值1, 值2, ...);
插入多行:
insert into 表名(字段名1, 字段名2, ...) values (值1, 值2, ...), (值1, 值2, ...), (值1, 值2, ...);
特点:
1.字段和值列表一一对应,包含类型、约束等必须匹配
2.数值型的值,不用单引号,非数值型的值,必须使用单引号
3.字段顺序无要求
*/
-- 案例1:要求字段和值列表一一对应,且遵循类型和约束的限制
insert into stuinfo(stuid, stuname, stugender, email, age, majorid) values (1, '吴倩', '男', '[email protected]', 12, 1);
-- 案例2:可以为空字段如何插入
insert into stuinfo(stuid, stuname, email, age, majorid) values (2, '齐秦', '[email protected]', 45, 1);
insert into stuinfo(stuid, stuname, stugender, email, age, majorid) values (2, '齐秦', null, '[email protected]', 45, 1);
-- 案例3:默认字段如何插入
-- 方案1:字段名写上,值使用default
insert into stuinfo(stuid, stuname, stugender, email, age, majorid) values (2, '齐秦', default, '[email protected]', 45, 1);
-- 方案2:字段名和值都不写
insert into stuinfo(stuid, stuname, email, age, majorid) values (2, '齐秦', '[email protected]', 45, 1);
-- 案例4:可以省略字段列表,默认所有字段
insert into stuinfo values (2, '齐秦', default, '[email protected]', 45, 1);
-- 二、设置主键自增长
/*
1.自增长列要求必须设置在一个键上,比如主键或唯一键
2.自增长列要求数据类型为数值型
3.一个表至多有一个自增长列
*/
create table gradeinfo(
gradeId int primary key auto_increment,
gradeName varchar(20)
);
insert into gradeinfo values(null, '一年级'), (null, '二年级'),(null, '三年级');
insert into gradeinfo (gradenName) values ('一年级'), ('二年级'), ('三年级');
-- 三、修改语句
/*
1.修改单表的记录
语法:
update 表名
set 列=新值,列=新值...
where 筛选条件;
2.修改多表的记录
sql92语法:
update 表1 别名,表2 别名 set 列= 值,... where 连接条件 and 筛选条件;
sql99语法:
update 表1 别名 inner|left|right join 表2 别名 on 连接条件 set 列=值,... where 筛选条件;
*/
-- 1.修改单表的记录
-- 案例1:修改beauty表中姓唐的女神的电话为1233432432
update beauty set phone = '123244343' where name like '唐%';
-- 案例2:修改boys表中id号为2的名称为张飞,魅力值10
update boys set boyname = '张飞', usercp=10 where id = 2;
-- 2.修改多表的记录
-- 案例1:修改张无忌的女朋友的手机号为112
update boys bo
inner join beauty b on bo.id = b.boyfriend_id
set b.phone = '112'
where bo.boyName='张无忌';
-- 案例2:修改没有男朋友的女神的男朋友编号都为2号
update boys bo
right join beauty b on bo.id = b.boyfriend_id
set b.boyfriend_id = 2
where b.id is null;
-- 三、数据的删除
/*
方式1:delete语句
语法:delete from 表名 where 筛选条件;
方式2:truncate语句
语法:truncate table 表名;
*/
-- 案例1:删除姓李所有信息
delete from stuinfo where stuname like '李%';
-- 案例2:删除表中所有数据
truncate table stuinfo;
-- 【面试题】delete和truncate的区别
1.delete可以添加where条件,truncate不能添加where条件,一次性清除所有数据
2.truncate的效率较高
3.如果删除带自增长列的表,使用delete删除后,重新插入数据,记录从断点处开始
使用truncate删除后,重新插入数据,记录从1开始
4.delete删除数据,会返回受影响的行数,truncate删除数据,不返回受影响的行数
5.delete删除数据,可以支持事务回滚,truncate删除数据,不支持事务回滚
四、事务
4.1 什么是事务

4.2 事务的四大特性(ACID)

4.3 MySql中的事务
-- 事务
/*
概念:由一条或多条sql语句组成,要么都成功,要么都失败
分类:
隐式事务:没有明显的开启和结束标记
比如dml语句的insert、update、delete语句本身就是一条事务
insert into stuinfo values(1,'john','男', '[email protected]', 12);
显示事务: 具有明显的开启和结束标记
一般由多条sql语句组成,必须具有明显的开启和结束标记
步骤:
取消隐式事务自动开启的功能
1.开启事务
2.编写事务需要的sql语句(1条或多条)
insert into stuinfo values(1,'john','男', '[email protected]', 12);
insert into stuinfo values(1,'john','男', '[email protected]', 12);
3.结束事务
*/
show variables like '%auto%';
-- 演示事务的使用步骤
-- 1.取消事务自动开启
set autocommit = 0;
-- 2.开启事务
start transaction;
-- 3.编写事务的sql语句
-- 将张三丰的钱-5000
update stuinfo set balance=balance-5000 where stuid = 1;
-- 将灭绝的钱+5000
update stuinfo set balance=balance+5000 where stuid = 2;
-- 4.结束事务
-- 提交
commit;
-- 回滚
rollback;
select * from stuinfo;4.4 JDBC中的事务操作
import org.junit.Test;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
/**
* 此类用于演示JDBC中的事务
* @author Jiang Akang
* @date 2021/2/28
*
* 使用步骤:
* 1.开启新事务
* 取消隐式事务自动提交的功能
* setAutoCommit(false);
*
* 2.编写组成事务的一组sql语句
*
* 3.结束事务、
* commit();提交
* rollback();回滚
*
* 细节:
* 要求开启事务的连接对象和获取命令的连接对象必须是同一个!否则事务无效
*
* 案例:转账案例
* 张三丰给灭绝转5000
**/
public class TestTransaction {
//不用事务
@Test
public void testNoTransaction() throws Exception{
//1.获取连接
Connection connection = JDBCUtils.getConnection();
//2.执行sql语句
PreparedStatement statement = connection.prepareStatement("update account set balance = ? where stuname=?");
//操作1: 张三丰的钱-5000
statement.setDouble(1, 5000);
statement.setString(2, "张三丰");
statement.executeUpdate();
int i = 1/0;//模拟异常
//操作2: 灭绝师太的钱+5000
statement.setDouble(1, 15000);
statement.setString(2, "灭绝师太");
statement.executeUpdate();
//3.释放资源
JDBCUtils.close(null, statement, connection);
}
//使用事务
@Test
public void testNoTransaction() {
Connection connection = null;
PreparedStatement statement = null;
try {
//1.获取连接
connection = JDBCUtils.getConnection();
//1)事务的使用步骤1: 开启事务
connection.setAutoCommit(false);
//2)事务的使用步骤2: 编写sql语句,并且执行
//2.执行sql语句
statement = connection.prepareStatement("update account set balance = ? where stuname=?");
//操作1: 张三丰的钱-5000
statement.setDouble(1, 5000);
statement.setString(2, "张三丰");
statement.executeUpdate();
int i = 1/0;//模拟异常
//操作2: 灭绝师太的钱+5000
statement.setDouble(1, 15000);
statement.setString(2, "灭绝师太");
statement.executeUpdate();
//3)事务的使用步骤3: 结束事务
connection.commit();
} catch (SQLException e) {
try {
//回滚事务
connection.rollback();
} catch (SQLException e1) {
e1.printStackTrace();
} finally {
//3.释放资源
JDBCUtils.close(null, statement, connection);
}
}
}
}