前言
因为一些原因,最近总有人问起mysql的一些问题,这个似乎成为检验程序员的技术的基本问题,今天就做个系统性的总结,留作以后复习,也分享给需要的同学。
索引是为了加速对表中数据行的检索而创建的一种分散存储的数据结构。索引好比是一本书的目录,加快数据库的查询速度。
索引的本质是数据结构,数据库中的索引存储在磁盘中。
1、怎么创建索引
sql创建语法
CREATE INDEX index_name ON table_name (column_list)要为列创建索引,要指定索引名称,索引所属的表以及列。
工具创建
这是基本的语法,平常使用的很少,我们大多都会使用各种可视化的工具,简单快捷。
我平常使用比较多的就是Navicat,不知道你在使用什么?

工具的产生是为了更快的更方便的解决问题。
2、mysql 的索引数据结构
这部分可能是这篇文章的重点了,我也希望能讲明白。
先来看下数据库的存储问题
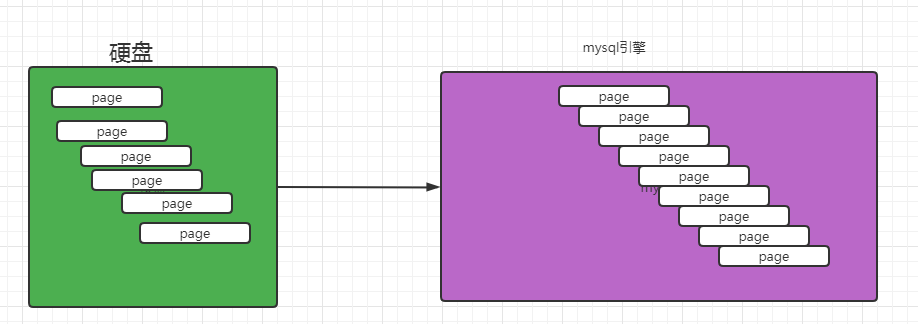
2.1 mysql 数据库的存储
页是mysql innodb存储的最基本结构,也是Innodb磁盘管理的最小单位。
mysql的文件系统在从硬盘加载数据的时候,会以页为单位进行加载,在内存中也是以页为单位进行调度。
在mysql中默认的page_size 是 16K
2.2 B+ 树的数据结构
B+ 树是mysql innodb 的索引数据结构,先看下数据的存储

注: 图来自百度搜索,侵权必删除
解释下上面这张图
蓝色的表示数据指针,也就是索引列的值,
红色的表示数据页的地址。
可以看到上面这张图除叶子节点(粉色框的)外存储的数据都是索引列的值
同时所有的叶子节点做了一个指针指向。
2.3 B+树的优点
1、所有叶子结点保存了实际的数据,同时做了指针关联,在做范围查询的时候,可以直接查询,节省查询效率
2、因为非叶子结点只存储索引数据,也就是索引指针,同时因为页大小是固定的,所以可以保持树的高度较低,在查询的时候可以快速的定位到数据页
3、聚簇索引和 非聚簇索引
聚簇索引:将数据存储和索引放到一起,可以简单的理解为主键索引,找到了索引也就找到了数据
非聚簇索引:叶子节点不存储数据,存储的是数据行地址,找到索引数据后要去主键那个索引里再次查询所需要的行数据,这个操作也叫作回表查询
3、mysql 索引为什么不使用B树
因为B树不好,为啥呢?
在B树中,每个节点都存储数据,这是和B+ 树的核心区别。
举个例子,如果定义了一张表,一个int 作为主键,一个varchar 作为数据列,假如行的数据是2K,
在使用B树的情况下,假如一页的大小16K,也就是一页只保存了8行数据,其中的下级指针只8个,这棵树得有多高啊,在查询的时候得从硬盘上读取多少页的数据才能定位到要查询的,效率太低了,不太合理。
如果使用B+树,索引页只存储索引,这个时候只有int 的数据存储,一页数据可以存储 16k/4字节,明显这棵树的层级更低,可以快速的定位到需要查询的数据,磁盘的IO次数更少,合理!
4、mysql 索引什么情况下会失效
mysql的索引失效是面试中经常问的,总结下
1.前导模糊查询不能利用索引(like '%XX'或者like '%XX%')
'A%'就可以正常使用索引
2.如果mysql评估使用全表扫描要比使用索引快,则不使用索引
3.OR前后存在非索引的列,索引失效
如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因)
要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
4.普通索引的不等于不会走索引
如果是主键,则还是会走索引;如果是主键或索引是整数类型,则还是会走索引
5.组合索引最左前缀
如果组合索引为:(name,email)
name and email -- 使用索引
name -- 使用索引
email -- 不使用索引
6.is null可以使用索引,is not null无法使用索引
最好在设计表时设置NOT NULL约束,比如将INT类型的默认值设为0,将字符串默认值设为''。
7.计算、函数导致索引失效另外一种情况
5、mysql 什么情况下不适合建立索引
1.查询用不到的字段不需要创建索引。
2.数据量小的表最好不要使用索引
如果表中记录太少,比如少于1000个,那么是不需要创建索引的。表记录太少,是否创建索引对查询效率的影响并不大。
3.有大量重复数据的列上不要建立索引
在条件表达式中经常用到的不同值较多的列上建立索引,但字段中如果有大量重复数据,也不用创建索引。比如在学生表中的性别字段上只有男和女两个不同的值,因此无须建立索引。如果建立索引,不但不会提高查询效率,反而会严重降低数据更新速度。
索引的价值是帮你快速定位。如果想要定位的数据有很多,那么索引就失去了它的使用价值,比如通常情况下的性别字段。
说明:当数据重复度大,比如高于10%的时候,也不需要对这个字段使用索引
4.避免对经常更新的表创建过多的索引
①频繁更新的字段不一定要创建索引。因为更新数据的时候,也需要更新索引,如果索引太多,在更新索引的时候会造成负担,从而影响效率。
②避免对经常更新的表创建过多的索引,并且索引中的列尽可能少。此时,虽然提高了查询速度,同时却会降低更新 表的速度。
5.不建议使用无序的值作为索引
例如身份证、uuid(在索引比较时需要转为ASCII,并且插入时可能会造成页分裂,这些了解即可)、md5、hash、无序字符串等。
6.删除不再使用或者很少使用的索引
表中的数据被大量更新或者数据的使用方式被改变后原有的一些索引可能不再需要。数据库管理员应该定期找出这些索引,将他们删除,从而减少索引对更新操作的影响。
7.不要定义冗余或者重复的索引
6、索引的删除
这个单独拉出来是因为索引的删除也是面试常问的,
如果一个表的数据很多,要删除其中的大部分数据的时候,需要先删除索引,
因为的删除的过程中索引会一直重建变动,会消耗过多的时间。
如果删除的数据过多,可以先删除索引,待删除的数据完成后,再重新创建索引。
总结
好久没写文章了,有点不想写,稍微总结下