一.从京东抓取一些婴儿奶粉的相关商品,格式如1.1:
1.1
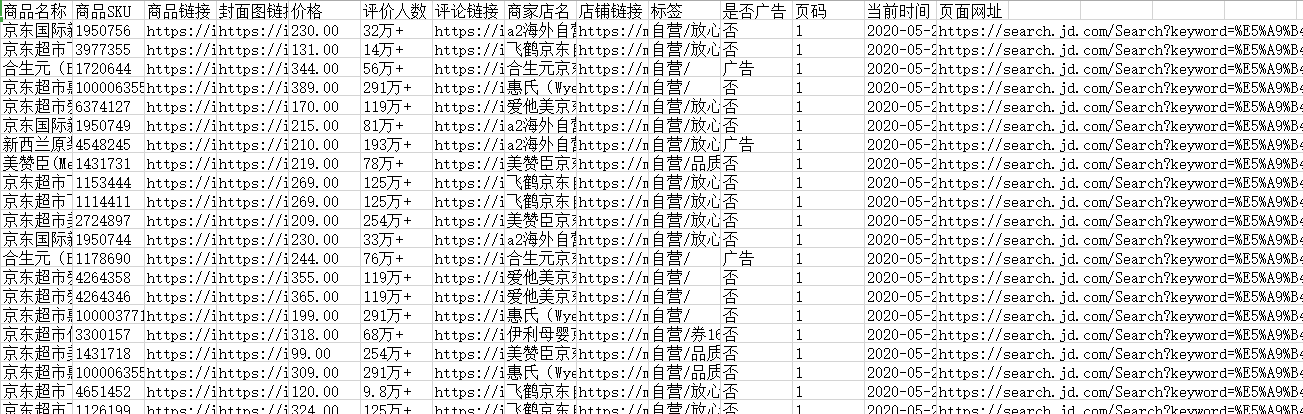
1.2主要字段有:
商品名称,1
商品sku,2
商品链接,3
封面图链接,4
价格,5
评价人数,6
评论链接,7
商家店名,8
店铺链接,9
标签,10
是否广告,11
页码,12
当前时间,13
页面网址,14
二.数据处理
2.1需要的字段有:
品牌名、奶粉的段位、重量、店铺名、店铺url、商品url、商品价格、商品评论人数,其中前3个字段可以从商品的标题中提取。但有个问题,关于奶粉的品牌名如果使用实体识别就需要相关奶粉品牌的语料进行训练后提取。这里只简单的提前搜集好各种奶粉品牌名,如发现商品标题中有此品牌则认为该商品属于此品牌奶粉。奶粉的段位和重量(包括有几罐)可以简单的利用规则提取,其它的字段在抓取中可获得。
2.2处理结果为json格式:
{"product_weight": "900克", "product_price": 230.0, "product_name": "a2", "product_url": "https://item.jd.com/1950756.html", "shop_name": "a2海外自营官方旗舰店", "shope_url": "https://mall.jd.com/index-1000015026.html?from=pc", "product_stage": "1段", "product_comment_num": "32万+"}
{"product_weight": "300克", "product_price": 131.0, "product_name": "飞鹤", "product_url": "https://item.jd.com/3977355.html", "shop_name": "飞鹤京东自营旗舰店", "shope_url": "https://mall.jd.com/index-1000003568.html?from=pc", "product_stage": "1段", "product_comment_num": "14万+"}
{"product_weight": "900克", "product_price": 389.0, "product_name": "启赋", "product_url": "https://item.jd.com/100006355540.html", "shop_name": "惠氏(Wyeth)京东自营官方旗舰店", "shope_url": "https://mall.jd.com/index-1000002520.html?from=pc", "product_stage": "1段", "product_comment_num": "291万+"}
{"product_weight": "380克", "product_price": 170.0, "product_name": "爱他美", "product_url": "https://item.jd.com/6374127.html", "shop_name": "爱他美京东自营官方旗舰店", "shope_url": "https://mall.jd.com/index-1000002668.html?from=pc", "product_stage": "1段", "product_comment_num": "119万+"}
{"product_weight": "900克", "product_price": 215.0, "product_name": "a2", "product_url": "https://item.jd.com/1950749.html", "shop_name": "a2海外自营官方旗舰店", "shope_url": "https://mall.jd.com/index-1000015026.html?from=pc", "product_stage": "3段", "product_comment_num": "81万+"}
2.3以下为处理程序示例:
#读取数据并保存为json格式输出保存 def read_babymilk_info(file_path, baby_milk_name_set, json_to_write_path): df = pd.read_excel(file_path) df.drop_duplicates(['商品SKU'], keep='first', inplace=True) # 去重 df = df[df['是否广告'] != '广告'] #删除广告数据 df = df.iloc[:,[1,3,5,6,8,9]] product_name = None #商品名 product_title = None #商品标题描述 product_stage = None #几段 product_weight = None #重量 product_num = None #几罐 product_url = None #商品链接 product_price = None #商品价格 product_comment_num = None #商品评论人数 shop_name = None #店铺名 shope_url = None #店铺url write_lines = 0 with open(json_to_write_path, 'w', encoding='utf-8') as f_write: for index, row in df.iterrows(): product_dict = dict() #处理商品标题 product_title = repr(row[0]).strip().replace('\\t','').replace('\\n',' ') product_title = product_title.lower()#有字母转小写 for milk_name in baby_milk_name_set: if milk_name in product_title: product_name = milk_name break #pattern = re.compile('r[0-9]') if '段' in product_title: posi = product_title.find('段') stage = product_title[posi - 1:posi] if stage.isdigit(): product_stage = stage + '段' if 'g' in product_title: posi = product_title.find('g') weight = product_title[posi - 3:posi] if weight.isdigit(): product_weight = weight + '克' elif'克' in product_title: posi = product_title.find('克') weight = product_title[posi - 3:posi] if weight.isdigit(): product_weight = weight + '克' if '*' in product_title: posi = product_title.find('*') num = product_title[posi+1:posi+3] if num.isdigit(): product_num = '*' + num else: num = product_title[posi+1:posi+2] if num.isdigit(): product_num = '*' + num if product_num != None: product_weight = product_weight + product_num product_num = None product_url = row[1] product_price = row[2] product_comment_num = row[3] shop_name = row[4] shope_url = row[5].strip() product_dict['product_name'] = product_name product_dict['product_stage'] = product_stage product_dict['product_weight'] = product_weight product_dict['product_url'] = product_url product_dict['product_price'] = product_price product_dict['product_comment_num'] = product_comment_num product_dict['shop_name'] = shop_name product_dict['shope_url'] = shope_url json_str = json.dumps(product_dict,ensure_ascii=False) f_write.write(json_str + '\n') write_lines += 1 print('write line:{}'.format(write_lines)) print('write done!')
三.利用neo4j,py2neo构建图谱
3.1利用2.2中的json数据直接构建节点和关系:
扫描二维码关注公众号,回复:
11274947 查看本文章

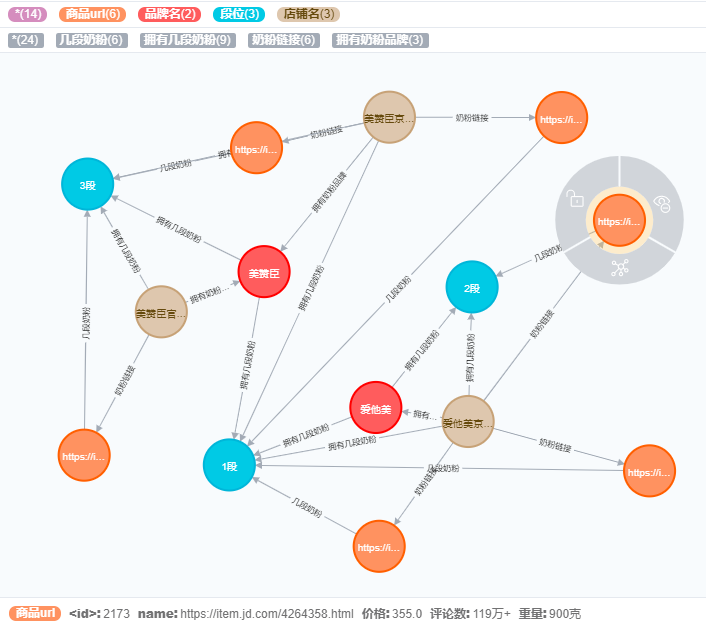
4个节点:店铺、品牌、段位以及商品url
5个关系:(店铺,拥有奶粉品牌,品牌),(店铺,拥有几段奶粉,段位),(店铺,奶粉链接,商品url),(品牌,拥有几段奶粉,段位),(商品url,几段奶粉,段位)
其中,节点商品url拥有属性价格,评论数,重量
3.2拥有2个品牌和3个店铺的图谱如下:
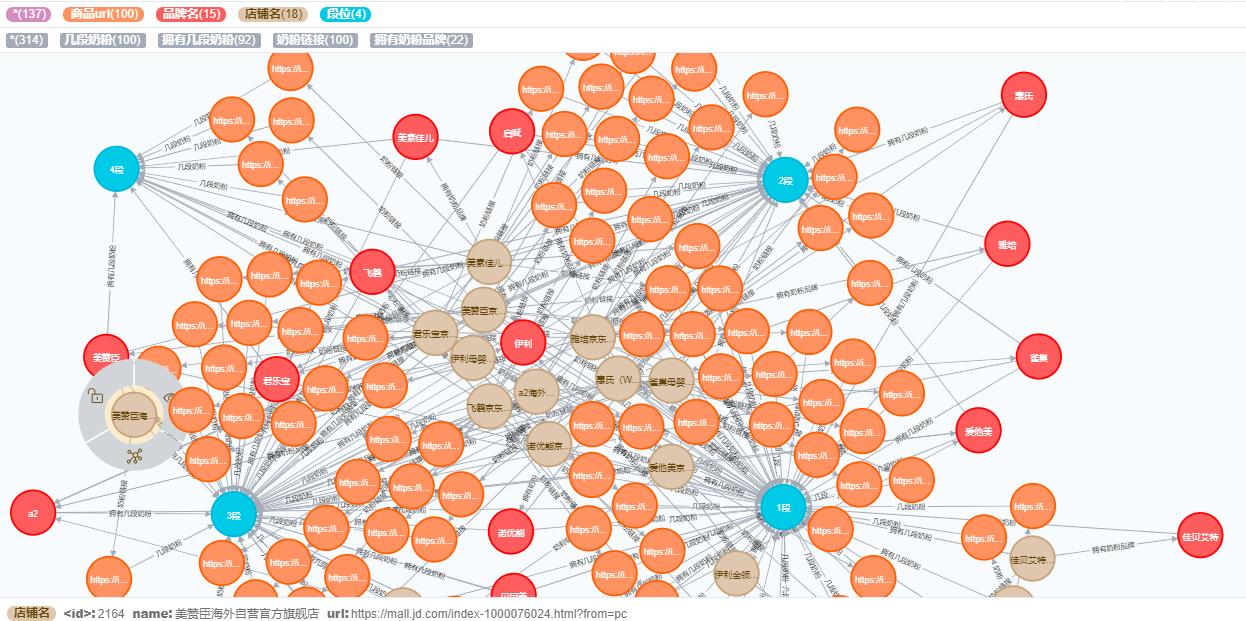
3.3拥有15个品牌和18个店铺的图谱如下:
3.3以下为图谱构建程序示例:
def build_graph(graph, json_data_path): line_count = 0 with open(json_data_path, 'r', encoding='utf-8') as f_read: for line in f_read: product_dict = json.loads(line) product_name = product_dict['product_name'] product_stage = product_dict['product_stage'] product_weight = product_dict['product_weight'] product_url = product_dict['product_url'] product_price = product_dict['product_price'] product_comment_num = product_dict['product_comment_num'] shop_name = product_dict['shop_name'] shop_url = product_dict['shope_url'] #节点 shop_name_node = Node('店铺名', name = shop_name, url = shop_url) product_stage_node = Node('段位', name = product_stage) product_name_node = Node('品牌名', name = product_name) product_url_node = Node('商品url', name = product_url, 价格 = product_price, 重量 = product_weight, 评论数 = product_comment_num) subgraph_begin = graph.begin() nodes = [] node_matcher = NodeMatcher(graph) if not node_matcher.match('店铺名', name=shop_name).first(): nodes.append(shop_name_node) if not node_matcher.match('段位', name=product_stage).first(): nodes.append(product_stage_node) if not node_matcher.match('品牌名', name=product_name).first(): nodes.append(product_name_node) if not node_matcher.match('商品url', name=product_url).first(): nodes.append(product_url_node) nodes = Subgraph(nodes) subgraph_begin.create(nodes) subgraph_begin.commit() relations = [] #关系 shop_name_node = node_matcher.match('店铺名', name=shop_name).first() product_stage_node = node_matcher.match('段位', name=product_stage).first() product_name_node = node_matcher.match('品牌名', name=product_name).first() product_url_node = node_matcher.match('商品url', name=product_url).first() rel_1 = Relationship(shop_name_node, '拥有奶粉品牌', product_name_node) rel_2 = Relationship(shop_name_node, '拥有几段奶粉', product_stage_node) rel_3 = Relationship(shop_name_node, '奶粉链接', product_url_node) rel_4 = Relationship(product_name_node, '拥有几段奶粉', product_stage_node) rel_5 = Relationship(product_url_node, '几段奶粉', product_stage_node) relations.append(rel_1) relations.append(rel_2) relations.append(rel_3) relations.append(rel_4) relations.append(rel_5) for relation in relations: graph.create(relation) line_count += 1 print('line_count:{} completed!'.format(line_count)) print('build graph done!')