文章目录
信息论是现代世界非常重要的一种观念,你肯定听过“
比特”、“
信息熵”之类的词,这些概念似乎都比较技术化。那不搞技术的人也需要了解吗?答案是非常需要。在我看来,信息论并不仅仅是技术理论,更是一种具有普世价值的思想。了解信息论,你就多了一种观察世界的眼光。甚至可以从信息论中推导出一种人生观来。——万维钢《你有你的计划,世界另有计划》
一、信息与冗余
先来看两条“消息“”:
(1)怎想再很,末第铎制释能锁其那策铜怎亚,狄幺潢互梯是日方通的。
(2)对这些村民来说,星期天是休息的日子,至少不需要到田地里干活。
第一条消息是我胡乱打出来的,第二条则是2017年获得诺贝尔文学奖的石黑一雄的小说《被掩埋的巨人》中的一句话。请问,哪条消息的“信息量"更大?
从直觉上来说,第二条的信息量更大,因为它至少是一条信息,面第一条则完全是乱码。但第二条消息只不过是看起来更有意义而已——信息量更大的其实是第一条。第二条消息中有很多多余的字,即便把有些字去掉,留下空白,你也能猜到它们是什么字。比如说:
“星期__ 是休 __ 的日 __。” 你一看就能猜到这句话是“星期天是休息的日子”。这就是说,第二条消息是可压缩的。
而第一条消息则不同,拿掉任何一个字,你都猜不出它是哪个字。这是一条不可压缩的信息。至于这条消息有没有意义,那是另一回事。也许它是一个密码,也许它是一些人名和地名的组合,但关键在于,你无法省略其中任何一个字。
也就是说,一段消息所包含的信息量,并不仅仅由这条消息的长短决定。这就好像人生一样,活了同样岁数的两个人,他们人生经历的丰富程度可能大不相同。
如果信息量不由其长短决定,那我们该如何衡量它呢?
二、香农的洞见
上述例子中的两条消息,有些字是多余的,它们并不提供新信息;有些字虽然不算多余,但拿掉了我们也能猜出个八九不离十,它们提供的信息量比较小。比如:“至少不需要到田地里干__。”
最后空格这个字是什么?汉语中以“干”开头的词并不多,适合放在这里的无非是“干活”、 “干事” 、“干仗”等。现在我告诉你这个字是“活”,你肯定不会感到惊讶——所以“活”这个字提供的信息量很小。
现代信息论的祖师爷克劳德·香农有一个洞见:一个东西信息量的大小,取决于它克服了多少不确定性。
举个生活中的例子。有个人生活非常规律,平时会去的就是家里、公司、餐馆、健身房这四个地方。如果我雇你做特工,帮我观察这个人,随时向我汇报他的位置。那你每次给我的信息无非就是“家里/公司/餐馆/健身房”中的一个——即使你不告诉我,我猜对的概率也有 。所以你给我的信息价值不大。
但如果这个人满世界跑,今天在土耳其,明天在沙特阿拉伯,我完全猜不到他在哪里,你给我的信息可就非常值钱了。你提供信息之前。这个人的位置对我来说具有不确定性。你的信息,克服了这个不确定性。原来的不确定性越大,你的信息就越有价值。
我们用一个简单的公式来量化这个思想。
三、信息熵计算公式
香农从统计物理学中借鉴了一个概念——信息熵。这个概念看起来吓人,其实很简单,就是一段消息的平均信息量。一个东西信息量的大小,取决于它克服了多大的不确定性。香农对信息量的定义是,如果一个字符出现在这个位置的概率是 ,那么这个字符的信息量就是 。
香浓举例说。假如我们有一个完美公正的硬币,每次抛出正面朝上的概率都是 ,如果这一次抛出的结果是正面朝上,这个消息的信息量就是 。而信息熵,就是把一条消息中出现的所有字符做信息量的加权平均。
还是用硬币的例子, 表示正面朝上, 表示反面朝上。一系列投掷结果可能是: 。如果正反面出现的概率都正好是 ,那么这一串消息不管多长,信息熵都是 , 香农规定信息量的单位是“比特”,这个信息熵就是 比特。这意味着,对消息中的每个字符,至少需要 比特的信息才能编码。
如果这个硬币“不公平”,出现 的次数比出现 更多,比如 ,那么信息熵就不是 比特了。在这个例子中, 出现的概率是 , 出现的概率是 ,信息熵就变成了 比特。
信息熵跟消息的长度没有必然关系,它表示的是这段消息中字符的“不可预测性”。一段字符中出现的各种字符越是杂乱无章,越具有多样性,信息熵就越高。比如这样一个字符串—— 。每个字母都不一样,它的信息熵是 比特。而如果字符串中有很多重复的字母,那它的“可预测性”就很高,信息商就会变低,比如字符串“ ”的信息熵只有 比特。
信息熵 =
这里为了简化,计算时只考虑了字符出现的频率,如果从语法和内容角度进一步考虑,每个字符的可预测性,信息熵就是另一种个数值了。
信息之所以叫“熵”,是因为它跟统计物理学中熵的公式几乎一样,物理学里“熵”大致描述了一个系统的混乱程度——信息熵也是如此。越是看上去杂乱无章的消息,信息熵就越高,信息量就越大。
如果一段消息只能从
和
两个数字中选,它的信息熵最大也只有
比特;如果能从
个字母中选,信息熵最大可以达到
比特。
如果是从
个汉字中选,信息熵则可以达到
比特。
这就是为什么中文是一种更高效的语言。
你如果没有看懂上述数学部分不要紧,只要记住一句话:可供选择的范围越广,选择的信息量就越大。
四、编程计算信息熵
(一)编程计算上文涉及的信息熵
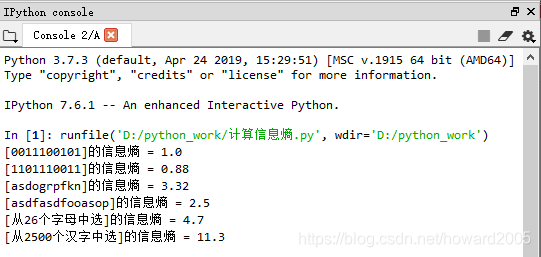
- 编写程序“计算信息熵.py”
"""
计算信息熵
"""
from math import *
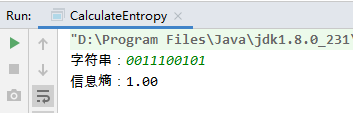
s = "0011100101"
e = -(0.5 * log(0.5, 2) + 0.5 * log(0.5, 2))
print("[{}]的信息熵 = {}".format(s, e))
s = "1101110011"
e = -(0.3 * log(0.3, 2) + 0.7 * log(0.7, 2))
print("[{}]的信息熵 = {}".format(s, round(e, 2)))
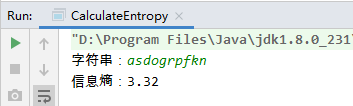
s = "asdogrpfkn"
e = 0
for i in range(10):
e = e - 0.1 * log(0.1, 2)
print("[{}]的信息熵 = {}".format(s, round(e, 2)))
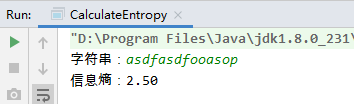
s = "asdfasdfooasop"
pa = 3 / 14
ps = 3 / 14
pd = 2 / 14
pf = 2 / 14
po = 3 / 14
pp = 1 / 14
e = -(pa * log(pa, 2) + ps * log(ps, 2) + pd * log(pd, 2) + pf * log(pf, 2) + po * log(po, 2) + pp * log(pp, 2))
print("[{}]的信息熵 = {}".format(s, round(e, 2)))
# 从26个字母中选的信息熵
e = 0
for i in range(26):
e = e - 1 / 26 * log(1 / 26, 2)
print("[从26个字母中选]的信息熵 = {}".format(round(e, 2)))
# 从2500个汉字中选的信息熵
e = 0
for i in range(2500):
e = e - 1 / 2500 * log(1 / 2500, 2)
print("[从2500个汉字中选]的信息熵 = {}".format(round(e, 1)))
- 运行程序,查看结果
(二)编写Python函数计算字符串的信息熵
1、编写程序“计算字符串的信息熵.py”
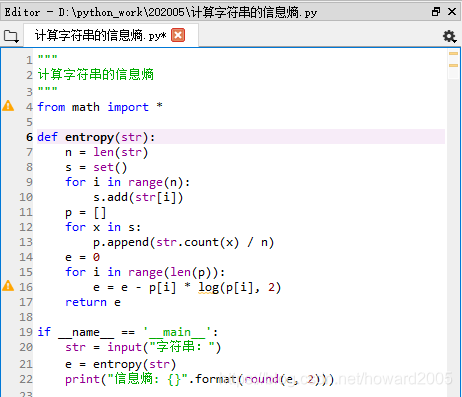
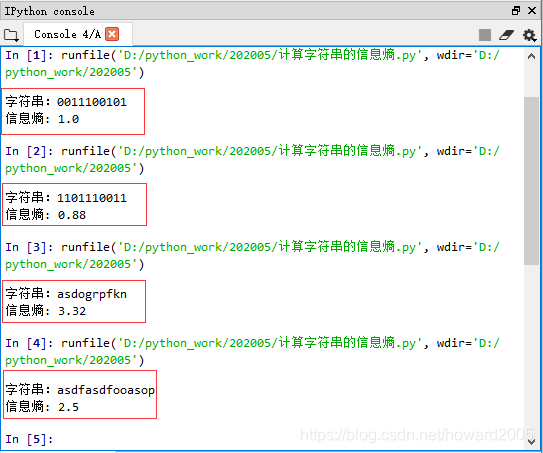
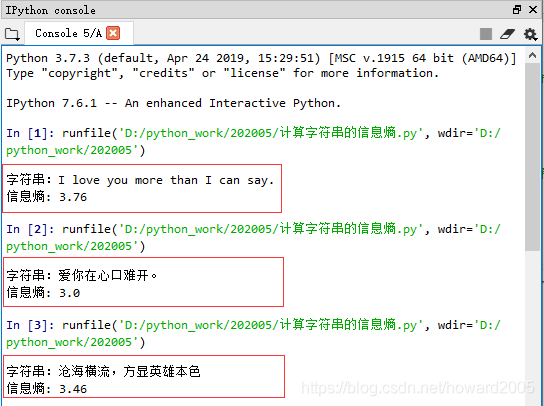
2、运行程序,查看结果
(三)编写Java方法计算字符串的信息熵
1、创建CalculateEntropy类
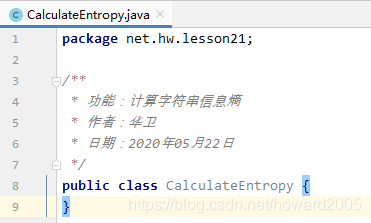
本程序涉及到Java里的HashSet和ArrayList集合。具体使用方法,可以参看《Java讲课笔记21:List接口及其实现类》与《Java讲课笔记22:Set接口及其实现类》。
package net.hw.lesson21;
import java.util.*;
/**
* 功能:计算字符串信息熵
* 作者:华卫
* 日期:2020年05月22日
*/
public class CalculateEntropy {
public static double entropy(String str) {
int n = str.length();
Set<String> set = new HashSet<>();
for (int i = 0; i < n; i++) {
set.add(String.valueOf(str.charAt(i)));
}
List<Double> p = new ArrayList<>();
for (String x : set) {
int count = 0;
for (int i = 0; i < n; i++) {
if (x.equalsIgnoreCase(String.valueOf(str.charAt(i)))) {
count++;
}
}
p.add(count * 1.0 / n);
}
Double e = 0.0;
for (int i = 0; i < p.size(); i++) {
e = e - p.get(i) * Math.log(p.get(i)) / Math.log(2);
}
return e.doubleValue();
}
public static void main(String[] args) {
String str;
double e;
Scanner sc = new Scanner(System.in);
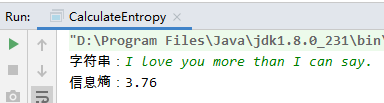
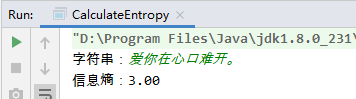
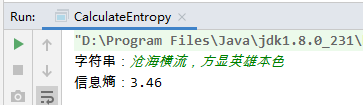
System.out.print("字符串:");
str = sc.nextLine();
e = entropy(str);
System.out.println("信息熵:" + String.format("%.2f",e));
}
}
2、运行程序,查看结果

五、信息论的价值观
信息,在于你从多大的不确定性中做出了选择;信息,在于你制造了多少意外;信息,在于你有多大的自由度。比如,有个人每天都按时上班,从不迟到。他今天来上班了,请问这是新闻吗?当然不是。这个消息的信息量等于0。而另外一个人,想上班就上班,想不上就不上,他今天来上班了,这才是新闻。第二个人比第一个人拥有更多自由。
我们每个人都希望度过值得回忆的一生,最好还是“值得记录”的一生。值得记录,不就是提供了有效的信息吗?从信息角度来讲,人生就是要活一个“选择权”。如果你从来都是按部就班,不敢越雷池半步地生活,干什么都是高度可预测的,那你的人生就不值得记录。而如果你的生活跌宕起伏,充满意外,就值得记录。甚至值得出自传、拍电视剧。
比如,上级交给你一个任务,非常明确地告诉你,第一步干什么、第二步干什么、到什么地方、找什么人接洽、话术是什么。如果你只能完全按照这个剧本执行任务,请问你贡献了什么信息呢?没有。你没有自由度。反过来说,如果你有能力不按剧本走,敢给自己加戏,在关键时刻有选择权,你做的事让围观群众感到很意外。这才算是留下了信息。
信息论的价值观是要求选择权、多样性、不确定性和自由度。我们不只想老老实实地活着,我们还想活出“信息”来。我们想在这个世界上留下自己的痕迹。
这就是香农关于信息的第一个洞见:一个东西真正的信息量,在于它克服了多大的不确定性。这个洞见给我们提供了一种观察世界的眼光。有了这种眼光,你再看身边的很多东西,其实都没什么信息量。
六、怎么把信息量最大化
先看一个香农本人设计的例子,有这样一句英文:Most people have little difficulty in reading this sentence.

香农说,这句话中有很多冗余(redundant)的字符。就算把其中所有的元音字母都去掉,如果你英文比较熟练,也能猜出这句话是什么:Mst ppl hv lttl dffclty n rdng ths sntnc.
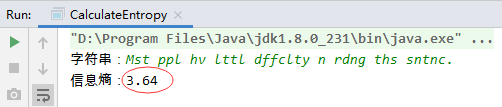
第二句话能够表达同样的意思,和第一句相比,它的信息密集度显然更大,据我所知,有些古代文明的文字就根本没有元音字母,让你自己猜。这个去除一句话中的冗余字符的过程,就是“压缩(compress)"。这句话还可以进一步压缩,比如其中的介词(in)和指示代词(this),就算没有你也知道是什么意思。我们中国的文言文,大约就是一种高度压缩的文体,言简意赅,特别省竹简。
香农认为英语是一种冗余度非常高的语言,一般英文文本75%的字符都是多余的。前面我们说了,汉字的信息熵比英文字母高很多,所以同样长度的一句中文和英文,中文的信息量就会大出许多。

同样的一本书,如果翻译成中文,就会比英文书薄出许多。最高效的文本应该像乱码一样,让你找不到任何规律。
非常可惜的是,信息革命真正开始改变世界的时候,香农已经得了老年痴呆症。香农年轻的时代,他的理论并没有得到很好的应用,当时所谓的通讯无非也就是发发电报、打打电话,字符压缩不压缩的意义不大。等到互联网普及之后,音频和视频的压缩可就太关键了,没有压缩算法我们就不可能在计算机上听音乐和看电影。香农没有发明具体的压缩算法,但是所有压缩算法都用到了香农的观念。
如果压缩是高效传播信息的办法,那我们平时说话为什么不尽量压缩一下,为什么容忍那么大的语言冗余度呢?首要的原因是有噪声。
七、克服噪声的正确方法
在香农发表信息论之前,困扰贝尔实验室科学家的一个问题是怎么克服通讯过程中的噪声。一段电码在传送过程中,噪声可能会把原本的0变成1,把1变成0。一开始人们的想法都是把信号放大,让信号的强度远远高于噪声——但这其实是个闪徒困境!因为如果每条通讯都扯着嗓子喊,声音是越来越大了,但是互相之间的干扰也越来越强,彼此都是对方的噪声,信号越强,噪声也越强。
香农的第二个洞见就是,克服噪声的正确办法,是增加信息的冗余度。
举一个最简单的例子。假设我们要传递的消息都是由ABCD四个字母组成的,而我们传递的方式是用0和1两个数字对这四个字母编码的。最高效的编码方式,是两个数字对应一个字母,比如:A = 00 B = 01 C = 10 D = 11
根据这个编码, “000110"就是"ABC”,简单明了。但是这个编码系统有危险,因为如果传递过程中有噪声,把其中第二个0变成了1,那整个信息就成了"010110",消息就变成"BBC"了!
怎么解决这个问题呢?香农说,应该给编码增加一些冗余度。比如可以用五个数字代表一个字母:A = 00000 B = 00111 C = 11100 D = 11011
这样一来,哪怕传播过程中出了错,当你看到"00001"这样的非法编码时,也能立即猜到它是A。
想想这个道理。我们日常说话不就是这样吗?我们的话都有很大的冗余度,有时候啰里啰嗦,一个意思说好几遍,但是这样能确保你即便有几个字没有听清楚,也能知道我说的是什么意思。
后世所有的信息编码系统都要考虑到出错和纠错问题,基本原理正是香农说的增加冗余度。所以说,想要让别人充分理解你的意思,最好的办法不是用更大的声音对着他喊,而是多给他说几遍。(怪不得,重要的事情说三遍,o( ̄︶ ̄)o)
八、可预测与不可预测
信息的本质是克服了多少不确定性,也就是不可预测。而冗余度的本质恰是提高可预测性。
那么从信息论角度,我们的人生面临一个矛盾:一方面你希望自己活得更有效率,能给世界留下更多信息,做事要有创造性,越不可预测越好;另一方面,你又要跟人好好交流,要增加冗余度,给别人一个合理的预期,让人觉得你是可预测的,这样才能形成合作。如果一个人连上一次班都是新闻,那就太不靠谱了。
既要有创造性,又要可预测,这才是合理的信息输出。比如说写文章,如果你的观点非常新颖,语言又特别简练,那信息量就太大,别人很可能难以理解。而如果你文章中的道理很少,车轱辘话却说了很多,那也不行。信息量到底要多少才好,这是一门艺术,你得慢慢摸索。在我看来,增加文字冗余度的唯一好处就是方便别人接收,只要读者能理解、能记住,信息就应该越密集越好。
反过来说,读书则是一个接收信息的问题。现在有各种关于“速读”的方法,而从信息论的角度看,阅读速度并不是由眼球转动的速度决定的。接受一段信息速度的快慢,取决于这段信息对我们来说,在多大程度上是可预测的。如果作者说上半句你就知道下半句,作者说一个典故的并头你就知道结局,那么这本书显然就可以读得非常快。而如果这本书的内容对你来说是全新的,读到哪一段都一惊一乍,那你就只能慢慢细读。所以一个人读书速度的快慢,从根本上来说,取决于这个人以前读过多少书。对一个领域了解越多,读这个领域的新书就越快。小说看多了,再看新小说就觉得到处都是俗套。如此说来,阅读的过程其实是读者和作者之间的一场较量。作者使出各种手段让读者预测不到他下一步要说什么,而读者一旦预测成功,就会有一种战胜了作者的感觉。
再进一步,我们还可以从接收信息和输出信息这个视角审视一下人生。
我们平时学习知识、积累经验,就是要减少世界给自己的不确定性。新人看哪里都新鲜,老手看哪里都俗套——只有这样,我们才能从一大推可预测的事物之中敏感地抓住那些不寻常之处,那才是真正有价值的信息。
而我们做事,则要给世界增加一点不确定性。别人都以为我会这么做,然后我就真的这么做了,那我跟一台机器有什么区别?我要输出信息,就得做一些别人想不到我会做的事。
信息就是意外。从“信息论”这个维度出发,有两种事情是特别值得我们去做的:
(1)出乎别人意料的事
(2)给自己增加选项的事
做事出事意料,你做的这件事才值得被记住。有更多的选项,你才有能力做出乎意料的事。有选择权的人也可能故意做一些可预测的事来促进交流和合作——但只要你真的拥有选择权,不管你是选了A还是选了B,就都是真的信息。选项 = 自由度。
你可能会说,难道我们做事不应该多做好事少做坏事吗?为了出乎意料而去做一些损人不利己的事,这也行吗?当然不行,但是请注意,我们这里说的仅仅是信息论这一个维度。人生有很多维度,好人坏人是另一个维度。一个恪尽职守的保安在公司站了3年岗,他做的事很对、也很好,但是不值得记录。一个不负责任的医生违反操作规程把病人治死了,他做的事很坏,但是值得记录下来。当然,并不是所有人都想给这个世界留下信息。我们这里说的是如果你想留下信息,你应该怎么做。
最后,我想引用电影《辛德勒的名单》 ( Schindler’s List)里的一句台词。这句话大意是说,按照规定去杀人,那不能算你有权力,你并不真的掌握别人的命运。什么叫权力?(“权力是我们有充分的理由去杀一个 人,但是我们不杀。”)
